 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTherA: Thermal-Aware Visual-Language Prompting for Controllable RGB-to-Thermal Infrared Translation
Feb 24, 2026Despite the inherent advantages of thermal infrared(TIR) imaging, large-scale data collection and annotation remain a major bottleneck for TIR-based perception. A practical alternative is to synthesize pseudo TIR data via image translation; however, most RGB-to-TIR approaches heavily rely on RGB-centric priors that overlook thermal physics, yielding implausible heat distributions. In this paper, we introduce TherA, a controllable RGB-to-TIR translation framework that produces diverse and thermally plausible images at both scene and object level. TherA couples TherA-VLM with a latent-diffusion-based translator. Given a single RGB image and a user-prompted condition pair, TherA-VLM yields a thermal-aware embedding that encodes scene, object, material, and heat-emission context reflecting the input scene-condition pair. Conditioning the diffusion model on this embedding enables realistic TIR synthesis and fine-grained control across time of day, weather, and object state. Compared to other baselines, TherA achieves state-of-the-art translation performance, demonstrating improved zero-shot translation performance up to 33% increase averaged across all metrics.
All-day Depth Completion via Thermal-LiDAR Fusion
Apr 03, 2025Depth completion, which estimates dense depth from sparse LiDAR and RGB images, has demonstrated outstanding performance in well-lit conditions. However, due to the limitations of RGB sensors, existing methods often struggle to achieve reliable performance in harsh environments, such as heavy rain and low-light conditions. Furthermore, we observe that ground truth depth maps often suffer from large missing measurements in adverse weather conditions such as heavy rain, leading to insufficient supervision. In contrast, thermal cameras are known for providing clear and reliable visibility in such conditions, yet research on thermal-LiDAR depth completion remains underexplored. Moreover, the characteristics of thermal images, such as blurriness, low contrast, and noise, bring unclear depth boundary problems. To address these challenges, we first evaluate the feasibility and robustness of thermal-LiDAR depth completion across diverse lighting (eg., well-lit, low-light), weather (eg., clear-sky, rainy), and environment (eg., indoor, outdoor) conditions, by conducting extensive benchmarks on the MS$^2$ and ViViD datasets. In addition, we propose a framework that utilizes COntrastive learning and Pseudo-Supervision (COPS) to enhance depth boundary clarity and improve completion accuracy by leveraging a depth foundation model in two key ways. First, COPS enforces a depth-aware contrastive loss between different depth points by mining positive and negative samples using a monocular depth foundation model to sharpen depth boundaries. Second, it mitigates the issue of incomplete supervision from ground truth depth maps by leveraging foundation model predictions as dense depth priors. We also provide in-depth analyses of the key challenges in thermal-LiDAR depth completion to aid in understanding the task and encourage future research.
Deep Depth Estimation from Thermal Image: Dataset, Benchmark, and Challenges
Mar 28, 2025



Achieving robust and accurate spatial perception under adverse weather and lighting conditions is crucial for the high-level autonomy of self-driving vehicles and robots. However, existing perception algorithms relying on the visible spectrum are highly affected by weather and lighting conditions. A long-wave infrared camera (i.e., thermal imaging camera) can be a potential solution to achieve high-level robustness. However, the absence of large-scale datasets and standardized benchmarks remains a significant bottleneck to progress in active research for robust visual perception from thermal images. To this end, this manuscript provides a large-scale Multi-Spectral Stereo (MS$^2$) dataset that consists of stereo RGB, stereo NIR, stereo thermal, stereo LiDAR data, and GNSS/IMU information along with semi-dense depth ground truth. MS$^2$ dataset includes 162K synchronized multi-modal data pairs captured across diverse locations (e.g., urban city, residential area, campus, and high-way road) at different times (e.g., morning, daytime, and nighttime) and under various weather conditions (e.g., clear-sky, cloudy, and rainy). Secondly, we conduct a thorough evaluation of monocular and stereo depth estimation networks across RGB, NIR, and thermal modalities to establish standardized benchmark results on MS$^2$ depth test sets (e.g., day, night, and rainy). Lastly, we provide in-depth analyses and discuss the challenges revealed by the benchmark results, such as the performance variability for each modality under adverse conditions, domain shift between different sensor modalities, and potential research direction for thermal perception. Our dataset and source code are publicly available at https://sites.google.com/view/multi-spectral-stereo-dataset and https://github.com/UkcheolShin/SupDepth4Thermal.
FIReStereo: Forest InfraRed Stereo Dataset for UAS Depth Perception in Visually Degraded Environments
Sep 12, 2024



Robust depth perception in visually-degraded environments is crucial for autonomous aerial systems. Thermal imaging cameras, which capture infrared radiation, are robust to visual degradation. However, due to lack of a large-scale dataset, the use of thermal cameras for unmanned aerial system (UAS) depth perception has remained largely unexplored. This paper presents a stereo thermal depth perception dataset for autonomous aerial perception applications. The dataset consists of stereo thermal images, LiDAR, IMU and ground truth depth maps captured in urban and forest settings under diverse conditions like day, night, rain, and smoke. We benchmark representative stereo depth estimation algorithms, offering insights into their performance in degraded conditions. Models trained on our dataset generalize well to unseen smoky conditions, highlighting the robustness of stereo thermal imaging for depth perception. We aim for this work to enhance robotic perception in disaster scenarios, allowing for exploration and operations in previously unreachable areas. The dataset and source code are available at https://firestereo.github.io.
VPOcc: Exploiting Vanishing Point for Monocular 3D Semantic Occupancy Prediction
Aug 07, 2024



Monocular 3D semantic occupancy prediction is becoming important in robot vision due to the compactness of using a single RGB camera. However, existing methods often do not adequately account for camera perspective geometry, resulting in information imbalance along the depth range of the image. To address this issue, we propose a vanishing point (VP) guided monocular 3D semantic occupancy prediction framework named VPOcc. Our framework consists of three novel modules utilizing VP. First, in the VPZoomer module, we initially utilize VP in feature extraction to achieve information balanced feature extraction across the scene by generating a zoom-in image based on VP. Second, we perform perspective geometry-aware feature aggregation by sampling points towards VP using a VP-guided cross-attention (VPCA) module. Finally, we create an information-balanced feature volume by effectively fusing original and zoom-in voxel feature volumes with a balanced feature volume fusion (BVFV) module. Experiments demonstrate that our method achieves state-of-the-art performance for both IoU and mIoU on SemanticKITTI and SSCBench-KITTI360. These results are obtained by effectively addressing the information imbalance in images through the utilization of VP. Our code will be available at www.github.com/anonymous.
Flow4D: Leveraging 4D Voxel Network for LiDAR Scene Flow Estimation
Jul 10, 2024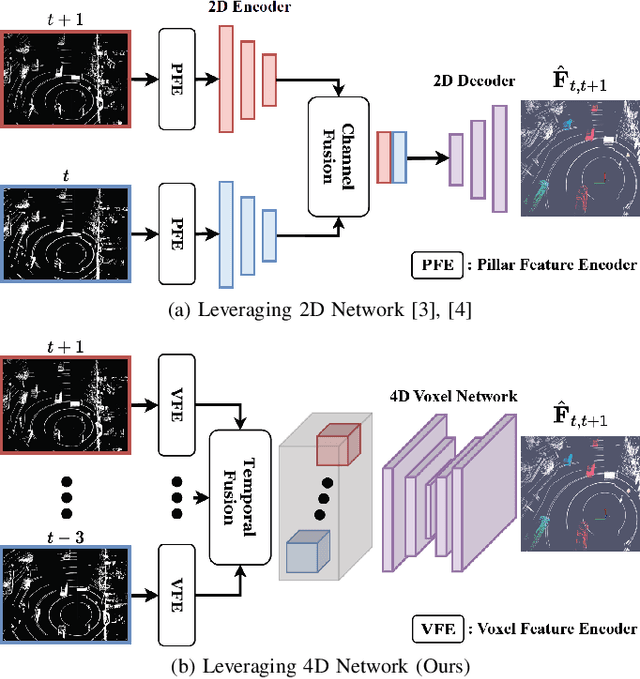
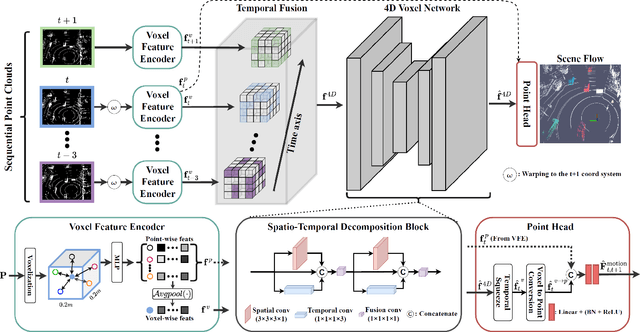
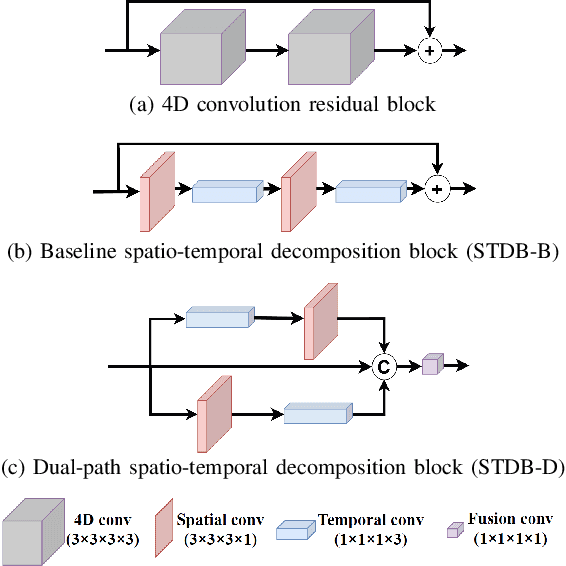
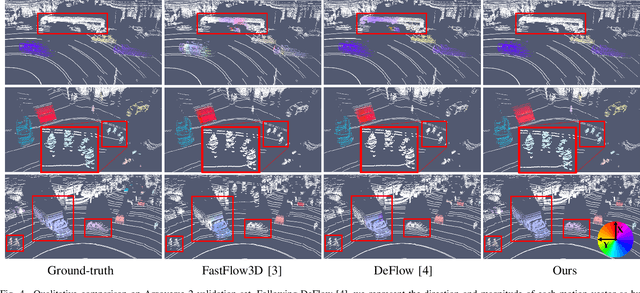
Understanding the motion states of the surrounding environment is critical for safe autonomous driving. These motion states can be accurately derived from scene flow, which captures the three-dimensional motion field of points. Existing LiDAR scene flow methods extract spatial features from each point cloud and then fuse them channel-wise, resulting in the implicit extraction of spatio-temporal features. Furthermore, they utilize 2D Bird's Eye View and process only two frames, missing crucial spatial information along the Z-axis and the broader temporal context, leading to suboptimal performance. To address these limitations, we propose Flow4D, which temporally fuses multiple point clouds after the 3D intra-voxel feature encoder, enabling more explicit extraction of spatio-temporal features through a 4D voxel network. However, while using 4D convolution improves performance, it significantly increases the computational load. For further efficiency, we introduce the Spatio-Temporal Decomposition Block (STDB), which combines 3D and 1D convolutions instead of using heavy 4D convolution. In addition, Flow4D further improves performance by using five frames to take advantage of richer temporal information. As a result, the proposed method achieves a 45.9% higher performance compared to the state-of-the-art while running in real-time, and won 1st place in the 2024 Argoverse 2 Scene Flow Challenge. The code is available at https://github.com/dgist-cvlab/Flow4D.
Learning to Control Camera Exposure via Reinforcement Learning
Apr 02, 2024



Adjusting camera exposure in arbitrary lighting conditions is the first step to ensure the functionality of computer vision applications. Poorly adjusted camera exposure often leads to critical failure and performance degradation. Traditional camera exposure control methods require multiple convergence steps and time-consuming processes, making them unsuitable for dynamic lighting conditions. In this paper, we propose a new camera exposure control framework that rapidly controls camera exposure while performing real-time processing by exploiting deep reinforcement learning. The proposed framework consists of four contributions: 1) a simplified training ground to simulate real-world's diverse and dynamic lighting changes, 2) flickering and image attribute-aware reward design, along with lightweight state design for real-time processing, 3) a static-to-dynamic lighting curriculum to gradually improve the agent's exposure-adjusting capability, and 4) domain randomization techniques to alleviate the limitation of the training ground and achieve seamless generalization in the wild.As a result, our proposed method rapidly reaches a desired exposure level within five steps with real-time processing (1 ms). Also, the acquired images are well-exposed and show superiority in various computer vision tasks, such as feature extraction and object detection.
Stable Surface Regularization for Fast Few-Shot NeRF
Mar 29, 2024This paper proposes an algorithm for synthesizing novel views under few-shot setup. The main concept is to develop a stable surface regularization technique called Annealing Signed Distance Function (ASDF), which anneals the surface in a coarse-to-fine manner to accelerate convergence speed. We observe that the Eikonal loss - which is a widely known geometric regularization - requires dense training signal to shape different level-sets of SDF, leading to low-fidelity results under few-shot training. In contrast, the proposed surface regularization successfully reconstructs scenes and produce high-fidelity geometry with stable training. Our method is further accelerated by utilizing grid representation and monocular geometric priors. Finally, the proposed approach is up to 45 times faster than existing few-shot novel view synthesis methods, and it produces comparable results in the ScanNet dataset and NeRF-Real dataset.
Learning Quadrupedal Locomotion with Impaired Joints Using Random Joint Masking
Mar 01, 2024
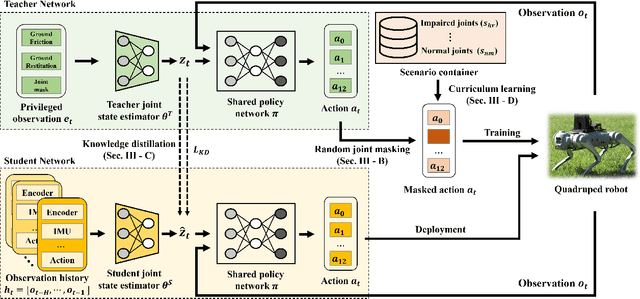
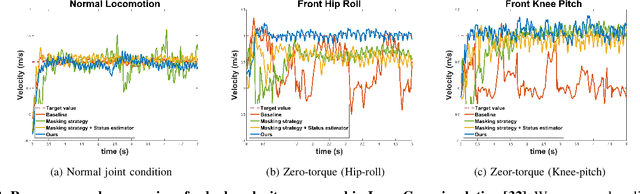

Quadrupedal robots have played a crucial role in various environments, from structured environments to complex harsh terrains, thanks to their agile locomotion ability. However, these robots can easily lose their locomotion functionality if damaged by external accidents or internal malfunctions. In this paper, we propose a novel deep reinforcement learning framework to enable a quadrupedal robot to walk with impaired joints. The proposed framework consists of three components: 1) a random joint masking strategy for simulating impaired joint scenarios, 2) a joint state estimator to predict an implicit status of current joint condition based on past observation history, and 3) progressive curriculum learning to allow a single network to conduct both normal gait and various joint-impaired gaits. We verify that our framework enables the Unitree's Go1 robot to walk under various impaired joint conditions in real-world indoor and outdoor environments.
Complementary Random Masking for RGB-Thermal Semantic Segmentation
Mar 30, 2023



RGB-thermal semantic segmentation is one potential solution to achieve reliable semantic scene understanding in adverse weather and lighting conditions. However, the previous studies mostly focus on designing a multi-modal fusion module without consideration of the nature of multi-modality inputs. Therefore, the networks easily become over-reliant on a single modality, making it difficult to learn complementary and meaningful representations for each modality. This paper proposes 1) a complementary random masking strategy of RGB-T images and 2) self-distillation loss between clean and masked input modalities. The proposed masking strategy prevents over-reliance on a single modality. It also improves the accuracy and robustness of the neural network by forcing the network to segment and classify objects even when one modality is partially available. Also, the proposed self-distillation loss encourages the network to extract complementary and meaningful representations from a single modality or complementary masked modalities. Based on the proposed method, we achieve state-of-the-art performance over three RGB-T semantic segmentation benchmarks. Our source code is available at https://github.com/UkcheolShin/CRM_RGBTSeg.