 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPO: Active Multi-Preference Optimization
Feb 25, 2025Multi-preference optimization enriches language-model alignment beyond pairwise preferences by contrasting entire sets of helpful and undesired responses, thereby enabling richer training signals for large language models. During self-play alignment, these models often produce numerous candidate answers per query, rendering it computationally infeasible to include all responses in the training objective. In this work, we propose $\textit{Active Multi-Preference Optimization}$ (AMPO), a novel approach that combines on-policy generation, a multi-preference group-contrastive loss, and active subset selection. Specifically, we score and embed large candidate pools of responses and then select a small, yet informative, subset that covers reward extremes and distinct semantic clusters for preference optimization. Our contrastive training scheme is capable of identifying not only the best and worst answers but also subtle, underexplored modes that are crucial for robust alignment. Theoretically, we provide guarantees for expected reward maximization using our active selection method, and empirically, AMPO achieves state-of-the-art results on $\textit{AlpacaEval}$ using Llama 8B.
REFA: Reference Free Alignment for multi-preference optimization
Dec 20, 2024We introduce REFA, a family of reference-free alignment methods that optimize over multiple user preferences while enforcing fine-grained length control. Our approach integrates deviation-based weighting to emphasize high-quality responses more strongly, length normalization to prevent trivial short-response solutions, and an EOS-probability regularizer to mitigate dataset-induced brevity biases. Theoretically, we show that under the Uncertainty Reduction with Sequence Length Assertion (URSLA), naive length normalization can still incentivize length-based shortcuts. By contrast, REFA corrects these subtle incentives, guiding models toward genuinely more informative and higher-quality outputs. Empirically, REFA sets a new state-of-the-art among reference-free alignment methods, producing richer responses aligned more closely with human preferences. Compared to a base supervised fine-tuned (SFT) mistral-7b model that achieves 8.4% length-controlled win rate (LC-WR) and 6.2% win rate (WR), our best REFA configuration attains 21.62% LC-WR and 19.87% WR on the AlpacaEval v2 benchmark. This represents a substantial improvement over both the strongest multi-preference baseline, InfoNCA (16.82% LC-WR, 10.44% WR), and the strongest reference-free baseline, SimPO (20.01% LC-WR, 17.65% WR)
SWEPO: Simultaneous Weighted Preference Optimization for Group Contrastive Alignment
Dec 05, 2024We introduce Simultaneous Weighted Preference Optimization (SWEPO), a novel extension of Direct Preference Optimization (DPO) designed to accommodate multiple dynamically chosen positive and negative responses for each query. SWEPO employs a weighted group contrastive loss, assigning weights to responses based on their deviation from the mean reward score. This approach effectively prioritizes responses that are significantly better or worse than the average, enhancing optimization. Our theoretical analysis demonstrates that simultaneously considering multiple preferences reduces alignment bias, resulting in more robust alignment. Additionally, we provide insights into the training dynamics of our loss function and a related function, InfoNCA. Empirical validation on the UltraFeedback dataset establishes SWEPO as state-of-the-art, with superior performance in downstream evaluations using the AlpacaEval dataset.
Unveiling Context-Aware Criteria in Self-Assessing LLMs
Oct 28, 2024



The use of large language models (LLMs) as evaluators has garnered significant attention due to their potential to rival human-level evaluations in long-form response assessments. However, current LLM evaluators rely heavily on static, human-defined criteria, limiting their ability to generalize across diverse generative tasks and incorporate context-specific knowledge. In this paper, we propose a novel Self-Assessing LLM framework that integrates Context-Aware Criteria (SALC) with dynamic knowledge tailored to each evaluation instance. This instance-level knowledge enhances the LLM evaluator's performance by providing relevant and context-aware insights that pinpoint the important criteria specific to the current instance. Additionally, the proposed framework adapts seamlessly to various tasks without relying on predefined human criteria, offering a more flexible evaluation approach. Empirical evaluations demonstrate that our approach significantly outperforms existing baseline evaluation frameworks, yielding improvements on average 4.8% across a wide variety of datasets. Furthermore, by leveraging knowledge distillation techniques, we fine-tuned smaller language models for criteria generation and evaluation, achieving comparable or superior performance to larger models with much lower cost. Our method also exhibits a improvement in LC Win-Rate in AlpacaEval2 leaderboard up to a 12% when employed for preference data generation in Direct Preference Optimization (DPO), underscoring its efficacy as a robust and scalable evaluation framework.
Map It Anywhere (MIA): Empowering Bird's Eye View Mapping using Large-scale Public Data
Jul 11, 2024



Top-down Bird's Eye View (BEV) maps are a popular representation for ground robot navigation due to their richness and flexibility for downstream tasks. While recent methods have shown promise for predicting BEV maps from First-Person View (FPV) images, their generalizability is limited to small regions captured by current autonomous vehicle-based datasets. In this context, we show that a more scalable approach towards generalizable map prediction can be enabled by using two large-scale crowd-sourced mapping platforms, Mapillary for FPV images and OpenStreetMap for BEV semantic maps. We introduce Map It Anywhere (MIA), a data engine that enables seamless curation and modeling of labeled map prediction data from existing open-source map platforms. Using our MIA data engine, we display the ease of automatically collecting a dataset of 1.2 million pairs of FPV images & BEV maps encompassing diverse geographies, landscapes, environmental factors, camera models & capture scenarios. We further train a simple camera model-agnostic model on this data for BEV map prediction. Extensive evaluations using established benchmarks and our dataset show that the data curated by MIA enables effective pretraining for generalizable BEV map prediction, with zero-shot performance far exceeding baselines trained on existing datasets by 35%. Our analysis highlights the promise of using large-scale public maps for developing & testing generalizable BEV perception, paving the way for more robust autonomous navigation.
On designing light-weight object trackers through network pruning: Use CNNs or transformers?
Nov 24, 2022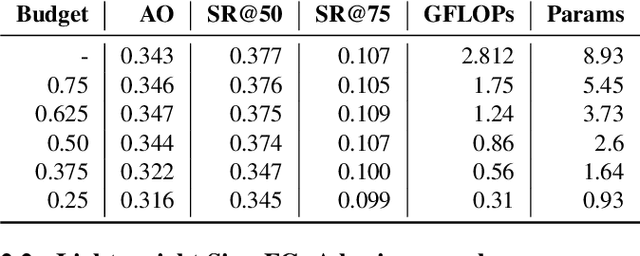
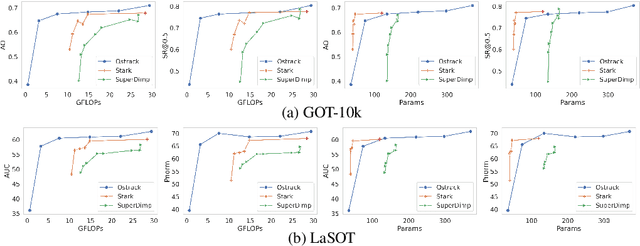


Object trackers deployed on low-power devices need to be light-weight, however, most of the current state-of-the-art (SOTA) methods rely on using compute-heavy backbones built using CNNs or transformers. Large sizes of such models do not allow their deployment in low-power conditions and designing compressed variants of large tracking models is of great importance. This paper demonstrates how highly compressed light-weight object trackers can be designed using neural architectural pruning of large CNN and transformer based trackers. Further, a comparative study on architectural choices best suited to design light-weight trackers is provided. A comparison between SOTA trackers using CNNs, transformers as well as the combination of the two is presented to study their stability at various compression ratios. Finally results for extreme pruning scenarios going as low as 1% in some cases are shown to study the limits of network pruning in object tracking. This work provides deeper insights into designing highly efficient trackers from existing SOTA methods.
GPTs at Factify 2022: Prompt Aided Fact-Verification
Jun 29, 2022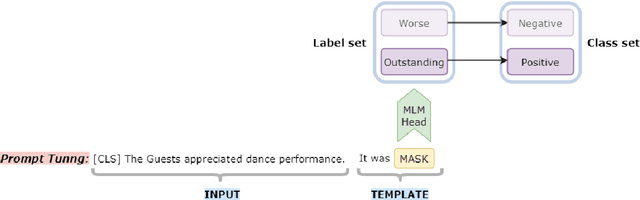


One of the most pressing societal issues is the fight against false news. The false claims, as difficult as they are to expose, create a lot of damage. To tackle the problem, fact verification becomes crucial and thus has been a topic of interest among diverse research communities. Using only the textual form of data we propose our solution to the problem and achieve competitive results with other approaches. We present our solution based on two approaches - PLM (pre-trained language model) based method and Prompt based method. The PLM-based approach uses the traditional supervised learning, where the model is trained to take 'x' as input and output prediction 'y' as P(y|x). Whereas, Prompt-based learning reflects the idea to design input to fit the model such that the original objective may be re-framed as a problem of (masked) language modeling. We may further stimulate the rich knowledge provided by PLMs to better serve downstream tasks by employing extra prompts to fine-tune PLMs. Our experiments showed that the proposed method performs better than just fine-tuning PLMs. We achieved an F1 score of 0.6946 on the FACTIFY dataset and a 7th position on the competition leader-board.