 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocEdit-v2: Document Structure Editing Via Multimodal LLM Grounding
Oct 21, 2024



Document structure editing involves manipulating localized textual, visual, and layout components in document images based on the user's requests. Past works have shown that multimodal grounding of user requests in the document image and identifying the accurate structural components and their associated attributes remain key challenges for this task. To address these, we introduce the DocEdit-v2, a novel framework that performs end-to-end document editing by leveraging Large Multimodal Models (LMMs). It consists of three novel components: (1) Doc2Command, which simultaneously localizes edit regions of interest (RoI) and disambiguates user edit requests into edit commands; (2) LLM-based Command Reformulation prompting to tailor edit commands originally intended for specialized software into edit instructions suitable for generalist LMMs. (3) Moreover, DocEdit-v2 processes these outputs via Large Multimodal Models like GPT-4V and Gemini, to parse the document layout, execute edits on grounded Region of Interest (RoI), and generate the edited document image. Extensive experiments on the DocEdit dataset show that DocEdit-v2 significantly outperforms strong baselines on edit command generation (2-33%), RoI bounding box detection (12-31%), and overall document editing (1-12\%) tasks.
How Much User Context Do We Need? Privacy by Design in Mental Health NLP Application
Sep 05, 2022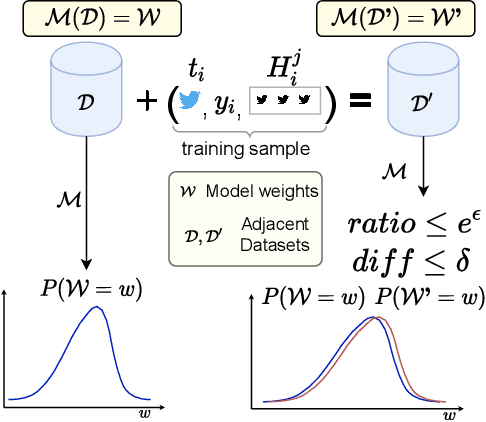
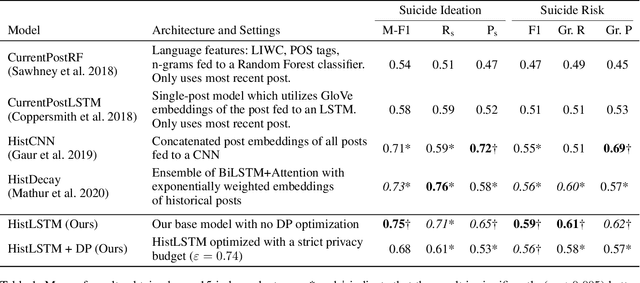
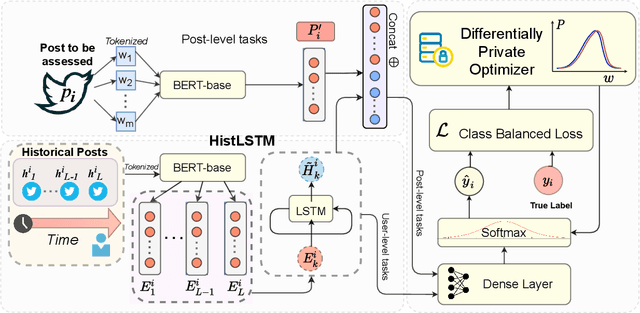
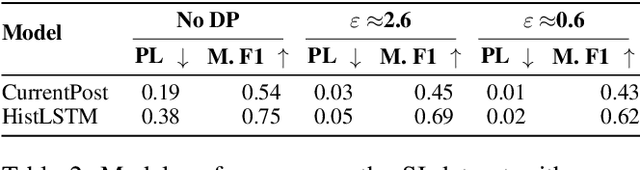
Clinical NLP tasks such as mental health assessment from text, must take social constraints into account - the performance maximization must be constrained by the utmost importance of guaranteeing privacy of user data. Consumer protection regulations, such as GDPR, generally handle privacy by restricting data availability, such as requiring to limit user data to 'what is necessary' for a given purpose. In this work, we reason that providing stricter formal privacy guarantees, while increasing the volume of user data in the model, in most cases increases benefit for all parties involved, especially for the user. We demonstrate our arguments on two existing suicide risk assessment datasets of Twitter and Reddit posts. We present the first analysis juxtaposing user history length and differential privacy budgets and elaborate how modeling additional user context enables utility preservation while maintaining acceptable user privacy guarantees.
The Impact of Differential Privacy on Group Disparity Mitigation
Mar 05, 2022
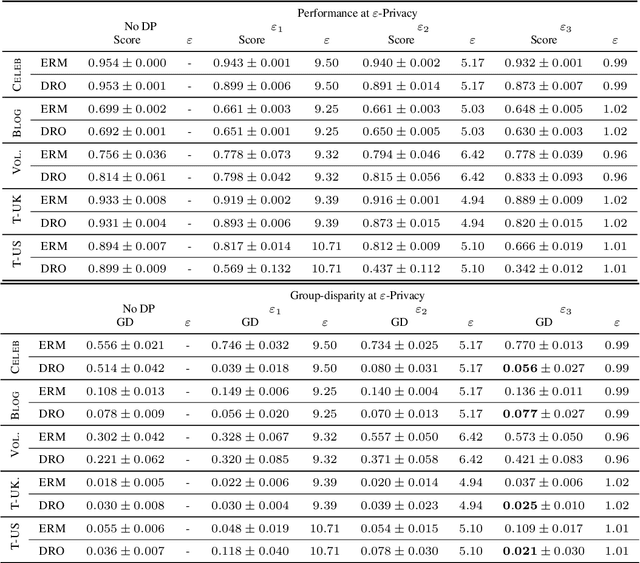
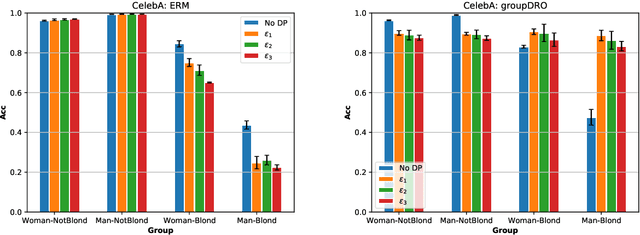
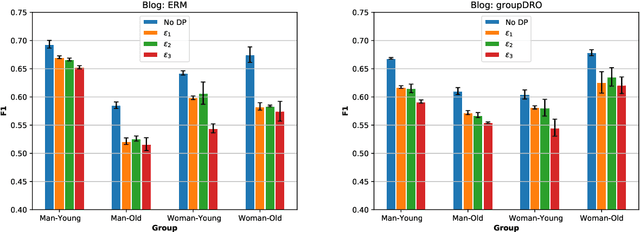
The performance cost of differential privacy has, for some applications, been shown to be higher for minority groups; fairness, conversely, has been shown to disproportionally compromise the privacy of members of such groups. Most work in this area has been restricted to computer vision and risk assessment. In this paper, we evaluate the impact of differential privacy on fairness across four tasks, focusing on how attempts to mitigate privacy violations and between-group performance differences interact: Does privacy inhibit attempts to ensure fairness? To this end, we train $(\varepsilon,\delta)$-differentially private models with empirical risk minimization and group distributionally robust training objectives. Consistent with previous findings, we find that differential privacy increases between-group performance differences in the baseline setting; but more interestingly, differential privacy reduces between-group performance differences in the robust setting. We explain this by reinterpreting differential privacy as regularization.
ADIMA: Abuse Detection In Multilingual Audio
Feb 16, 2022
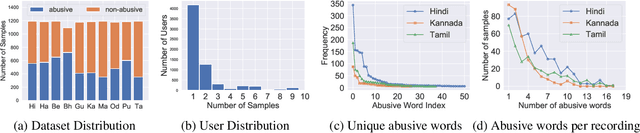
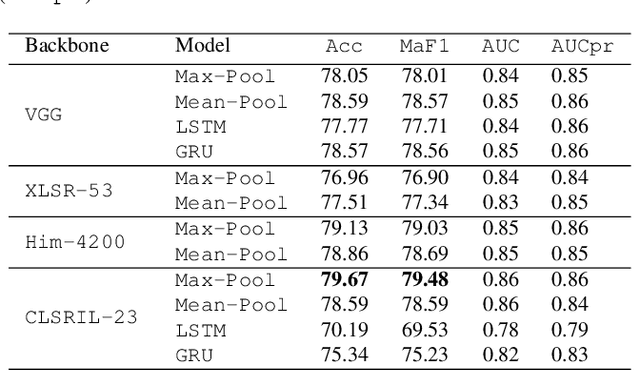
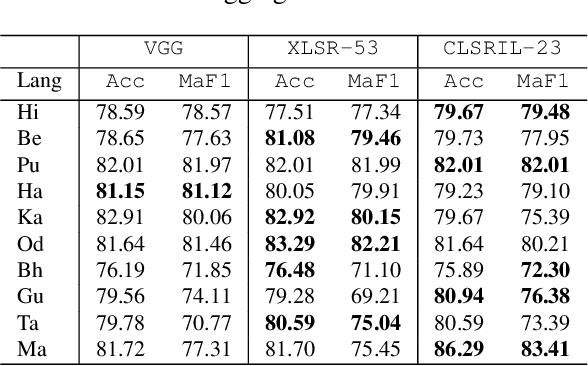
Abusive content detection in spoken text can be addressed by performing Automatic Speech Recognition (ASR) and leveraging advancements in natural language processing. However, ASR models introduce latency and often perform sub-optimally for profane words as they are underrepresented in training corpora and not spoken clearly or completely. Exploration of this problem entirely in the audio domain has largely been limited by the lack of audio datasets. Building on these challenges, we propose ADIMA, a novel, linguistically diverse, ethically sourced, expert annotated and well-balanced multilingual profanity detection audio dataset comprising of 11,775 audio samples in 10 Indic languages spanning 65 hours and spoken by 6,446 unique users. Through quantitative experiments across monolingual and cross-lingual zero-shot settings, we take the first step in democratizing audio based content moderation in Indic languages and set forth our dataset to pave future work.
An Iterative Approach for Identifying Complaint Based Tweets in Social Media Platforms
Jan 24, 2020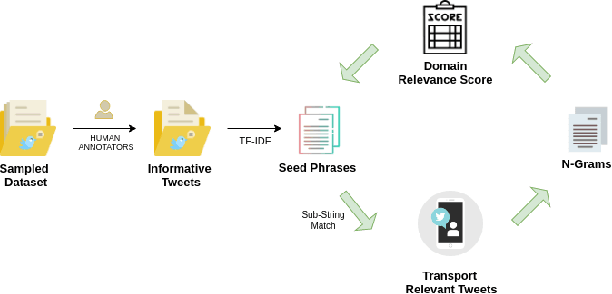

Twitter is a social media platform where users express opinions over a variety of issues. Posts offering grievances or complaints can be utilized by private/ public organizations to improve their service and promptly gauge a low-cost assessment. In this paper, we propose an iterative methodology which aims to identify complaint based posts pertaining to the transport domain. We perform comprehensive evaluations along with releasing a novel dataset for the research purposes.
#MeTooMA: Multi-Aspect Annotations of Tweets Related to the MeToo Movement
Dec 14, 2019
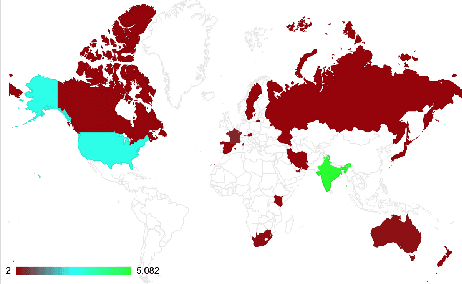

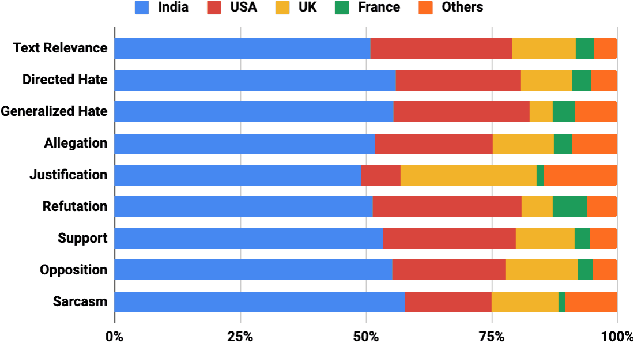
In this paper, we present a dataset containing 9,973 tweets related to the MeToo movement that were manually annotated for five different linguistic aspects: relevance, stance, hate speech, sarcasm, and dialogue acts. We present a detailed account of the data collection and annotation processes. The annotations have a very high inter-annotator agreement (0.79 to 0.93 k-alpha) due to the domain expertise of the annotators and clear annotation instructions. We analyze the data in terms of geographical distribution, label correlations, and keywords. Lastly, we present some potential use cases of this dataset. We expect this dataset would be of great interest to psycholinguists, socio-linguists, and computational linguists to study the discursive space of digitally mobilized social movements on sensitive issues like sexual harassment.