 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAViC: Multimodal Active Learning for Video Captioning
Dec 11, 2022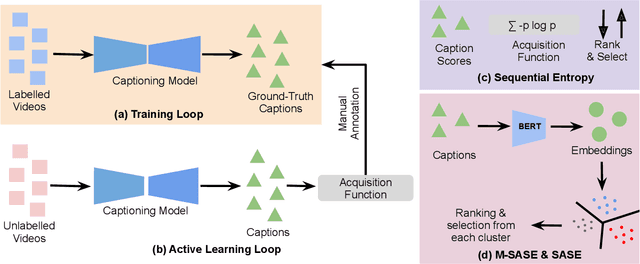

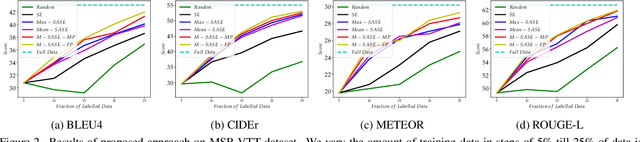
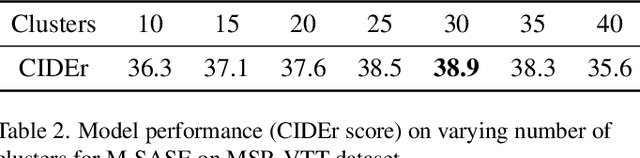
A large number of annotated video-caption pairs are required for training video captioning models, resulting in high annotation costs. Active learning can be instrumental in reducing these annotation requirements. However, active learning for video captioning is challenging because multiple semantically similar captions are valid for a video, resulting in high entropy outputs even for less-informative samples. Moreover, video captioning algorithms are multimodal in nature with a visual encoder and language decoder. Further, the sequential and combinatorial nature of the output makes the problem even more challenging. In this paper, we introduce MAViC which leverages our proposed Multimodal Semantics Aware Sequential Entropy (M-SASE) based acquisition function to address the challenges of active learning approaches for video captioning. Our approach integrates semantic similarity and uncertainty of both visual and language dimensions in the acquisition function. Our detailed experiments empirically demonstrate the efficacy of M-SASE for active learning for video captioning and improve on the baselines by a large margin.
Multilingual and Multimodal Abuse Detection
Apr 03, 2022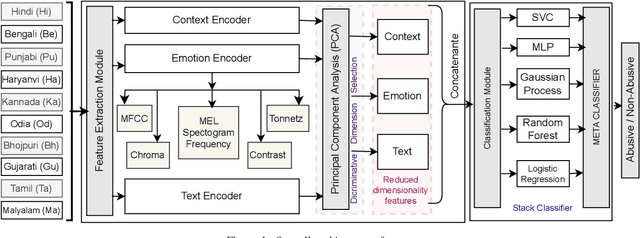
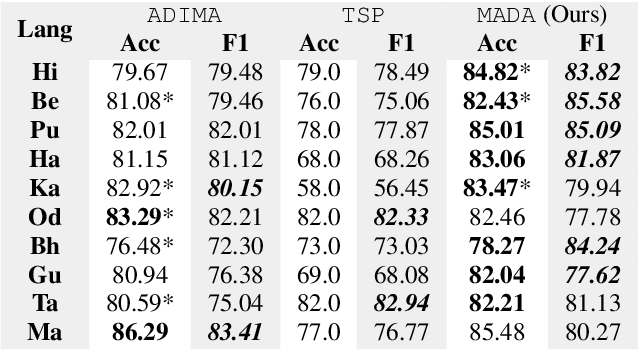
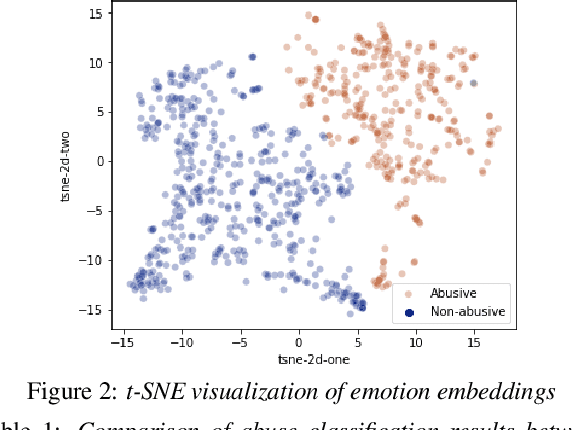
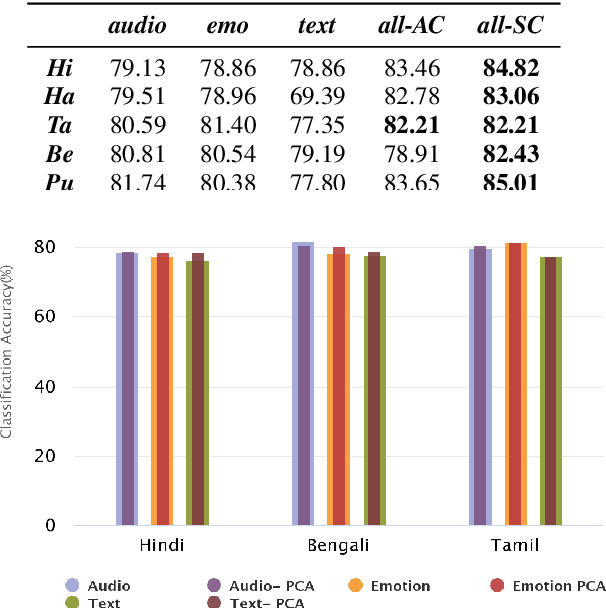
The presence of abusive content on social media platforms is undesirable as it severely impedes healthy and safe social media interactions. While automatic abuse detection has been widely explored in textual domain, audio abuse detection still remains unexplored. In this paper, we attempt abuse detection in conversational audio from a multimodal perspective in a multilingual social media setting. Our key hypothesis is that along with the modelling of audio, incorporating discriminative information from other modalities can be highly beneficial for this task. Our proposed method, MADA, explicitly focuses on two modalities other than the audio itself, namely, the underlying emotions expressed in the abusive audio and the semantic information encapsulated in the corresponding textual form. Observations prove that MADA demonstrates gains over audio-only approaches on the ADIMA dataset. We test the proposed approach on 10 different languages and observe consistent gains in the range 0.6%-5.2% by leveraging multiple modalities. We also perform extensive ablation experiments for studying the contributions of every modality and observe the best results while leveraging all the modalities together. Additionally, we perform experiments to empirically confirm that there is a strong correlation between underlying emotions and abusive behaviour.
3MASSIV: Multilingual, Multimodal and Multi-Aspect dataset of Social Media Short Videos
Mar 28, 2022



We present 3MASSIV, a multilingual, multimodal and multi-aspect, expertly-annotated dataset of diverse short videos extracted from short-video social media platform - Moj. 3MASSIV comprises of 50k short videos (20 seconds average duration) and 100K unlabeled videos in 11 different languages and captures popular short video trends like pranks, fails, romance, comedy expressed via unique audio-visual formats like self-shot videos, reaction videos, lip-synching, self-sung songs, etc. 3MASSIV presents an opportunity for multimodal and multilingual semantic understanding on these unique videos by annotating them for concepts, affective states, media types, and audio language. We present a thorough analysis of 3MASSIV and highlight the variety and unique aspects of our dataset compared to other contemporary popular datasets with strong baselines. We also show how the social media content in 3MASSIV is dynamic and temporal in nature, which can be used for semantic understanding tasks and cross-lingual analysis.
ADIMA: Abuse Detection In Multilingual Audio
Feb 16, 2022
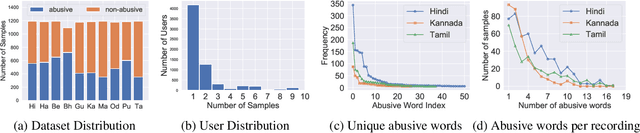
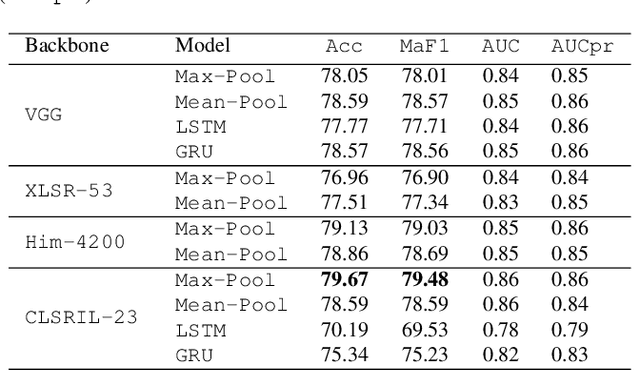
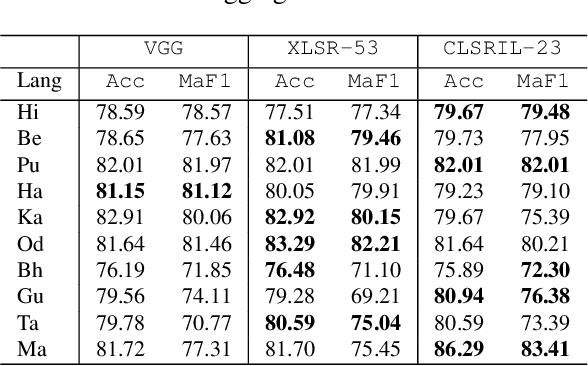
Abusive content detection in spoken text can be addressed by performing Automatic Speech Recognition (ASR) and leveraging advancements in natural language processing. However, ASR models introduce latency and often perform sub-optimally for profane words as they are underrepresented in training corpora and not spoken clearly or completely. Exploration of this problem entirely in the audio domain has largely been limited by the lack of audio datasets. Building on these challenges, we propose ADIMA, a novel, linguistically diverse, ethically sourced, expert annotated and well-balanced multilingual profanity detection audio dataset comprising of 11,775 audio samples in 10 Indic languages spanning 65 hours and spoken by 6,446 unique users. Through quantitative experiments across monolingual and cross-lingual zero-shot settings, we take the first step in democratizing audio based content moderation in Indic languages and set forth our dataset to pave future work.
Multilingual and Multilabel Emotion Recognition using Virtual Adversarial Training
Nov 11, 2021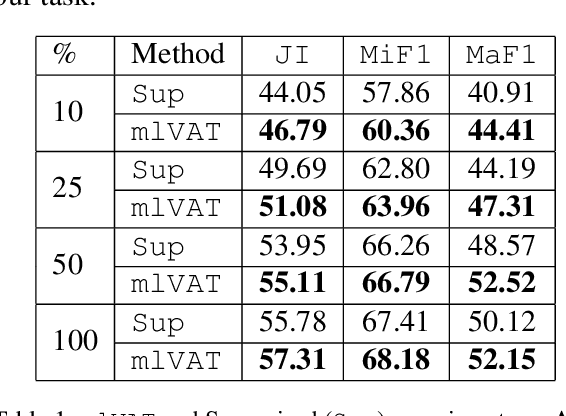
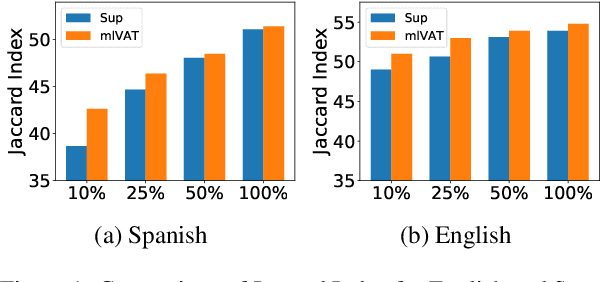

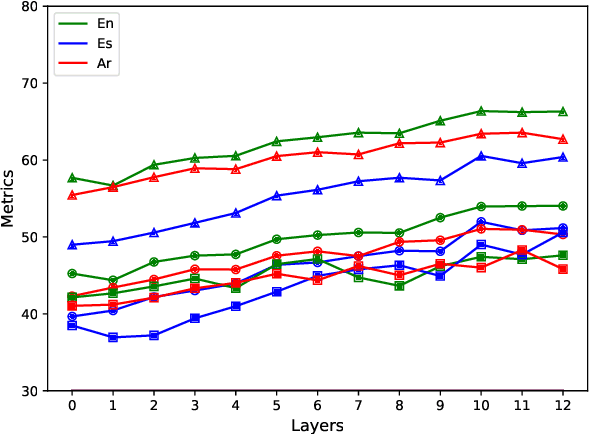
Virtual Adversarial Training (VAT) has been effective in learning robust models under supervised and semi-supervised settings for both computer vision and NLP tasks. However, the efficacy of VAT for multilingual and multilabel text classification has not been explored before. In this work, we explore VAT for multilabel emotion recognition with a focus on leveraging unlabelled data from different languages to improve the model performance. We perform extensive semi-supervised experiments on SemEval2018 multilabel and multilingual emotion recognition dataset and show performance gains of 6.2% (Arabic), 3.8% (Spanish) and 1.8% (English) over supervised learning with same amount of labelled data (10% of training data). We also improve the existing state-of-the-art by 7%, 4.5% and 1% (Jaccard Index) for Spanish, Arabic and English respectively and perform probing experiments for understanding the impact of different layers of the contextual models.
MeGA-CDA: Memory Guided Attention for Category-Aware Unsupervised Domain Adaptive Object Detection
Apr 03, 2021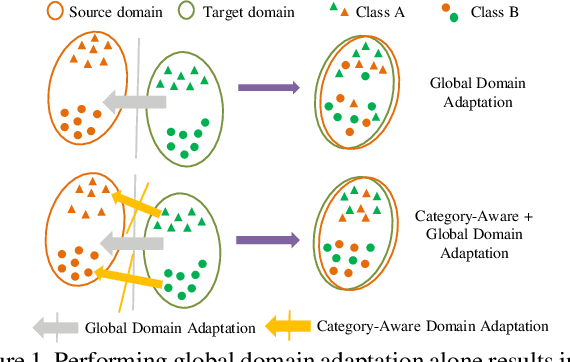
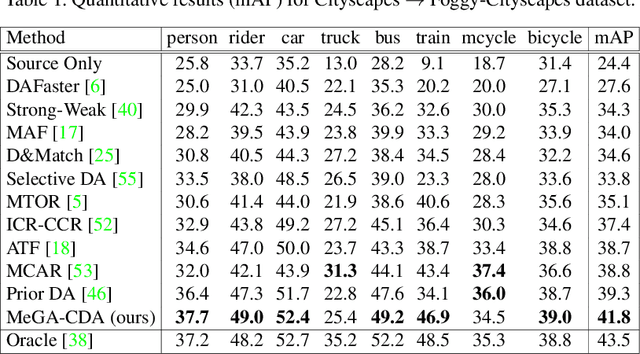
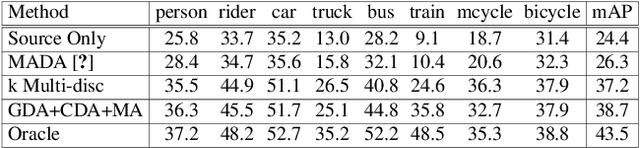
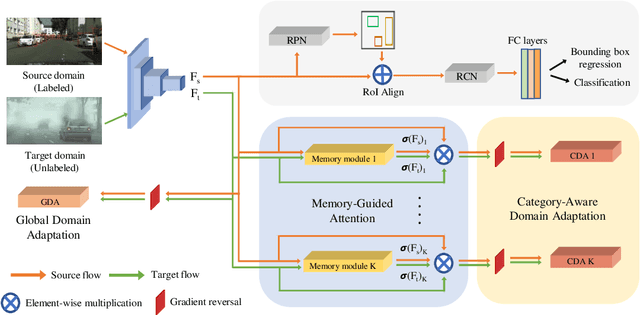
Existing approaches for unsupervised domain adaptive object detection perform feature alignment via adversarial training. While these methods achieve reasonable improvements in performance, they typically perform category-agnostic domain alignment, thereby resulting in negative transfer of features. To overcome this issue, in this work, we attempt to incorporate category information into the domain adaptation process by proposing Memory Guided Attention for Category-Aware Domain Adaptation (MeGA-CDA). The proposed method consists of employing category-wise discriminators to ensure category-aware feature alignment for learning domain-invariant discriminative features. However, since the category information is not available for the target samples, we propose to generate memory-guided category-specific attention maps which are then used to route the features appropriately to the corresponding category discriminator. The proposed method is evaluated on several benchmark datasets and is shown to outperform existing approaches.
End-to-End Differentiable 6DoF Object Pose Estimation with Local and Global Constraints
Nov 22, 2020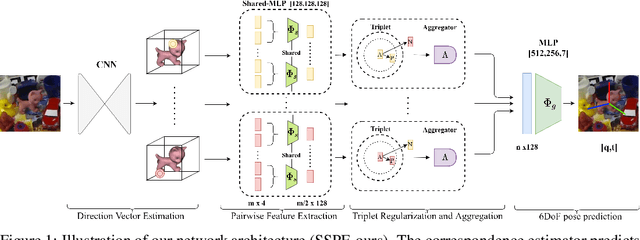
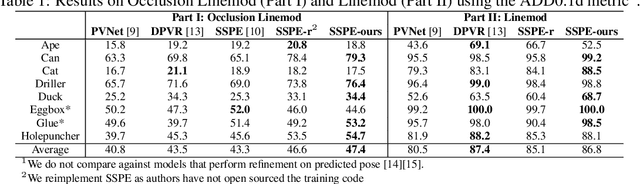

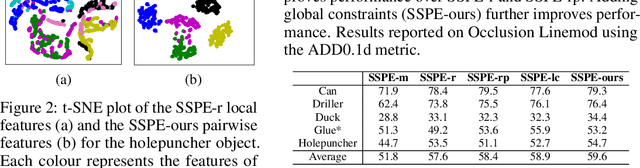
Inferring the 6DoF pose of an object from a single RGB image is an important but challenging task, especially under heavy occlusion. While recent approaches improve upon the two stage approaches by training an end-to-end pipeline, they do not leverage local and global constraints. In this paper, we propose pairwise feature extraction to integrate local constraints, and triplet regularization to integrate global constraints for improved 6DoF object pose estimation. Coupled with better augmentation, our approach achieves state of the art results on the challenging Occlusion Linemod dataset, with a 9% improvement over the previous state of the art, and achieves competitive results on the Linemod dataset.
Clustering Contextualized Representations of Text for Unsupervised Syntax Induction
Oct 24, 2020
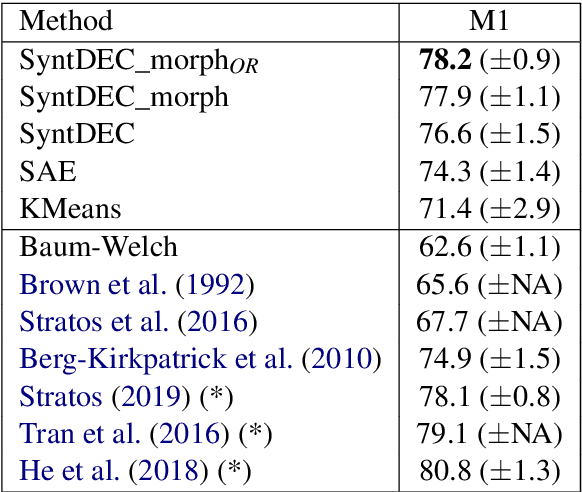
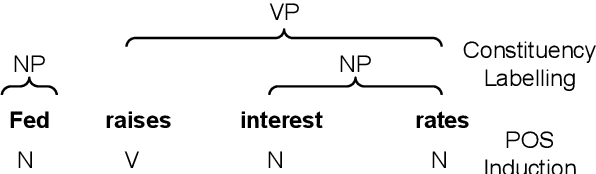
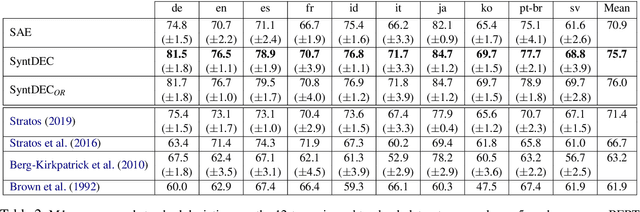
We explore clustering of contextualized text representations for two unsupervised syntax induction tasks: part of speech induction (POSI) and constituency labelling (CoLab). We propose a deep embedded clustering approach which jointly transforms these representations into a lower dimension cluster friendly space and clusters them. We further enhance these representations by augmenting them with task-specific representations. We also explore the effectiveness of multilingual representations for different tasks and languages. With this work, we establish the first strong baselines for unsupervised syntax induction using contextualized text representations. We report competitive performance on 45-tag POSI, state-of-the-art performance on 12-tag POSI across 10 languages, and competitive results on CoLab.
ProtoGAN: Towards Few Shot Learning for Action Recognition
Sep 17, 2019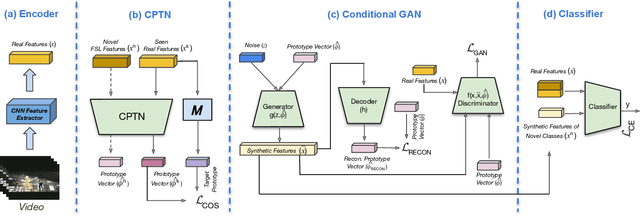
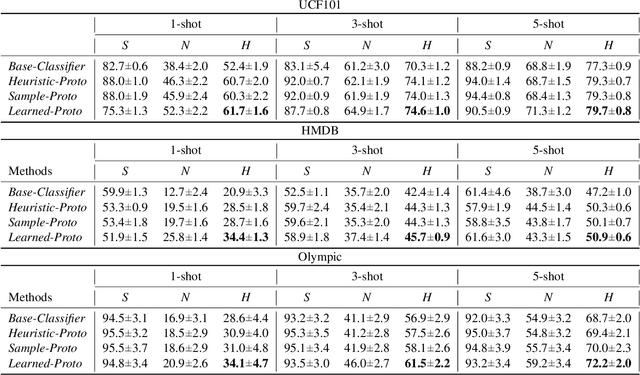
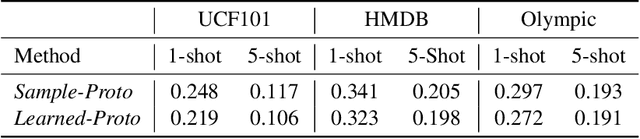
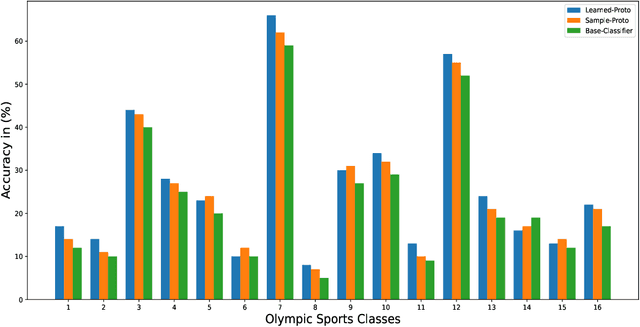
Few-shot learning (FSL) for action recognition is a challenging task of recognizing novel action categories which are represented by few instances in the training data. In a more generalized FSL setting (G-FSL), both seen as well as novel action categories need to be recognized. Conventional classifiers suffer due to inadequate data in FSL setting and inherent bias towards seen action categories in G-FSL setting. In this paper, we address this problem by proposing a novel ProtoGAN framework which synthesizes additional examples for novel categories by conditioning a conditional generative adversarial network with class prototype vectors. These class prototype vectors are learnt using a Class Prototype Transfer Network (CPTN) from examples of seen categories. Our synthesized examples for a novel class are semantically similar to real examples belonging to that class and is used to train a model exhibiting better generalization towards novel classes. We support our claim by performing extensive experiments on three datasets: UCF101, HMDB51 and Olympic-Sports. To the best of our knowledge, we are the first to report the results for G-FSL and provide a strong benchmark for future research. We also outperform the state-of-the-art method in FSL for all the aforementioned datasets.
Progression Modelling for Online and Early Gesture Detection
Sep 14, 2019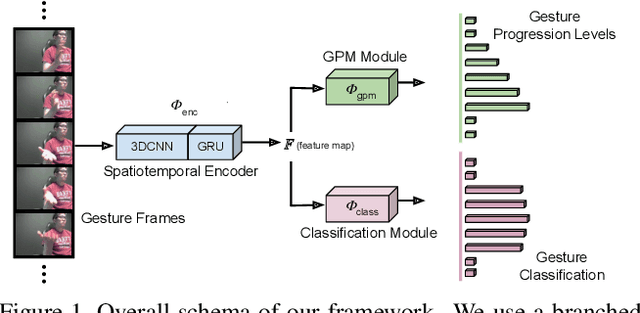
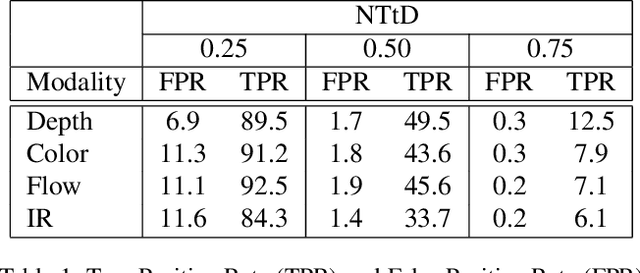

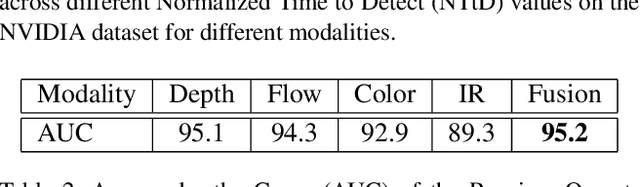
Online and Early detection of gestures is crucial for building touchless gesture based interfaces. These interfaces should operate on a stream of video frames instead of the complete video and detect the presence of gestures at an earlier stage than post-completion for providing real time user experience. To achieve this, it is important to recognize the progression of the gesture across different stages so that appropriate responses can be triggered on reaching the desired execution stage. To address this, we propose a simple yet effective multi-task learning framework which models the progression of the gesture along with frame level recognition. The proposed framework recognizes the gestures at an early stage with high precision and also achieves state-of-the-art recognition accuracy of 87.8% which is closer to human accuracy of 88.4% on the NVIDIA gesture dataset in the offline configuration and advances the state-of-the-art by more than 4%. We also introduce tightly segmented annotations for the NVIDIA gesture dataset and setup a strong baseline for gesture localization for this dataset. We also evaluate our framework on the Montalbano dataset and report competitive results.