 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayFronts: Open-Set Semantic Ray Frontiers for Online Scene Understanding and Exploration
Apr 09, 2025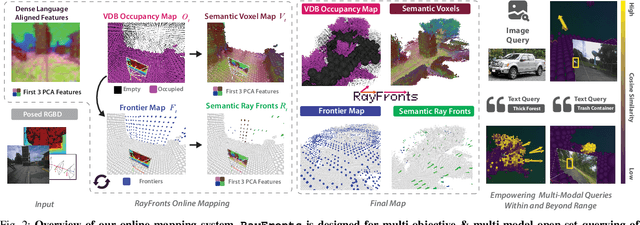
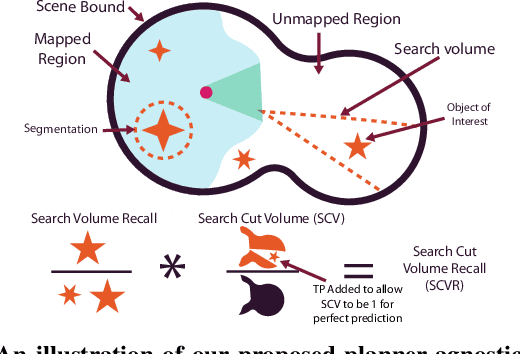
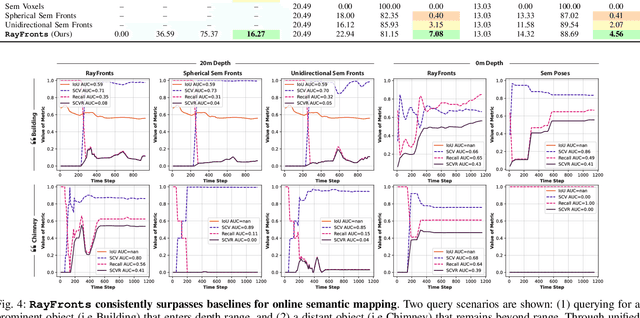
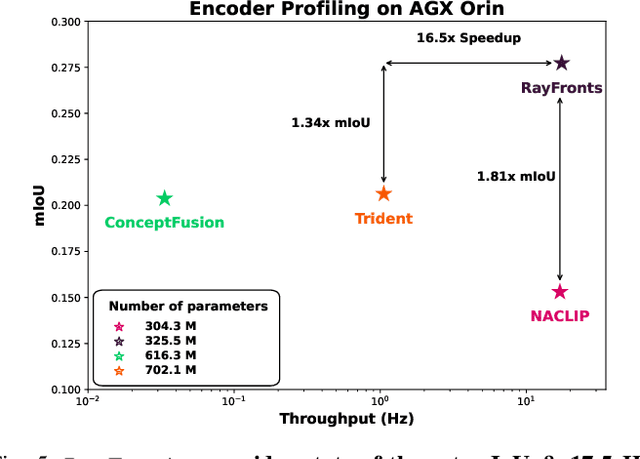
Open-set semantic mapping is crucial for open-world robots. Current mapping approaches either are limited by the depth range or only map beyond-range entities in constrained settings, where overall they fail to combine within-range and beyond-range observations. Furthermore, these methods make a trade-off between fine-grained semantics and efficiency. We introduce RayFronts, a unified representation that enables both dense and beyond-range efficient semantic mapping. RayFronts encodes task-agnostic open-set semantics to both in-range voxels and beyond-range rays encoded at map boundaries, empowering the robot to reduce search volumes significantly and make informed decisions both within & beyond sensory range, while running at 8.84 Hz on an Orin AGX. Benchmarking the within-range semantics shows that RayFronts's fine-grained image encoding provides 1.34x zero-shot 3D semantic segmentation performance while improving throughput by 16.5x. Traditionally, online mapping performance is entangled with other system components, complicating evaluation. We propose a planner-agnostic evaluation framework that captures the utility for online beyond-range search and exploration, and show RayFronts reduces search volume 2.2x more efficiently than the closest online baselines.
PIPE Planner: Pathwise Information Gain with Map Predictions for Indoor Robot Exploration
Mar 10, 2025



Autonomous exploration in unknown environments requires estimating the information gain of an action to guide planning decisions. While prior approaches often compute information gain at discrete waypoints, pathwise integration offers a more comprehensive estimation but is often computationally challenging or infeasible and prone to overestimation. In this work, we propose the Pathwise Information Gain with Map Prediction for Exploration (PIPE) planner, which integrates cumulative sensor coverage along planned trajectories while leveraging map prediction to mitigate overestimation. To enable efficient pathwise coverage computation, we introduce a method to efficiently calculate the expected observation mask along the planned path, significantly reducing computational overhead. We validate PIPE on real-world floorplan datasets, demonstrating its superior performance over state-of-the-art baselines. Our results highlight the benefits of integrating predictive mapping with pathwise information gain for efficient and informed exploration.
MapExRL: Human-Inspired Indoor Exploration with Predicted Environment Context and Reinforcement Learning
Mar 03, 2025



Path planning for robotic exploration is challenging, requiring reasoning over unknown spaces and anticipating future observations. Efficient exploration requires selecting budget-constrained paths that maximize information gain. Despite advances in autonomous exploration, existing algorithms still fall short of human performance, particularly in structured environments where predictive cues exist but are underutilized. Guided by insights from our user study, we introduce MapExRL, which improves robot exploration efficiency in structured indoor environments by enabling longer-horizon planning through reinforcement learning (RL) and global map predictions. Unlike many RL-based exploration methods that use motion primitives as the action space, our approach leverages frontiers for more efficient model learning and longer horizon reasoning. Our framework generates global map predictions from the observed map, which our policy utilizes, along with the prediction uncertainty, estimated sensor coverage, frontier distance, and remaining distance budget, to assess the strategic long-term value of frontiers. By leveraging multiple frontier scoring methods and additional context, our policy makes more informed decisions at each stage of the exploration. We evaluate our framework on a real-world indoor map dataset, achieving up to an 18.8% improvement over the strongest state-of-the-art baseline, with even greater gains compared to conventional frontier-based algorithms.
SALON: Self-supervised Adaptive Learning for Off-road Navigation
Dec 10, 2024



Autonomous robot navigation in off-road environments presents a number of challenges due to its lack of structure, making it difficult to handcraft robust heuristics for diverse scenarios. While learned methods using hand labels or self-supervised data improve generalizability, they often require a tremendous amount of data and can be vulnerable to domain shifts. To improve generalization in novel environments, recent works have incorporated adaptation and self-supervision to develop autonomous systems that can learn from their own experiences online. However, current works often rely on significant prior data, for example minutes of human teleoperation data for each terrain type, which is difficult to scale with more environments and robots. To address these limitations, we propose SALON, a perception-action framework for fast adaptation of traversability estimates with minimal human input. SALON rapidly learns online from experience while avoiding out of distribution terrains to produce adaptive and risk-aware cost and speed maps. Within seconds of collected experience, our results demonstrate comparable navigation performance over kilometer-scale courses in diverse off-road terrain as methods trained on 100-1000x more data. We additionally show promising results on significantly different robots in different environments. Our code is available at https://theairlab.org/SALON.
Map It Anywhere (MIA): Empowering Bird's Eye View Mapping using Large-scale Public Data
Jul 11, 2024



Top-down Bird's Eye View (BEV) maps are a popular representation for ground robot navigation due to their richness and flexibility for downstream tasks. While recent methods have shown promise for predicting BEV maps from First-Person View (FPV) images, their generalizability is limited to small regions captured by current autonomous vehicle-based datasets. In this context, we show that a more scalable approach towards generalizable map prediction can be enabled by using two large-scale crowd-sourced mapping platforms, Mapillary for FPV images and OpenStreetMap for BEV semantic maps. We introduce Map It Anywhere (MIA), a data engine that enables seamless curation and modeling of labeled map prediction data from existing open-source map platforms. Using our MIA data engine, we display the ease of automatically collecting a dataset of 1.2 million pairs of FPV images & BEV maps encompassing diverse geographies, landscapes, environmental factors, camera models & capture scenarios. We further train a simple camera model-agnostic model on this data for BEV map prediction. Extensive evaluations using established benchmarks and our dataset show that the data curated by MIA enables effective pretraining for generalizable BEV map prediction, with zero-shot performance far exceeding baselines trained on existing datasets by 35%. Our analysis highlights the promise of using large-scale public maps for developing & testing generalizable BEV perception, paving the way for more robust autonomous navigation.
Deep Bayesian Future Fusion for Self-Supervised, High-Resolution, Off-Road Mapping
Mar 18, 2024



The limited sensing resolution of resource-constrained off-road vehicles poses significant challenges towards reliable off-road autonomy. To overcome this limitation, we propose a general framework based on fusing the future information (i.e. future fusion) for self-supervision. Recent approaches exploit this future information alongside the hand-crafted heuristics to directly supervise the targeted downstream tasks (e.g. traversability estimation). However, in this paper, we opt for a more general line of development - time-efficient completion of the highest resolution (i.e. 2cm per pixel) BEV map in a self-supervised manner via future fusion, which can be used for any downstream tasks for better longer range prediction. To this end, first, we create a high-resolution future-fusion dataset containing pairs of (RGB / height) raw sparse and noisy inputs and map-based dense labels. Next, to accommodate the noise and sparsity of the sensory information, especially in the distal regions, we design an efficient realization of the Bayes filter onto the vanilla convolutional network via the recurrent mechanism. Equipped with the ideas from SOTA generative models, our Bayesian structure effectively predicts high-quality BEV maps in the distal regions. Extensive evaluation on both the quality of completion and downstream task on our future-fusion dataset demonstrates the potential of our approach.
Learning-on-the-Drive: Self-supervised Adaptation of Visual Offroad Traversability Models
Jun 27, 2023



Autonomous off-road driving requires understanding traversability, which refers to the suitability of a given terrain to drive over. When offroad vehicles travel at high speed ($>10m/s$), they need to reason at long-range ($50m$-$100m$) for safe and deliberate navigation. Moreover, vehicles often operate in new environments and under different weather conditions. LiDAR provides accurate estimates robust to visual appearances, however, it is often too noisy beyond 30m for fine-grained estimates due to sparse measurements. Conversely, visual-based models give dense predictions at further distances but perform poorly at all ranges when out of training distribution. To address these challenges, we present ALTER, an offroad perception module that adapts-on-the-drive to combine the best of both sensors. Our visual model continuously learns from new near-range LiDAR measurements. This self-supervised approach enables accurate long-range traversability prediction in novel environments without hand-labeling. Results on two distinct real-world offroad environments show up to 52.5% improvement in traversability estimation over LiDAR-only estimates and 38.1% improvement over non-adaptive visual baseline.
Adaptive Safety Margin Estimation for Safe Real-Time Replanning under Time-Varying Disturbance
Oct 07, 2021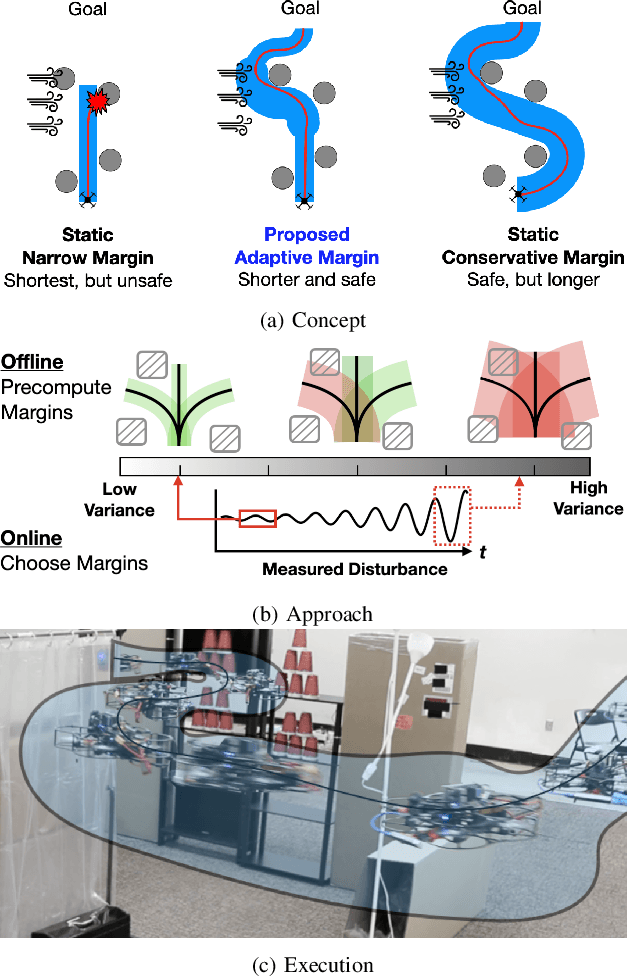
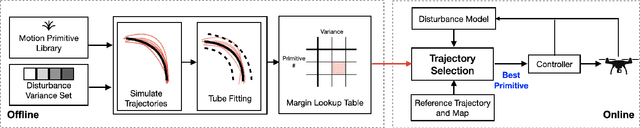
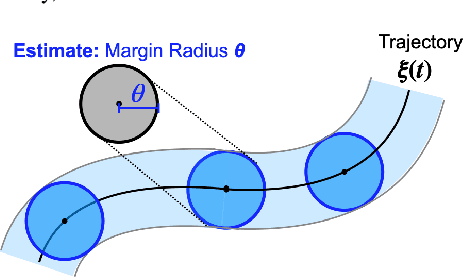
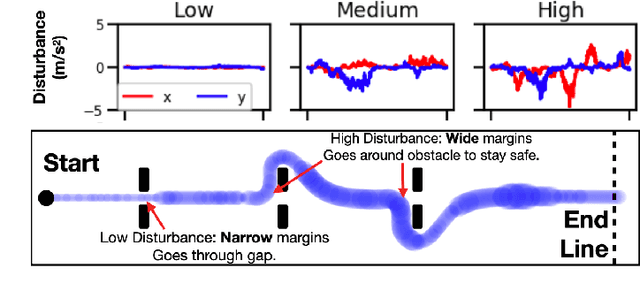
Safe navigation in real-time is challenging because engineers need to work with uncertain vehicle dynamics, variable external disturbances, and imperfect controllers. A common safety strategy is to inflate obstacles by hand-defined margins. However, arbitrary static margins often fail in more dynamic scenarios, and using worst-case assumptions is overly conservative for most settings where disturbances over time. In this work, we propose a middle ground: safety margins that adapt on-the-fly. In an offline phase, we use Monte Carlo simulations to pre-compute a library of safety margins for multiple levels of disturbance uncertainties. Then, at runtime, our system estimates the current disturbance level to query the associated safety margins that best trades off safety and performance. We validate our approach with extensive simulated and real-world flight tests. We show that our adaptive method significantly outperforms static margins, allowing the vehicle to operate up to 1.5 times faster than worst-case static margins while maintaining safety. Video: https://youtu.be/SHzKHSUjdUU
3D Human Reconstruction in the Wild with Collaborative Aerial Cameras
Aug 09, 2021
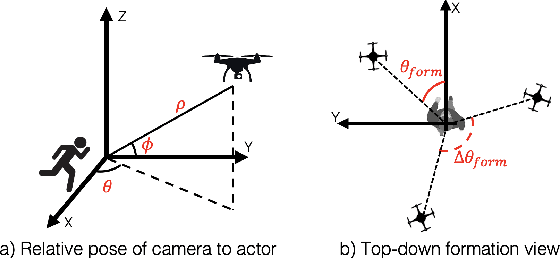
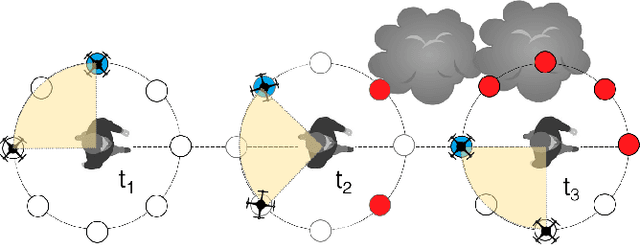

Aerial vehicles are revolutionizing applications that require capturing the 3D structure of dynamic targets in the wild, such as sports, medicine, and entertainment. The core challenges in developing a motion-capture system that operates in outdoors environments are: (1) 3D inference requires multiple simultaneous viewpoints of the target, (2) occlusion caused by obstacles is frequent when tracking moving targets, and (3) the camera and vehicle state estimation is noisy. We present a real-time aerial system for multi-camera control that can reconstruct human motions in natural environments without the use of special-purpose markers. We develop a multi-robot coordination scheme that maintains the optimal flight formation for target reconstruction quality amongst obstacles. We provide studies evaluating system performance in simulation, and validate real-world performance using two drones while a target performs activities such as jogging and playing soccer. Supplementary video: https://youtu.be/jxt91vx0cns
Autonomous Aerial Cinematography In Unstructured Environments With Learned Artistic Decision-Making
Oct 15, 2019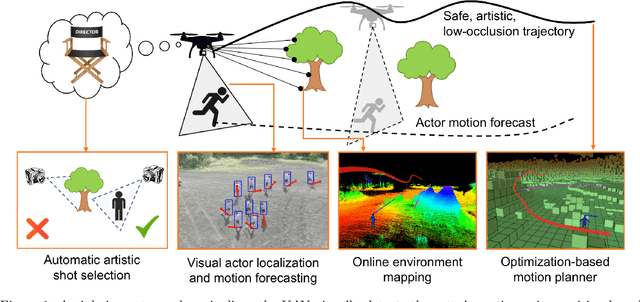
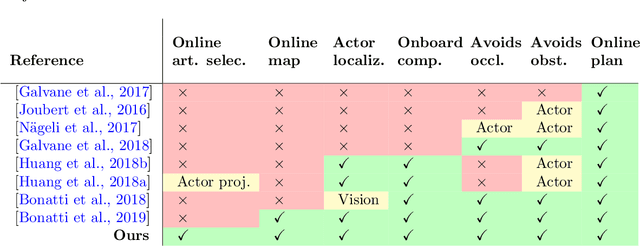
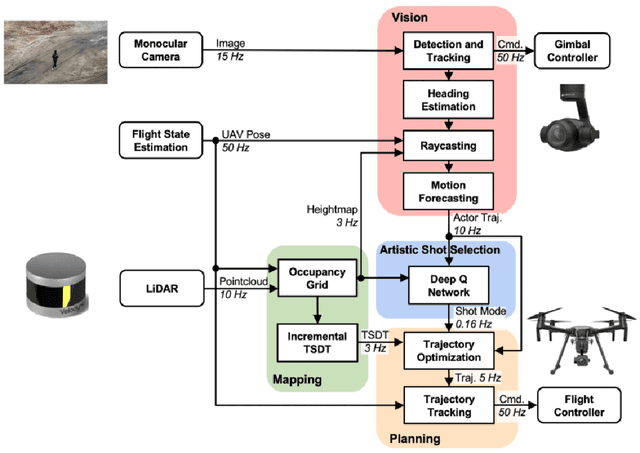

Aerial cinematography is revolutionizing industries that require live and dynamic camera viewpoints such as entertainment, sports, and security. However, safely piloting a drone while filming a moving target in the presence of obstacles is immensely taxing, often requiring multiple expert human operators. Hence, there is demand for an autonomous cinematographer that can reason about both geometry and scene context in real-time. Existing approaches do not address all aspects of this problem; they either require high-precision motion-capture systems or GPS tags to localize targets, rely on prior maps of the environment, plan for short time horizons, or only follow artistic guidelines specified before flight. In this work, we address the problem in its entirety and propose a complete system for real-time aerial cinematography that for the first time combines: (1) vision-based target estimation; (2) 3D signed-distance mapping for occlusion estimation; (3) efficient trajectory optimization for long time-horizon camera motion; and (4) learning-based artistic shot selection. We extensively evaluate our system both in simulation and in field experiments by filming dynamic targets moving through unstructured environments. Our results indicate that our system can operate reliably in the real world without restrictive assumptions. We also provide in-depth analysis and discussions for each module, with the hope that our design tradeoffs can generalize to other related applications. Videos of the complete system can be found at: https://youtu.be/ookhHnqmlaU.