 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimodo: Scaling Controllable Human Motion Generation
Mar 16, 2026High-quality human motion data is becoming increasingly important for applications in robotics, simulation, and entertainment. Recent generative models offer a potential data source, enabling human motion synthesis through intuitive inputs like text prompts or kinematic constraints on poses. However, the small scale of public mocap datasets has limited the motion quality, control accuracy, and generalization of these models. In this work, we introduce Kimodo, an expressive and controllable kinematic motion diffusion model trained on 700 hours of optical motion capture data. Our model generates high-quality motions while being easily controlled through text and a comprehensive suite of kinematic constraints including full-body keyframes, sparse joint positions/rotations, 2D waypoints, and dense 2D paths. This is enabled through a carefully designed motion representation and two-stage denoiser architecture that decomposes root and body prediction to minimize motion artifacts while allowing for flexible constraint conditioning. Experiments on the large-scale mocap dataset justify key design decisions and analyze how the scaling of dataset size and model size affect performance.
Fair Generation without Unfair Distortions: Debiasing Text-to-Image Generation with Entanglement-Free Attention
Jun 16, 2025



Recent advancements in diffusion-based text-to-image (T2I) models have enabled the generation of high-quality and photorealistic images from text descriptions. However, they often exhibit societal biases related to gender, race, and socioeconomic status, thereby reinforcing harmful stereotypes and shaping public perception in unintended ways. While existing bias mitigation methods demonstrate effectiveness, they often encounter attribute entanglement, where adjustments to attributes relevant to the bias (i.e., target attributes) unintentionally alter attributes unassociated with the bias (i.e., non-target attributes), causing undesirable distribution shifts. To address this challenge, we introduce Entanglement-Free Attention (EFA), a method that accurately incorporates target attributes (e.g., White, Black, Asian, and Indian) while preserving non-target attributes (e.g., background details) during bias mitigation. At inference time, EFA randomly samples a target attribute with equal probability and adjusts the cross-attention in selected layers to incorporate the sampled attribute, achieving a fair distribution of target attributes. Extensive experiments demonstrate that EFA outperforms existing methods in mitigating bias while preserving non-target attributes, thereby maintaining the output distribution and generation capability of the original model.
What to Preserve and What to Transfer: Faithful, Identity-Preserving Diffusion-based Hairstyle Transfer
Aug 29, 2024
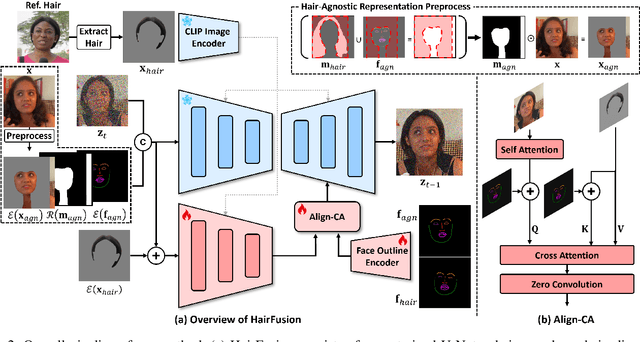


Hairstyle transfer is a challenging task in the image editing field that modifies the hairstyle of a given face image while preserving its other appearance and background features. The existing hairstyle transfer approaches heavily rely on StyleGAN, which is pre-trained on cropped and aligned face images. Hence, they struggle to generalize under challenging conditions such as extreme variations of head poses or focal lengths. To address this issue, we propose a one-stage hairstyle transfer diffusion model, HairFusion, that applies to real-world scenarios. Specifically, we carefully design a hair-agnostic representation as the input of the model, where the original hair information is thoroughly eliminated. Next, we introduce a hair align cross-attention (Align-CA) to accurately align the reference hairstyle with the face image while considering the difference in their face shape. To enhance the preservation of the face image's original features, we leverage adaptive hair blending during the inference, where the output's hair regions are estimated by the cross-attention map in Align-CA and blended with non-hair areas of the face image. Our experimental results show that our method achieves state-of-the-art performance compared to the existing methods in preserving the integrity of both the transferred hairstyle and the surrounding features. The codes are available at https://github.com/cychungg/HairFusion.
Enhancing Intrinsic Features for Debiasing via Investigating Class-Discerning Common Attributes in Bias-Contrastive Pair
Apr 30, 2024In the image classification task, deep neural networks frequently rely on bias attributes that are spuriously correlated with a target class in the presence of dataset bias, resulting in degraded performance when applied to data without bias attributes. The task of debiasing aims to compel classifiers to learn intrinsic attributes that inherently define a target class rather than focusing on bias attributes. While recent approaches mainly focus on emphasizing the learning of data samples without bias attributes (i.e., bias-conflicting samples) compared to samples with bias attributes (i.e., bias-aligned samples), they fall short of directly guiding models where to focus for learning intrinsic features. To address this limitation, this paper proposes a method that provides the model with explicit spatial guidance that indicates the region of intrinsic features. We first identify the intrinsic features by investigating the class-discerning common features between a bias-aligned (BA) sample and a bias-conflicting (BC) sample (i.e., bias-contrastive pair). Next, we enhance the intrinsic features in the BA sample that are relatively under-exploited for prediction compared to the BC sample. To construct the bias-contrastive pair without using bias information, we introduce a bias-negative score that distinguishes BC samples from BA samples employing a biased model. The experiments demonstrate that our method achieves state-of-the-art performance on synthetic and real-world datasets with various levels of bias severity.
Shortcut-V2V: Compression Framework for Video-to-Video Translation based on Temporal Redundancy Reduction
Aug 15, 2023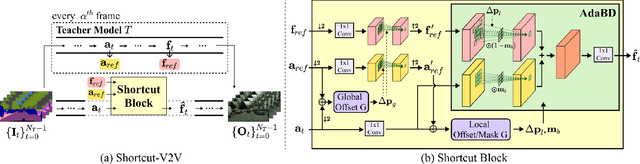



Video-to-video translation aims to generate video frames of a target domain from an input video. Despite its usefulness, the existing networks require enormous computations, necessitating their model compression for wide use. While there exist compression methods that improve computational efficiency in various image/video tasks, a generally-applicable compression method for video-to-video translation has not been studied much. In response, we present Shortcut-V2V, a general-purpose compression framework for video-to-video translation. Shourcut-V2V avoids full inference for every neighboring video frame by approximating the intermediate features of a current frame from those of the previous frame. Moreover, in our framework, a newly-proposed block called AdaBD adaptively blends and deforms features of neighboring frames, which makes more accurate predictions of the intermediate features possible. We conduct quantitative and qualitative evaluations using well-known video-to-video translation models on various tasks to demonstrate the general applicability of our framework. The results show that Shourcut-V2V achieves comparable performance compared to the original video-to-video translation model while saving 3.2-5.7x computational cost and 7.8-44x memory at test time.
DASH: Visual Analytics for Debiasing Image Classification via User-Driven Synthetic Data Augmentation
Sep 14, 2022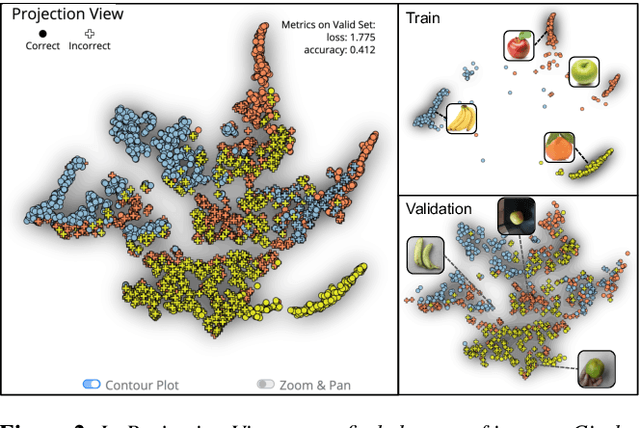
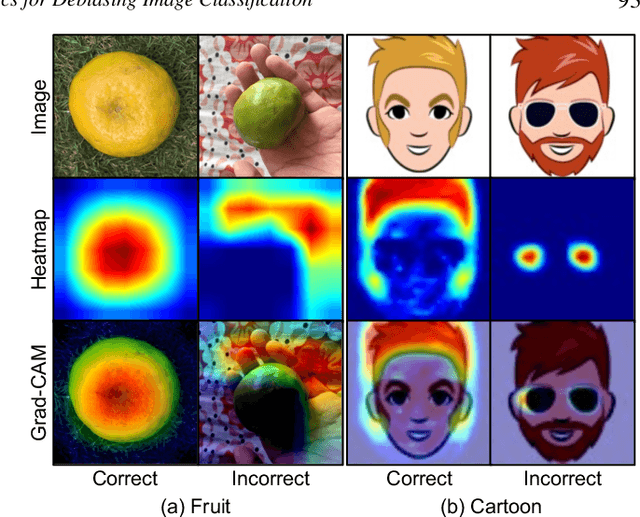
Image classification models often learn to predict a class based on irrelevant co-occurrences between input features and an output class in training data. We call the unwanted correlations "data biases," and the visual features causing data biases "bias factors." It is challenging to identify and mitigate biases automatically without human intervention. Therefore, we conducted a design study to find a human-in-the-loop solution. First, we identified user tasks that capture the bias mitigation process for image classification models with three experts. Then, to support the tasks, we developed a visual analytics system called DASH that allows users to visually identify bias factors, to iteratively generate synthetic images using a state-of-the-art image-to-image translation model, and to supervise the model training process for improving the classification accuracy. Our quantitative evaluation and qualitative study with ten participants demonstrate the usefulness of DASH and provide lessons for future work.
Style Your Hair: Latent Optimization for Pose-Invariant Hairstyle Transfer via Local-Style-Aware Hair Alignment
Aug 16, 2022
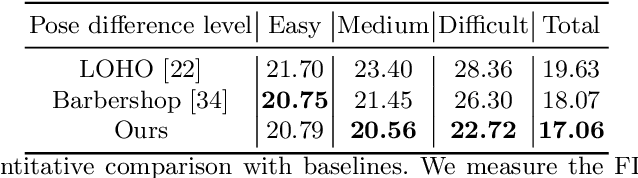
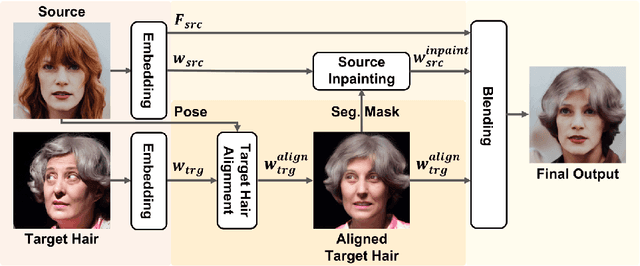

Editing hairstyle is unique and challenging due to the complexity and delicacy of hairstyle. Although recent approaches significantly improved the hair details, these models often produce undesirable outputs when a pose of a source image is considerably different from that of a target hair image, limiting their real-world applications. HairFIT, a pose-invariant hairstyle transfer model, alleviates this limitation yet still shows unsatisfactory quality in preserving delicate hair textures. To solve these limitations, we propose a high-performing pose-invariant hairstyle transfer model equipped with latent optimization and a newly presented local-style-matching loss. In the StyleGAN2 latent space, we first explore a pose-aligned latent code of a target hair with the detailed textures preserved based on local style matching. Then, our model inpaints the occlusions of the source considering the aligned target hair and blends both images to produce a final output. The experimental results demonstrate that our model has strengths in transferring a hairstyle under larger pose differences and preserving local hairstyle textures.
HairFIT: Pose-Invariant Hairstyle Transfer via Flow-based Hair Alignment and Semantic-Region-Aware Inpainting
Jun 17, 2022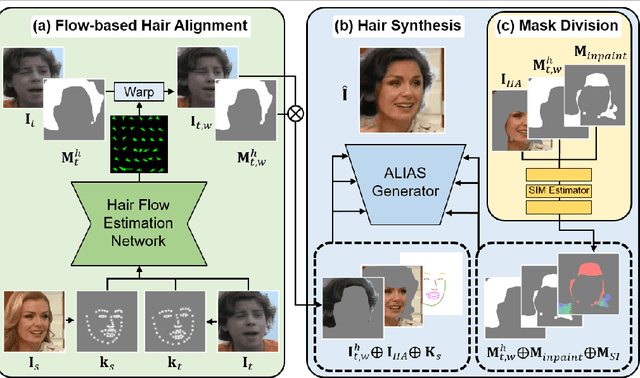

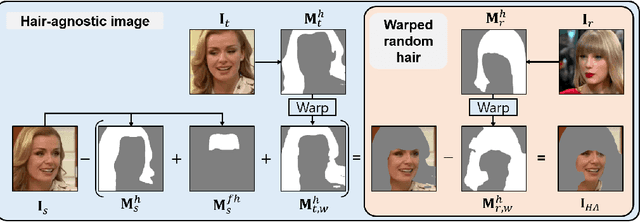

Hairstyle transfer is the task of modifying a source hairstyle to a target one. Although recent hairstyle transfer models can reflect the delicate features of hairstyles, they still have two major limitations. First, the existing methods fail to transfer hairstyles when a source and a target image have different poses (e.g., viewing direction or face size), which is prevalent in the real world. Also, the previous models generate unrealistic images when there is a non-trivial amount of regions in the source image occluded by its original hair. When modifying long hair to short hair, shoulders or backgrounds occluded by the long hair need to be inpainted. To address these issues, we propose a novel framework for pose-invariant hairstyle transfer, HairFIT. Our model consists of two stages: 1) flow-based hair alignment and 2) hair synthesis. In the hair alignment stage, we leverage a keypoint-based optical flow estimator to align a target hairstyle with a source pose. Then, we generate a final hairstyle-transferred image in the hair synthesis stage based on Semantic-region-aware Inpainting Mask (SIM) estimator. Our SIM estimator divides the occluded regions in the source image into different semantic regions to reflect their distinct features during the inpainting. To demonstrate the effectiveness of our model, we conduct quantitative and qualitative evaluations using multi-view datasets, K-hairstyle and VoxCeleb. The results indicate that HairFIT achieves a state-of-the-art performance by successfully transferring hairstyles between images of different poses, which has never been achieved before.
3D-GIF: 3D-Controllable Object Generation via Implicit Factorized Representations
Mar 12, 2022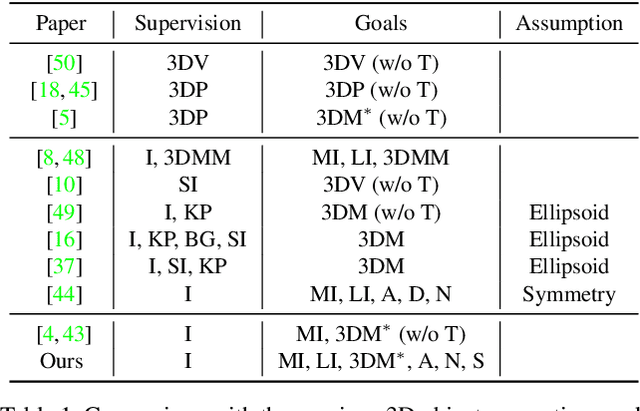
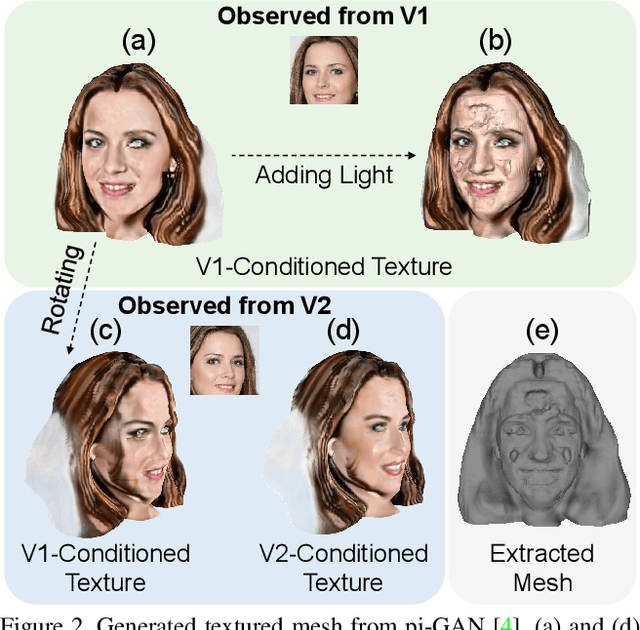

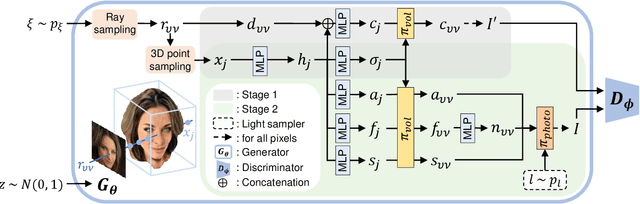
While NeRF-based 3D-aware image generation methods enable viewpoint control, limitations still remain to be adopted to various 3D applications. Due to their view-dependent and light-entangled volume representation, the 3D geometry presents unrealistic quality and the color should be re-rendered for every desired viewpoint. To broaden the 3D applicability from 3D-aware image generation to 3D-controllable object generation, we propose the factorized representations which are view-independent and light-disentangled, and training schemes with randomly sampled light conditions. We demonstrate the superiority of our method by visualizing factorized representations, re-lighted images, and albedo-textured meshes. In addition, we show that our approach improves the quality of the generated geometry via visualization and quantitative comparison. To the best of our knowledge, this is the first work that extracts albedo-textured meshes with unposed 2D images without any additional labels or assumptions.
K-Hairstyle: A Large-scale Korean hairstyle dataset for virtual hair editing and hairstyle classification
Feb 11, 2021

The hair and beauty industry is one of the fastest growing industries. This led to the development of various applications, such as virtual hair dyeing or hairstyle translations, to satisfy the need of the customers. Although there are several public hair datasets available for these applications, they consist of limited number of images with low resolution, which restrict their performance on high-quality hair editing. Therefore, we introduce a novel large-scale Korean hairstyle dataset, K-hairstyle, 256,679 with high-resolution images. In addition, K-hairstyle contains various hair attributes annotated by Korean expert hair stylists and hair segmentation masks. We validate the effectiveness of our dataset by leveraging several applications, such as hairstyle translation, and hair classification and hair retrieval. Furthermore, we will release K-hairstyle soon.