 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMABNet: Master Assistant Buddy Network with Hybrid Learning for Image Retrieval
Mar 06, 2023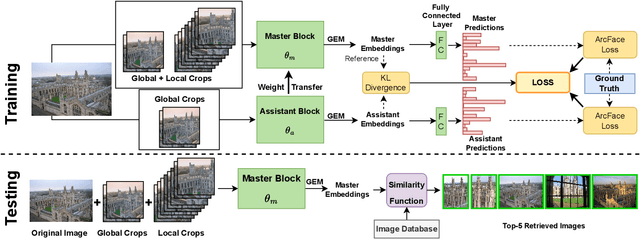


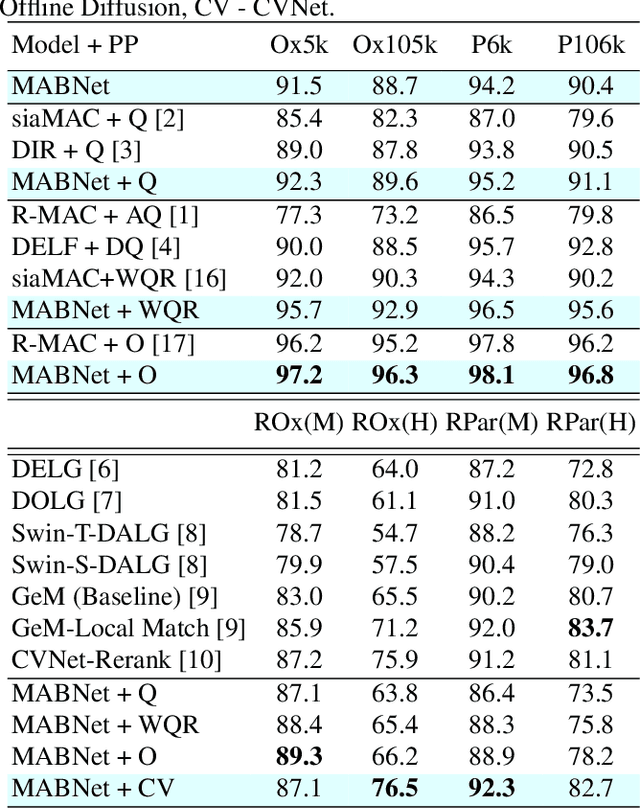
Image retrieval has garnered growing interest in recent times. The current approaches are either supervised or self-supervised. These methods do not exploit the benefits of hybrid learning using both supervision and self-supervision. We present a novel Master Assistant Buddy Network (MABNet) for image retrieval which incorporates both learning mechanisms. MABNet consists of master and assistant blocks, both learning independently through supervision and collectively via self-supervision. The master guides the assistant by providing its knowledge base as a reference for self-supervision and the assistant reports its knowledge back to the master by weight transfer. We perform extensive experiments on public datasets with and without post-processing.
MAViC: Multimodal Active Learning for Video Captioning
Dec 11, 2022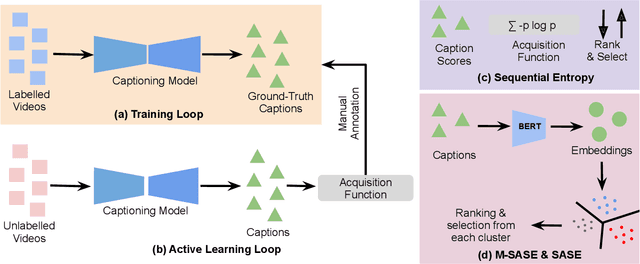

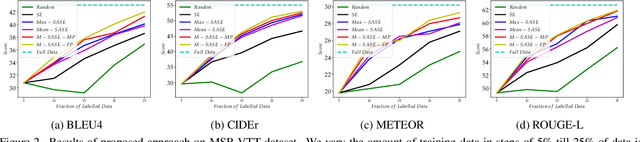
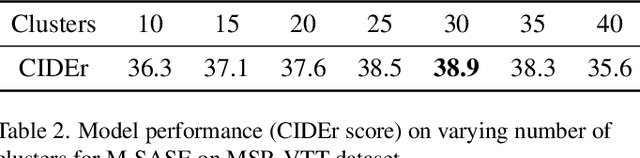
A large number of annotated video-caption pairs are required for training video captioning models, resulting in high annotation costs. Active learning can be instrumental in reducing these annotation requirements. However, active learning for video captioning is challenging because multiple semantically similar captions are valid for a video, resulting in high entropy outputs even for less-informative samples. Moreover, video captioning algorithms are multimodal in nature with a visual encoder and language decoder. Further, the sequential and combinatorial nature of the output makes the problem even more challenging. In this paper, we introduce MAViC which leverages our proposed Multimodal Semantics Aware Sequential Entropy (M-SASE) based acquisition function to address the challenges of active learning approaches for video captioning. Our approach integrates semantic similarity and uncertainty of both visual and language dimensions in the acquisition function. Our detailed experiments empirically demonstrate the efficacy of M-SASE for active learning for video captioning and improve on the baselines by a large margin.
GPTs at Factify 2022: Prompt Aided Fact-Verification
Jun 29, 2022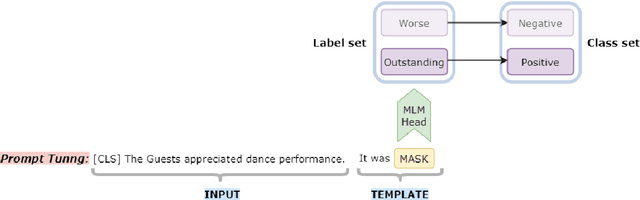


One of the most pressing societal issues is the fight against false news. The false claims, as difficult as they are to expose, create a lot of damage. To tackle the problem, fact verification becomes crucial and thus has been a topic of interest among diverse research communities. Using only the textual form of data we propose our solution to the problem and achieve competitive results with other approaches. We present our solution based on two approaches - PLM (pre-trained language model) based method and Prompt based method. The PLM-based approach uses the traditional supervised learning, where the model is trained to take 'x' as input and output prediction 'y' as P(y|x). Whereas, Prompt-based learning reflects the idea to design input to fit the model such that the original objective may be re-framed as a problem of (masked) language modeling. We may further stimulate the rich knowledge provided by PLMs to better serve downstream tasks by employing extra prompts to fine-tune PLMs. Our experiments showed that the proposed method performs better than just fine-tuning PLMs. We achieved an F1 score of 0.6946 on the FACTIFY dataset and a 7th position on the competition leader-board.