 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShortcut-V2V: Compression Framework for Video-to-Video Translation based on Temporal Redundancy Reduction
Aug 15, 2023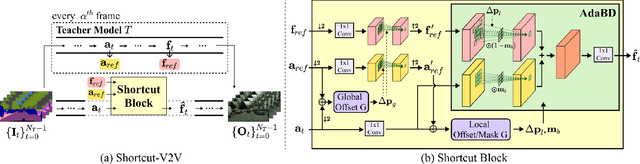



Video-to-video translation aims to generate video frames of a target domain from an input video. Despite its usefulness, the existing networks require enormous computations, necessitating their model compression for wide use. While there exist compression methods that improve computational efficiency in various image/video tasks, a generally-applicable compression method for video-to-video translation has not been studied much. In response, we present Shortcut-V2V, a general-purpose compression framework for video-to-video translation. Shourcut-V2V avoids full inference for every neighboring video frame by approximating the intermediate features of a current frame from those of the previous frame. Moreover, in our framework, a newly-proposed block called AdaBD adaptively blends and deforms features of neighboring frames, which makes more accurate predictions of the intermediate features possible. We conduct quantitative and qualitative evaluations using well-known video-to-video translation models on various tasks to demonstrate the general applicability of our framework. The results show that Shourcut-V2V achieves comparable performance compared to the original video-to-video translation model while saving 3.2-5.7x computational cost and 7.8-44x memory at test time.
Guiding Users to Where to Give Color Hints for Efficient Interactive Sketch Colorization via Unsupervised Region Prioritization
Oct 25, 2022



Existing deep interactive colorization models have focused on ways to utilize various types of interactions, such as point-wise color hints, scribbles, or natural-language texts, as methods to reflect a user's intent at runtime. However, another approach, which actively informs the user of the most effective regions to give hints for sketch image colorization, has been under-explored. This paper proposes a novel model-guided deep interactive colorization framework that reduces the required amount of user interactions, by prioritizing the regions in a colorization model. Our method, called GuidingPainter, prioritizes these regions where the model most needs a color hint, rather than just relying on the user's manual decision on where to give a color hint. In our extensive experiments, we show that our approach outperforms existing interactive colorization methods in terms of the conventional metrics, such as PSNR and FID, and reduces required amount of interactions.