 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Multimodal Abuse Detection
Apr 03, 2022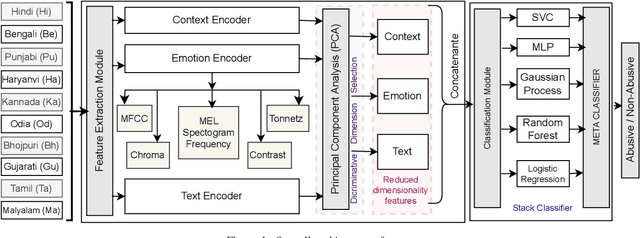
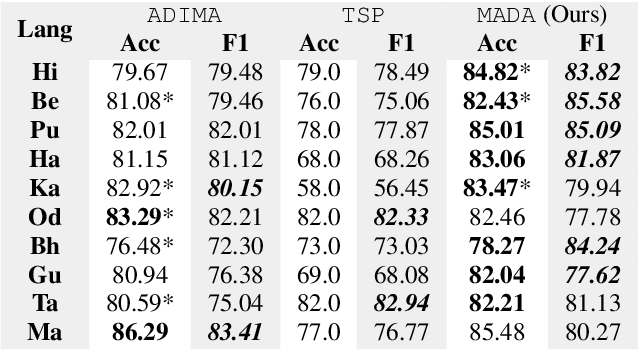
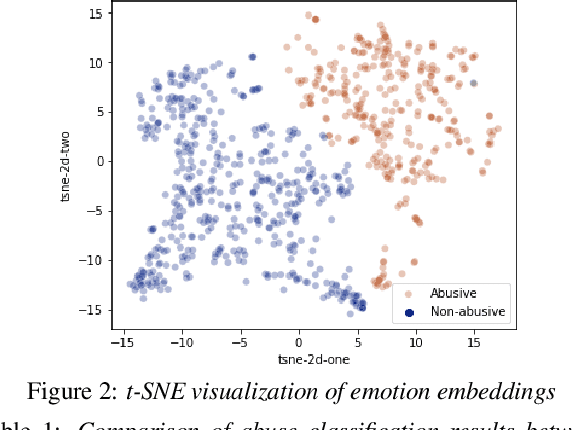
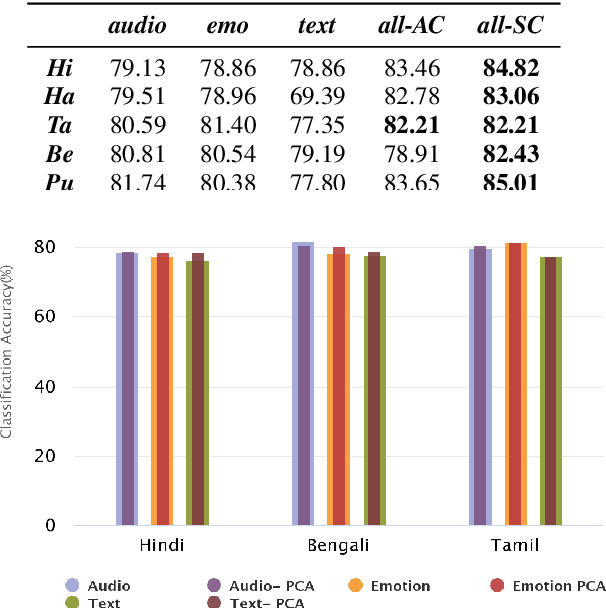
The presence of abusive content on social media platforms is undesirable as it severely impedes healthy and safe social media interactions. While automatic abuse detection has been widely explored in textual domain, audio abuse detection still remains unexplored. In this paper, we attempt abuse detection in conversational audio from a multimodal perspective in a multilingual social media setting. Our key hypothesis is that along with the modelling of audio, incorporating discriminative information from other modalities can be highly beneficial for this task. Our proposed method, MADA, explicitly focuses on two modalities other than the audio itself, namely, the underlying emotions expressed in the abusive audio and the semantic information encapsulated in the corresponding textual form. Observations prove that MADA demonstrates gains over audio-only approaches on the ADIMA dataset. We test the proposed approach on 10 different languages and observe consistent gains in the range 0.6%-5.2% by leveraging multiple modalities. We also perform extensive ablation experiments for studying the contributions of every modality and observe the best results while leveraging all the modalities together. Additionally, we perform experiments to empirically confirm that there is a strong correlation between underlying emotions and abusive behaviour.
3MASSIV: Multilingual, Multimodal and Multi-Aspect dataset of Social Media Short Videos
Mar 28, 2022



We present 3MASSIV, a multilingual, multimodal and multi-aspect, expertly-annotated dataset of diverse short videos extracted from short-video social media platform - Moj. 3MASSIV comprises of 50k short videos (20 seconds average duration) and 100K unlabeled videos in 11 different languages and captures popular short video trends like pranks, fails, romance, comedy expressed via unique audio-visual formats like self-shot videos, reaction videos, lip-synching, self-sung songs, etc. 3MASSIV presents an opportunity for multimodal and multilingual semantic understanding on these unique videos by annotating them for concepts, affective states, media types, and audio language. We present a thorough analysis of 3MASSIV and highlight the variety and unique aspects of our dataset compared to other contemporary popular datasets with strong baselines. We also show how the social media content in 3MASSIV is dynamic and temporal in nature, which can be used for semantic understanding tasks and cross-lingual analysis.
ADIMA: Abuse Detection In Multilingual Audio
Feb 16, 2022
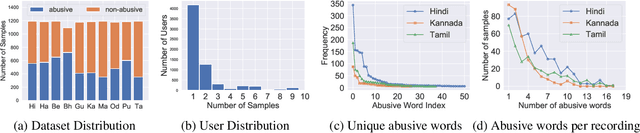
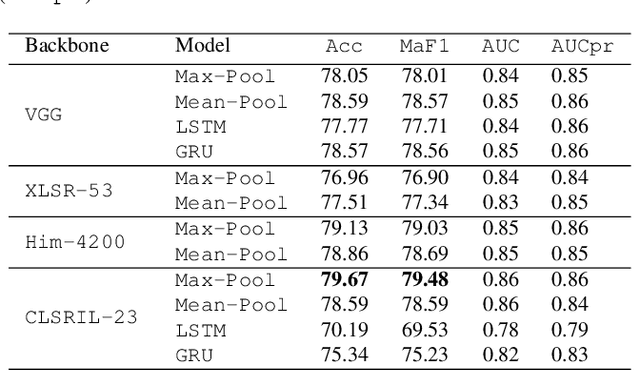
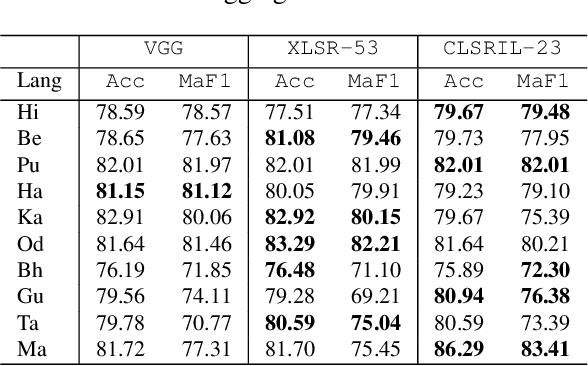
Abusive content detection in spoken text can be addressed by performing Automatic Speech Recognition (ASR) and leveraging advancements in natural language processing. However, ASR models introduce latency and often perform sub-optimally for profane words as they are underrepresented in training corpora and not spoken clearly or completely. Exploration of this problem entirely in the audio domain has largely been limited by the lack of audio datasets. Building on these challenges, we propose ADIMA, a novel, linguistically diverse, ethically sourced, expert annotated and well-balanced multilingual profanity detection audio dataset comprising of 11,775 audio samples in 10 Indic languages spanning 65 hours and spoken by 6,446 unique users. Through quantitative experiments across monolingual and cross-lingual zero-shot settings, we take the first step in democratizing audio based content moderation in Indic languages and set forth our dataset to pave future work.
Understanding Chat Messages for Sticker Recommendation in Hike Messenger
Feb 07, 2019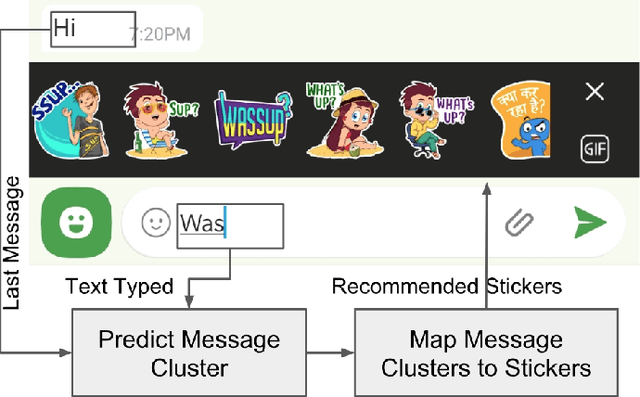


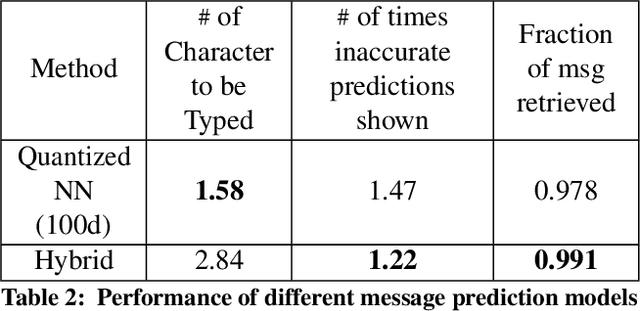
Stickers are popularly used in messaging apps such as Hike to visually express a nuanced range of thoughts and utterances and convey exaggerated emotions. However, discovering the right sticker at the right time in a chat from a large and ever expanding pool of stickers can be cumbersome. In this paper, we describe a system for recommending stickers as users chat based on what the user is typing and the conversational context. We decompose the sticker recommendation problem into two steps. First, we predict the next message that the user is likely to send in the chat. Second, we substitute the predicted message with an appropriate sticker. Majority of Hike's users transliterate messages from their native language to English. This leads to numerous orthographic variations of the same message and thus complicates message prediction. To address this issue, we cluster the messages that have the same meaning and predict the message cluster instead of the message. We experiment with different approaches to train embedding for chat messages and study their efficacy in learning similar dense representations for messages that have the same intent. We propose a novel hybrid message prediction model, which can run with low latency on low end phones that have severe computational limitations.
Heterogeneous Edge Embeddings for Friend Recommendation
Feb 07, 2019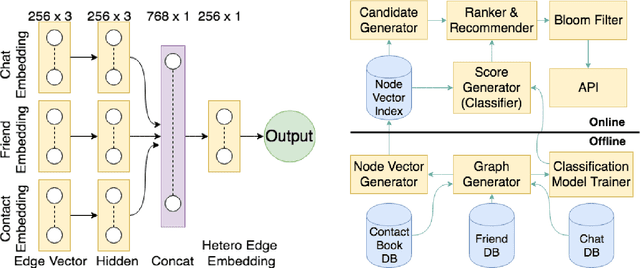
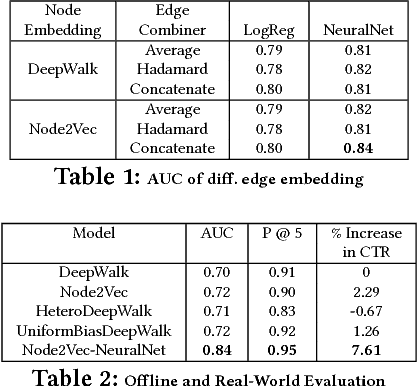
We propose a friend recommendation system (an application of link prediction) using edge embeddings on social networks. Most real-world social networks are multi-graphs, where different kinds of relationships (e.g. chat, friendship) are possible between a pair of users. Existing network embedding techniques do not leverage signals from different edge types and thus perform inadequately on link prediction in such networks. We propose a method to mine network representation that effectively exploits heterogeneity in multi-graphs. We evaluate our model on a real-world, active social network where this system is deployed for friend recommendation for millions of users. Our method outperforms various state-of-the-art baselines on Hike's social network in terms of accuracy as well as user satisfaction.