 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINT: Molecularly Informed Training with Spatial Transcriptomics Supervision for Pathology Foundation Models
Mar 09, 2026Pathology foundation models learn morphological representations through self-supervised pretraining on large-scale whole-slide images, yet they do not explicitly capture the underlying molecular state of the tissue. Spatial transcriptomics technologies bridge this gap by measuring gene expression in situ, offering a natural cross-modal supervisory signal. We propose MINT (Molecularly Informed Training), a fine-tuning framework that incorporates spatial transcriptomics supervision into pretrained pathology Vision Transformers. MINT appends a learnable ST token to the ViT input to encode transcriptomic information separately from the morphological CLS token, preventing catastrophic forgetting through DINO self-distillation and explicit feature anchoring to the frozen pretrained encoder. Gene expression regression at both spot-level (Visium) and patch-level (Xenium) resolutions provides complementary supervision across spatial scales. Trained on 577 publicly available HEST samples, MINT achieves the best overall performance on both HEST-Bench for gene expression prediction (mean Pearson r = 0.440) and EVA for general pathology tasks (0.803), demonstrating that spatial transcriptomics supervision complements morphology-centric self-supervised pretraining.
EXAONE Path 2.0: Pathology Foundation Model with End-to-End Supervision
Jul 09, 2025In digital pathology, whole-slide images (WSIs) are often difficult to handle due to their gigapixel scale, so most approaches train patch encoders via self-supervised learning (SSL) and then aggregate the patch-level embeddings via multiple instance learning (MIL) or slide encoders for downstream tasks. However, patch-level SSL may overlook complex domain-specific features that are essential for biomarker prediction, such as mutation status and molecular characteristics, as SSL methods rely only on basic augmentations selected for natural image domains on small patch-level area. Moreover, SSL methods remain less data efficient than fully supervised approaches, requiring extensive computational resources and datasets to achieve competitive performance. To address these limitations, we present EXAONE Path 2.0, a pathology foundation model that learns patch-level representations under direct slide-level supervision. Using only 37k WSIs for training, EXAONE Path 2.0 achieves state-of-the-art average performance across 10 biomarker prediction tasks, demonstrating remarkable data efficiency.
OmniSplat: Taming Feed-Forward 3D Gaussian Splatting for Omnidirectional Images with Editable Capabilities
Dec 21, 2024



Feed-forward 3D Gaussian Splatting (3DGS) models have gained significant popularity due to their ability to generate scenes immediately without needing per-scene optimization. Although omnidirectional images are getting more popular since they reduce the computation for image stitching to composite a holistic scene, existing feed-forward models are only designed for perspective images. The unique optical properties of omnidirectional images make it difficult for feature encoders to correctly understand the context of the image and make the Gaussian non-uniform in space, which hinders the image quality synthesized from novel views. We propose OmniSplat, a pioneering work for fast feed-forward 3DGS generation from a few omnidirectional images. We introduce Yin-Yang grid and decompose images based on it to reduce the domain gap between omnidirectional and perspective images. The Yin-Yang grid can use the existing CNN structure as it is, but its quasi-uniform characteristic allows the decomposed image to be similar to a perspective image, so it can exploit the strong prior knowledge of the learned feed-forward network. OmniSplat demonstrates higher reconstruction accuracy than existing feed-forward networks trained on perspective images. Furthermore, we enhance the segmentation consistency between omnidirectional images by leveraging attention from the encoder of OmniSplat, providing fast and clean 3DGS editing results.
ReFu: Refine and Fuse the Unobserved View for Detail-Preserving Single-Image 3D Human Reconstruction
Nov 09, 2022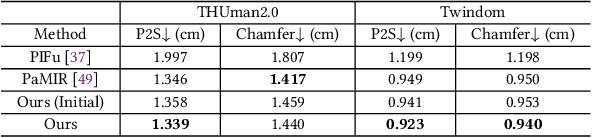
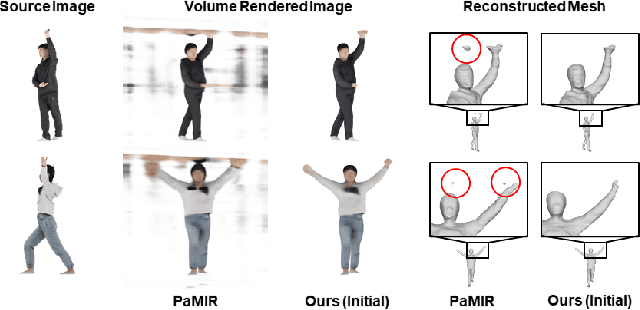
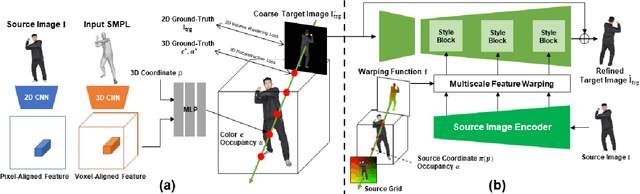

Single-image 3D human reconstruction aims to reconstruct the 3D textured surface of the human body given a single image. While implicit function-based methods recently achieved reasonable reconstruction performance, they still bear limitations showing degraded quality in both surface geometry and texture from an unobserved view. In response, to generate a realistic textured surface, we propose ReFu, a coarse-to-fine approach that refines the projected backside view image and fuses the refined image to predict the final human body. To suppress the diffused occupancy that causes noise in projection images and reconstructed meshes, we propose to train occupancy probability by simultaneously utilizing 2D and 3D supervisions with occupancy-based volume rendering. We also introduce a refinement architecture that generates detail-preserving backside-view images with front-to-back warping. Extensive experiments demonstrate that our method achieves state-of-the-art performance in 3D human reconstruction from a single image, showing enhanced geometry and texture quality from an unobserved view.
3D-GIF: 3D-Controllable Object Generation via Implicit Factorized Representations
Mar 12, 2022
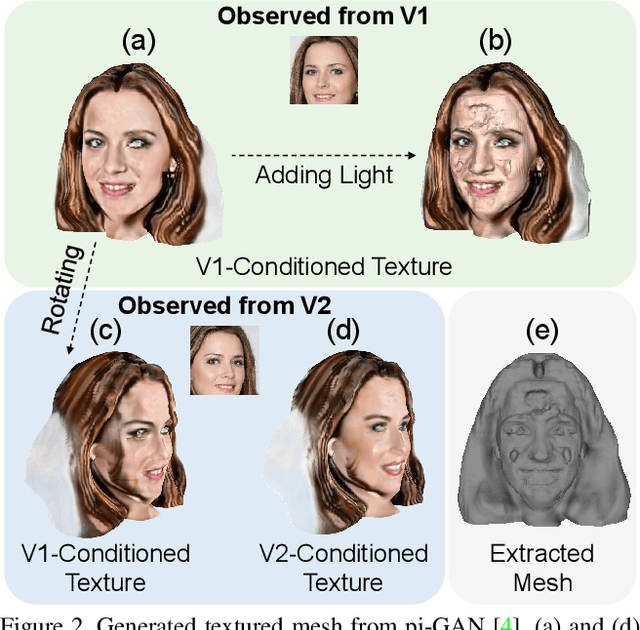

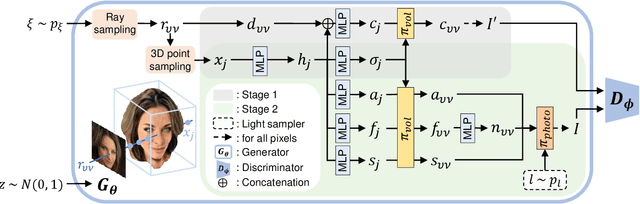
While NeRF-based 3D-aware image generation methods enable viewpoint control, limitations still remain to be adopted to various 3D applications. Due to their view-dependent and light-entangled volume representation, the 3D geometry presents unrealistic quality and the color should be re-rendered for every desired viewpoint. To broaden the 3D applicability from 3D-aware image generation to 3D-controllable object generation, we propose the factorized representations which are view-independent and light-disentangled, and training schemes with randomly sampled light conditions. We demonstrate the superiority of our method by visualizing factorized representations, re-lighted images, and albedo-textured meshes. In addition, we show that our approach improves the quality of the generated geometry via visualization and quantitative comparison. To the best of our knowledge, this is the first work that extracts albedo-textured meshes with unposed 2D images without any additional labels or assumptions.
VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization
Mar 31, 2021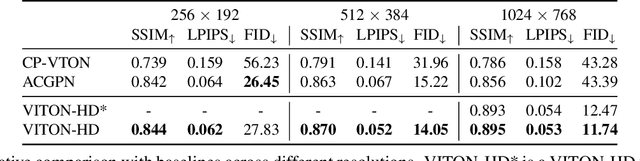

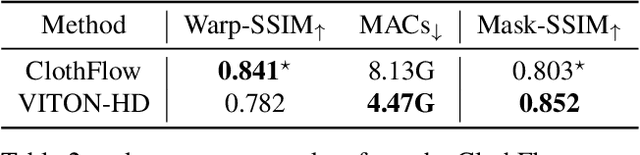
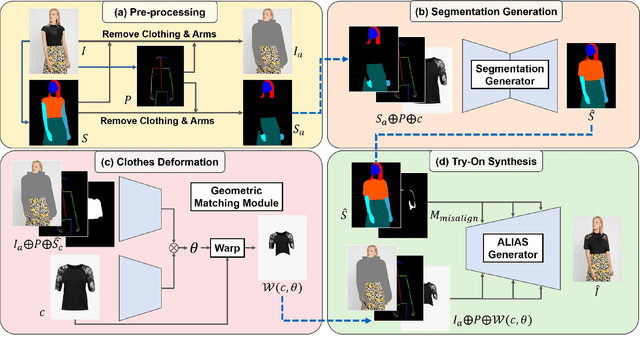
The task of image-based virtual try-on aims to transfer a target clothing item onto the corresponding region of a person, which is commonly tackled by fitting the item to the desired body part and fusing the warped item with the person. While an increasing number of studies have been conducted, the resolution of synthesized images is still limited to low (e.g., 256x192), which acts as the critical limitation against satisfying online consumers. We argue that the limitation stems from several challenges: as the resolution increases, the artifacts in the misaligned areas between the warped clothes and the desired clothing regions become noticeable in the final results; the architectures used in existing methods have low performance in generating high-quality body parts and maintaining the texture sharpness of the clothes. To address the challenges, we propose a novel virtual try-on method called VITON-HD that successfully synthesizes 1024x768 virtual try-on images. Specifically, we first prepare the segmentation map to guide our virtual try-on synthesis, and then roughly fit the target clothing item to a given person's body. Next, we propose ALIgnment-Aware Segment (ALIAS) normalization and ALIAS generator to handle the misaligned areas and preserve the details of 1024x768 inputs. Through rigorous comparison with existing methods, we demonstrate that VITON-HD highly sur-passes the baselines in terms of synthesized image quality both qualitatively and quantitatively.