 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianMotion: End-to-End Learning of Animatable Gaussian Avatars with Pose Guidance from Text
Feb 17, 2025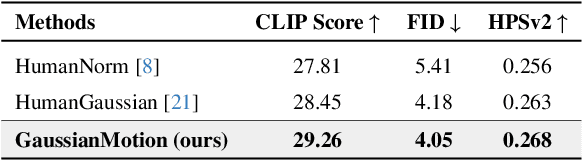
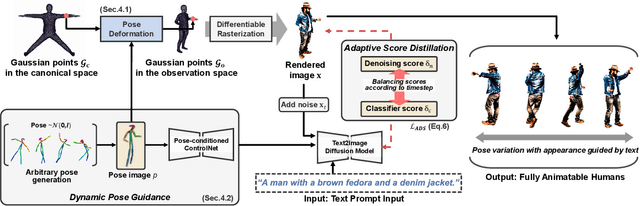
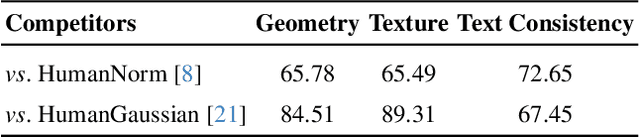

In this paper, we introduce GaussianMotion, a novel human rendering model that generates fully animatable scenes aligned with textual descriptions using Gaussian Splatting. Although existing methods achieve reasonable text-to-3D generation of human bodies using various 3D representations, they often face limitations in fidelity and efficiency, or primarily focus on static models with limited pose control. In contrast, our method generates fully animatable 3D avatars by combining deformable 3D Gaussian Splatting with text-to-3D score distillation, achieving high fidelity and efficient rendering for arbitrary poses. By densely generating diverse random poses during optimization, our deformable 3D human model learns to capture a wide range of natural motions distilled from a pose-conditioned diffusion model in an end-to-end manner. Furthermore, we propose Adaptive Score Distillation that effectively balances realistic detail and smoothness to achieve optimal 3D results. Experimental results demonstrate that our approach outperforms existing baselines by producing high-quality textures in both static and animated results, and by generating diverse 3D human models from various textual inputs.
PixelHuman: Animatable Neural Radiance Fields from Few Images
Jul 18, 2023In this paper, we propose PixelHuman, a novel human rendering model that generates animatable human scenes from a few images of a person with unseen identity, views, and poses. Previous work have demonstrated reasonable performance in novel view and pose synthesis, but they rely on a large number of images to train and are trained per scene from videos, which requires significant amount of time to produce animatable scenes from unseen human images. Our method differs from existing methods in that it can generalize to any input image for animatable human synthesis. Given a random pose sequence, our method synthesizes each target scene using a neural radiance field that is conditioned on a canonical representation and pose-aware pixel-aligned features, both of which can be obtained through deformation fields learned in a data-driven manner. Our experiments show that our method achieves state-of-the-art performance in multiview and novel pose synthesis from few-shot images.
ReFu: Refine and Fuse the Unobserved View for Detail-Preserving Single-Image 3D Human Reconstruction
Nov 09, 2022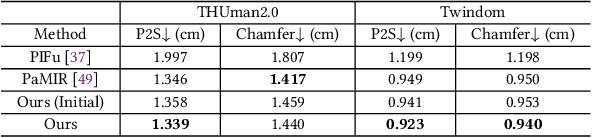
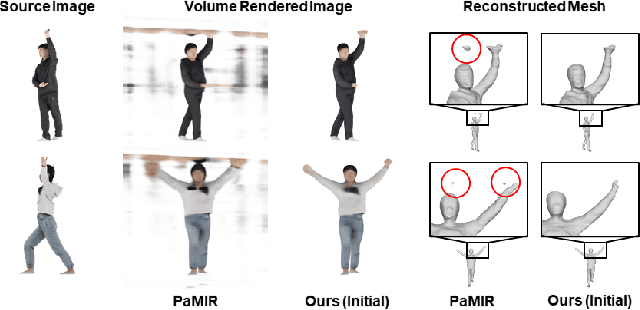
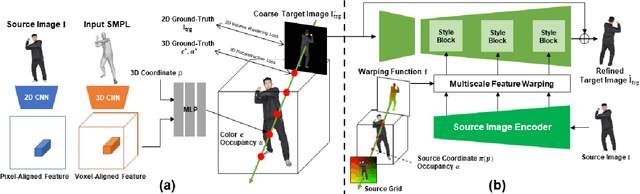

Single-image 3D human reconstruction aims to reconstruct the 3D textured surface of the human body given a single image. While implicit function-based methods recently achieved reasonable reconstruction performance, they still bear limitations showing degraded quality in both surface geometry and texture from an unobserved view. In response, to generate a realistic textured surface, we propose ReFu, a coarse-to-fine approach that refines the projected backside view image and fuses the refined image to predict the final human body. To suppress the diffused occupancy that causes noise in projection images and reconstructed meshes, we propose to train occupancy probability by simultaneously utilizing 2D and 3D supervisions with occupancy-based volume rendering. We also introduce a refinement architecture that generates detail-preserving backside-view images with front-to-back warping. Extensive experiments demonstrate that our method achieves state-of-the-art performance in 3D human reconstruction from a single image, showing enhanced geometry and texture quality from an unobserved view.
CG-NeRF: Conditional Generative Neural Radiance Fields
Dec 07, 2021
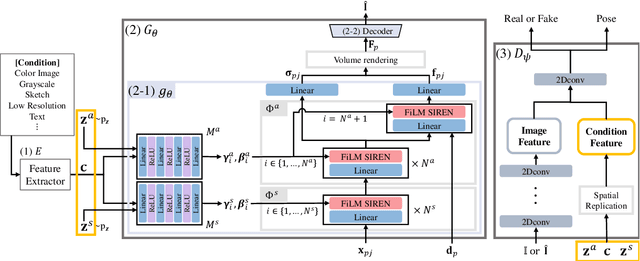


While recent NeRF-based generative models achieve the generation of diverse 3D-aware images, these approaches have limitations when generating images that contain user-specified characteristics. In this paper, we propose a novel model, referred to as the conditional generative neural radiance fields (CG-NeRF), which can generate multi-view images reflecting extra input conditions such as images or texts. While preserving the common characteristics of a given input condition, the proposed model generates diverse images in fine detail. We propose: 1) a novel unified architecture which disentangles the shape and appearance from a condition given in various forms and 2) the pose-consistent diversity loss for generating multimodal outputs while maintaining consistency of the view. Experimental results show that the proposed method maintains consistent image quality on various condition types and achieves superior fidelity and diversity compared to existing NeRF-based generative models.
Camera Exposure Control for Robust Robot Vision with Noise-Aware Image Quality Assessment
Jul 11, 2019



In this paper, we propose a noise-aware exposure control algorithm for robust robot vision. Our method aims to capture the best-exposed image which can boost the performance of various computer vision and robotics tasks. For this purpose, we carefully design an image quality metric which captures complementary quality attributes and ensures light-weight computation. Specifically, our metric consists of a combination of image gradient, entropy, and noise metrics. The synergy of these measures allows preserving sharp edge and rich texture in the image while maintaining a low noise level. Using this novel metric, we propose a real-time and fully automatic exposure and gain control technique based on the Nelder-Mead method. To illustrate the effectiveness of our technique, a large set of experimental results demonstrates higher qualitative and quantitative performances when compared with conventional approaches.