 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyThermal: Towards Learning Universal Representations for Thermal Perception
Feb 05, 2026We present AnyThermal, a thermal backbone that captures robust task-agnostic thermal features suitable for a variety of tasks such as cross-modal place recognition, thermal segmentation, and monocular depth estimation using thermal images. Existing thermal backbones that follow task-specific training from small-scale data result in utility limited to a specific environment and task. Unlike prior methods, AnyThermal can be used for a wide range of environments (indoor, aerial, off-road, urban) and tasks, all without task-specific training. Our key insight is to distill the feature representations from visual foundation models such as DINOv2 into a thermal encoder using thermal data from these multiple environments. To bridge the diversity gap of the existing RGB-Thermal datasets, we introduce the TartanRGBT platform, the first open-source data collection platform with synced RGB-Thermal image acquisition. We use this payload to collect the TartanRGBT dataset - a diverse and balanced dataset collected in 4 environments. We demonstrate the efficacy of AnyThermal and TartanRGBT, achieving state-of-the-art results with improvements of up to 36% across diverse environments and downstream tasks on existing datasets.
IA-TIGRIS: An Incremental and Adaptive Sampling-Based Planner for Online Informative Path Planning
Feb 21, 2025
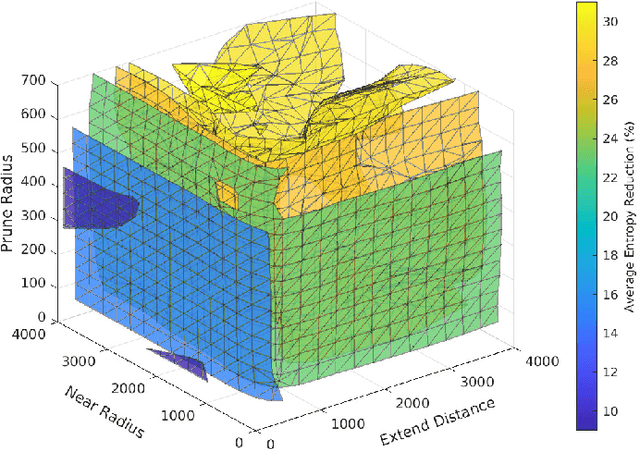
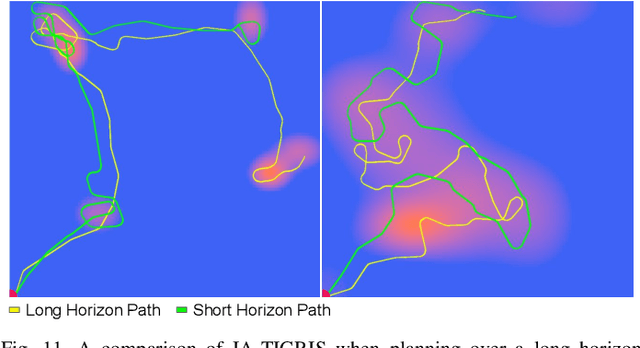
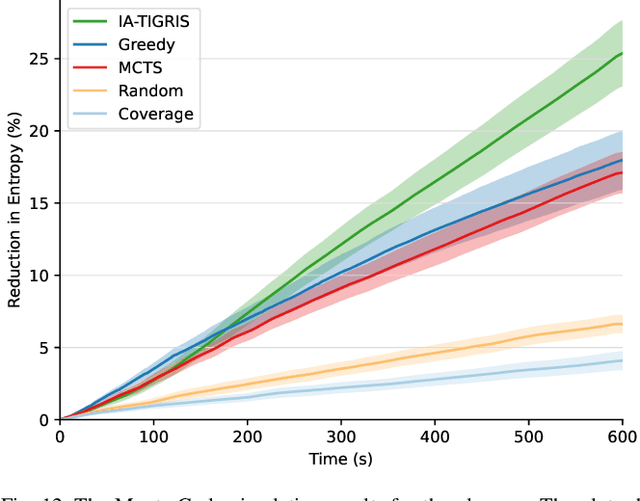
Planning paths that maximize information gain for robotic platforms has wide-ranging applications and significant potential impact. To effectively adapt to real-time data collection, informative path planning must be computed online and be responsive to new observations. In this work, we present IA-TIGRIS, an incremental and adaptive sampling-based informative path planner that can be run efficiently with onboard computation. Our approach leverages past planning efforts through incremental refinement while continuously adapting to updated world beliefs. We additionally present detailed implementation and optimization insights to facilitate real-world deployment, along with an array of reward functions tailored to specific missions and behaviors. Extensive simulation results demonstrate IA-TIGRIS generates higher-quality paths compared to baseline methods. We validate our planner on two distinct hardware platforms: a hexarotor UAV and a fixed-wing UAV, each having unique motion models and configuration spaces. Our results show up to a 41% improvement in information gain compared to baseline methods, suggesting significant potential for deployment in real-world applications.
FIReStereo: Forest InfraRed Stereo Dataset for UAS Depth Perception in Visually Degraded Environments
Sep 12, 2024



Robust depth perception in visually-degraded environments is crucial for autonomous aerial systems. Thermal imaging cameras, which capture infrared radiation, are robust to visual degradation. However, due to lack of a large-scale dataset, the use of thermal cameras for unmanned aerial system (UAS) depth perception has remained largely unexplored. This paper presents a stereo thermal depth perception dataset for autonomous aerial perception applications. The dataset consists of stereo thermal images, LiDAR, IMU and ground truth depth maps captured in urban and forest settings under diverse conditions like day, night, rain, and smoke. We benchmark representative stereo depth estimation algorithms, offering insights into their performance in degraded conditions. Models trained on our dataset generalize well to unseen smoky conditions, highlighting the robustness of stereo thermal imaging for depth perception. We aim for this work to enhance robotic perception in disaster scenarios, allowing for exploration and operations in previously unreachable areas. The dataset and source code are available at https://firestereo.github.io.
WIT-UAS: A Wildland-fire Infrared Thermal Dataset to Detect Crew Assets From Aerial Views
Dec 14, 2023
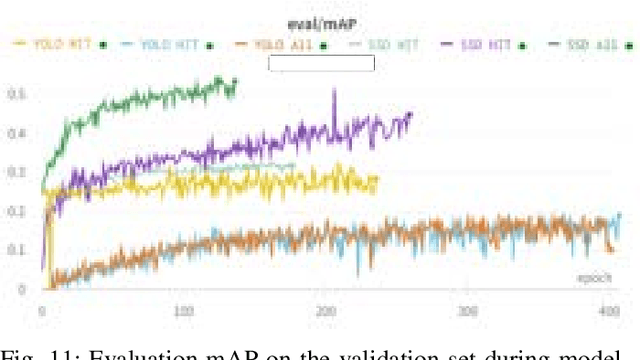
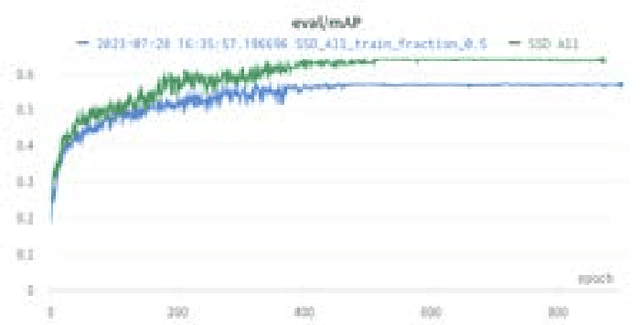
We present the Wildland-fire Infrared Thermal (WIT-UAS) dataset for long-wave infrared sensing of crew and vehicle assets amidst prescribed wildland fire environments. While such a dataset is crucial for safety monitoring in wildland fire applications, to the authors' awareness, no such dataset focusing on assets near fire is publicly available. Presumably, this is due to the barrier to entry of collaborating with fire management personnel. We present two related data subsets: WIT-UAS-ROS consists of full ROS bag files containing sensor and robot data of UAS flight over the fire, and WIT-UAS-Image contains hand-labeled long-wave infrared (LWIR) images extracted from WIT-UAS-ROS. Our dataset is the first to focus on asset detection in a wildland fire environment. We show that thermal detection models trained without fire data frequently detect false positives by classifying fire as people. By adding our dataset to training, we show that the false positive rate is reduced significantly. Yet asset detection in wildland fire environments is still significantly more challenging than detection in urban environments, due to dense obscuring trees, greater heat variation, and overbearing thermal signal of the fire. We publicize this dataset to encourage the community to study more advanced models to tackle this challenging environment. The dataset, code and pretrained models are available at \url{https://github.com/castacks/WIT-UAS-Dataset}.
3D Human Reconstruction in the Wild with Collaborative Aerial Cameras
Aug 09, 2021
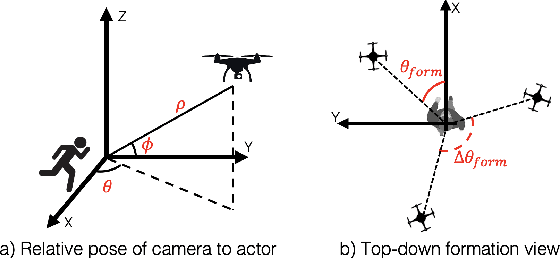
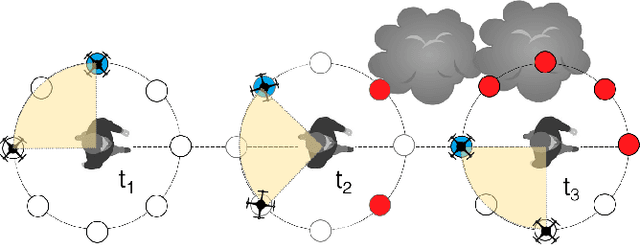

Aerial vehicles are revolutionizing applications that require capturing the 3D structure of dynamic targets in the wild, such as sports, medicine, and entertainment. The core challenges in developing a motion-capture system that operates in outdoors environments are: (1) 3D inference requires multiple simultaneous viewpoints of the target, (2) occlusion caused by obstacles is frequent when tracking moving targets, and (3) the camera and vehicle state estimation is noisy. We present a real-time aerial system for multi-camera control that can reconstruct human motions in natural environments without the use of special-purpose markers. We develop a multi-robot coordination scheme that maintains the optimal flight formation for target reconstruction quality amongst obstacles. We provide studies evaluating system performance in simulation, and validate real-world performance using two drones while a target performs activities such as jogging and playing soccer. Supplementary video: https://youtu.be/jxt91vx0cns
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on
Jan 13, 2021



Virtual try-on has garnered interest as a neural rendering benchmark task to evaluate complex object transfer and scene composition. Recent works in virtual clothing try-on feature a plethora of possible architectural and data representation choices. However, they present little clarity on quantifying the isolated visual effect of each choice, nor do they specify the hyperparameter details that are key to experimental reproduction. Our work, ShineOn, approaches the try-on task from a bottom-up approach and aims to shine light on the visual and quantitative effects of each experiment. We build a series of scientific experiments to isolate effective design choices in video synthesis for virtual clothing try-on. Specifically, we investigate the effect of different pose annotations, self-attention layer placement, and activation functions on the quantitative and qualitative performance of video virtual try-on. We find that DensePose annotations not only enhance face details but also decrease memory usage and training time. Next, we find that attention layers improve face and neck quality. Finally, we show that GELU and ReLU activation functions are the most effective in our experiments despite the appeal of newer activations such as Swish and Sine. We will release a well-organized code base, hyperparameters, and model checkpoints to support the reproducibility of our results. We expect our extensive experiments and code to greatly inform future design choices in video virtual try-on. Our code may be accessed at https://github.com/andrewjong/ShineOn-Virtual-Tryon.
Generating Bilingual Pragmatic Color References
May 19, 2018



Contextual influences on language often exhibit substantial cross-lingual regularities; for example, we are more verbose in situations that require finer distinctions. However, these regularities are sometimes obscured by semantic and syntactic differences. Using a newly-collected dataset of color reference games in Mandarin Chinese (which we release to the public), we confirm that a variety of constructions display the same sensitivity to contextual difficulty in Chinese and English. We then show that a neural speaker agent trained on bilingual data with a simple multitask learning approach displays more human-like patterns of context dependence and is more pragmatically informative than its monolingual Chinese counterpart. Moreover, this is not at the expense of language-specific semantic understanding: the resulting speaker model learns the different basic color term systems of English and Chinese (with noteworthy cross-lingual influences), and it can identify synonyms between the two languages using vector analogy operations on its output layer, despite having no exposure to parallel data.