 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Uncertainty guided Clarification for LLM Agents
Nov 11, 2025LLM agents extend large language models with tool-calling capabilities, but ambiguous user instructions often lead to incorrect invocations and task failures. We introduce a principled formulation of structured uncertainty over tool-call parameters, modeling joint tool-argument clarification as a POMDP with Expected Value of Perfect Information (EVPI) objective for optimal question selection and aspect-based cost modeling to prevent redundancy. Our SAGE-Agent leverages this structured uncertainty to achieve superior efficiency: increasing coverage on ambiguous tasks by 7-39\% while reducing clarification questions by 1.5-2.7$\times$ compared to strong prompting and uncertainty-based baselines. We present ClarifyBench, the first multi-turn tool-augmented disambiguation benchmark with realistic LLM-based user simulation across diverse domains including document editing, vehicle control, and travel booking. Additionally, we demonstrate that structured uncertainty provides effective training signals for reinforcement learning, boosting When2Call accuracy from 36.5\% to 65.2\% (3B model) and 36.7\% to 62.9\% (7B model) through uncertainty-weighted GRPO training. These results establish structured uncertainty as a principled, efficient approach for tool-augmented agents, improving both task success and interaction efficiency in real-world scenarios.
ChartLens: Fine-grained Visual Attribution in Charts
May 25, 2025



The growing capabilities of multimodal large language models (MLLMs) have advanced tasks like chart understanding. However, these models often suffer from hallucinations, where generated text sequences conflict with the provided visual data. To address this, we introduce Post-Hoc Visual Attribution for Charts, which identifies fine-grained chart elements that validate a given chart-associated response. We propose ChartLens, a novel chart attribution algorithm that uses segmentation-based techniques to identify chart objects and employs set-of-marks prompting with MLLMs for fine-grained visual attribution. Additionally, we present ChartVA-Eval, a benchmark with synthetic and real-world charts from diverse domains like finance, policy, and economics, featuring fine-grained attribution annotations. Our evaluations show that ChartLens improves fine-grained attributions by 26-66%.
Mitigating Memorization in LLMs using Activation Steering
Mar 08, 2025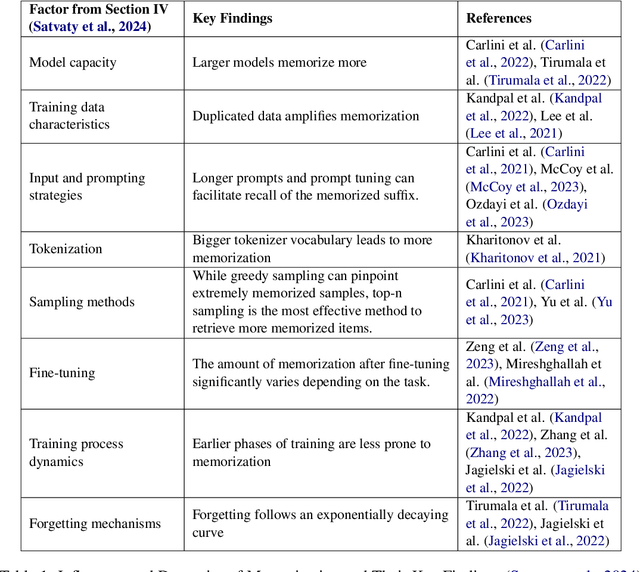
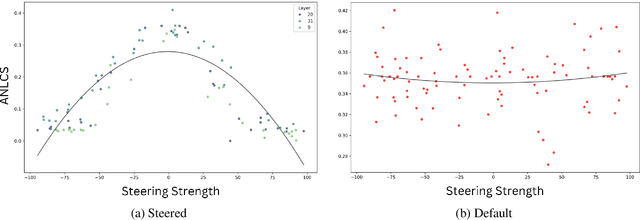
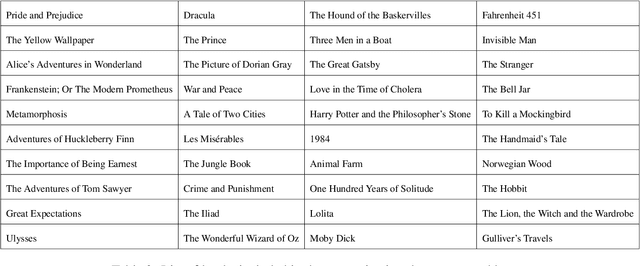
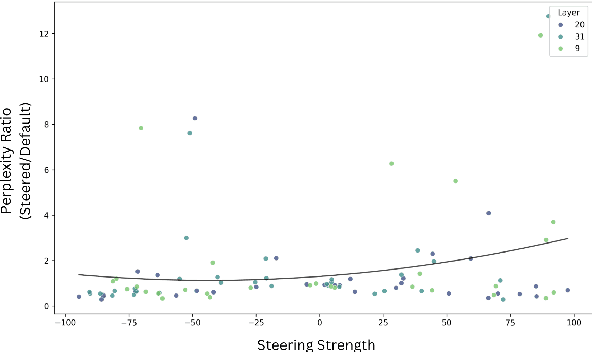
The memorization of training data by Large Language Models (LLMs) poses significant risks, including privacy leaks and the regurgitation of copyrighted content. Activation steering, a technique that directly intervenes in model activations, has emerged as a promising approach for manipulating LLMs. In this work, we explore the effectiveness of activation steering in reducing memorization while preserving generalization capabilities. We conduct empirical evaluations using a controlled memorization benchmark of literary material and demonstrate that our method successfully suppresses memorized content with minimal degradation in model performance in Gemma. Additionally, we analyze the trade-offs between suppression effectiveness and linguistic fluency, highlighting the advantages and limitations of activation-based interventions. Our findings contribute to ongoing efforts in developing safer and more privacy-preserving LLMs by providing a practical and efficient mechanism to mitigate unintended memorization.
VisDoM: Multi-Document QA with Visually Rich Elements Using Multimodal Retrieval-Augmented Generation
Dec 14, 2024



Understanding information from a collection of multiple documents, particularly those with visually rich elements, is important for document-grounded question answering. This paper introduces VisDoMBench, the first comprehensive benchmark designed to evaluate QA systems in multi-document settings with rich multimodal content, including tables, charts, and presentation slides. We propose VisDoMRAG, a novel multimodal Retrieval Augmented Generation (RAG) approach that simultaneously utilizes visual and textual RAG, combining robust visual retrieval capabilities with sophisticated linguistic reasoning. VisDoMRAG employs a multi-step reasoning process encompassing evidence curation and chain-of-thought reasoning for concurrent textual and visual RAG pipelines. A key novelty of VisDoMRAG is its consistency-constrained modality fusion mechanism, which aligns the reasoning processes across modalities at inference time to produce a coherent final answer. This leads to enhanced accuracy in scenarios where critical information is distributed across modalities and improved answer verifiability through implicit context attribution. Through extensive experiments involving open-source and proprietary large language models, we benchmark state-of-the-art document QA methods on VisDoMBench. Extensive results show that VisDoMRAG outperforms unimodal and long-context LLM baselines for end-to-end multimodal document QA by 12-20%.
x-RAGE: eXtended Reality -- Action & Gesture Events Dataset
Oct 25, 2024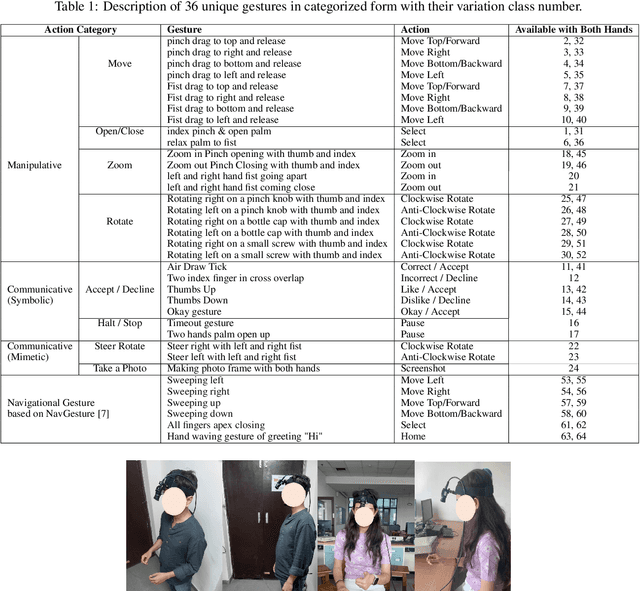


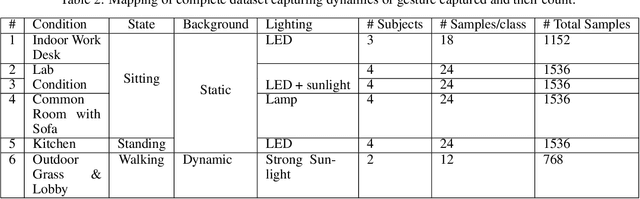
With the emergence of the Metaverse and focus on wearable devices in the recent years gesture based human-computer interaction has gained significance. To enable gesture recognition for VR/AR headsets and glasses several datasets focusing on egocentric i.e. first-person view have emerged in recent years. However, standard frame-based vision suffers from limitations in data bandwidth requirements as well as ability to capture fast motions. To overcome these limitation bio-inspired approaches such as event-based cameras present an attractive alternative. In this work, we present the first event-camera based egocentric gesture dataset for enabling neuromorphic, low-power solutions for XR-centric gesture recognition. The dataset has been made available publicly at the following URL: https://gitlab.com/NVM_IITD_Research/xrage.
DocEdit-v2: Document Structure Editing Via Multimodal LLM Grounding
Oct 21, 2024



Document structure editing involves manipulating localized textual, visual, and layout components in document images based on the user's requests. Past works have shown that multimodal grounding of user requests in the document image and identifying the accurate structural components and their associated attributes remain key challenges for this task. To address these, we introduce the DocEdit-v2, a novel framework that performs end-to-end document editing by leveraging Large Multimodal Models (LMMs). It consists of three novel components: (1) Doc2Command, which simultaneously localizes edit regions of interest (RoI) and disambiguates user edit requests into edit commands; (2) LLM-based Command Reformulation prompting to tailor edit commands originally intended for specialized software into edit instructions suitable for generalist LMMs. (3) Moreover, DocEdit-v2 processes these outputs via Large Multimodal Models like GPT-4V and Gemini, to parse the document layout, execute edits on grounded Region of Interest (RoI), and generate the edited document image. Extensive experiments on the DocEdit dataset show that DocEdit-v2 significantly outperforms strong baselines on edit command generation (2-33%), RoI bounding box detection (12-31%), and overall document editing (1-12\%) tasks.
Non-Invasive Qualitative Vibration Analysis using Event Camera
Oct 18, 2024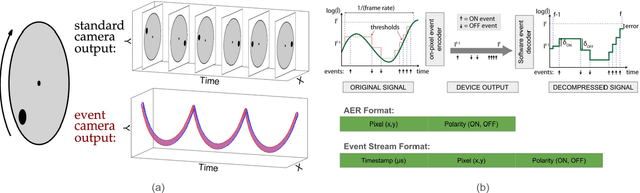
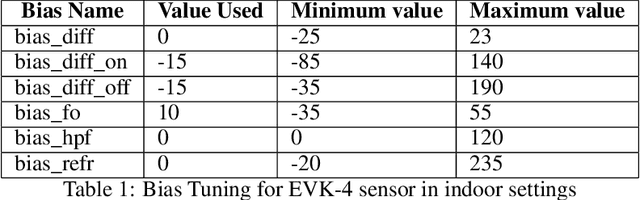
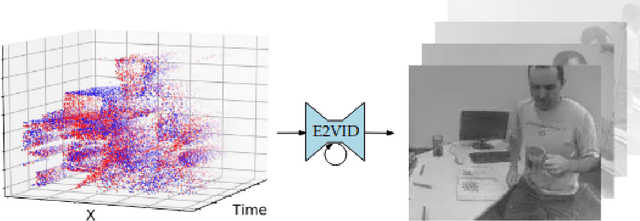
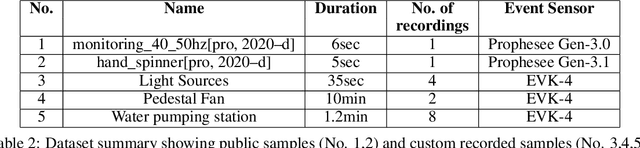
This technical report investigates the application of event-based vision sensors in non-invasive qualitative vibration analysis, with a particular focus on frequency measurement and motion magnification. Event cameras, with their high temporal resolution and dynamic range, offer promising capabilities for real-time structural assessment and subtle motion analysis. Our study employs cutting-edge event-based vision techniques to explore real-world scenarios in frequency measurement in vibrational analysis and intensity reconstruction for motion magnification. In the former, event-based sensors demonstrated significant potential for real-time structural assessment. However, our work in motion magnification revealed considerable challenges, particularly in scenarios involving stationary cameras and isolated motion.
A Survey of Graph and Attention Based Hyperspectral Image Classification Methods for Remote Sensing Data
Oct 16, 2023



The use of Deep Learning techniques for classification in Hyperspectral Imaging (HSI) is rapidly growing and achieving improved performances. Due to the nature of the data captured by sensors that produce HSI images, a common issue is the dimensionality of the bands that may or may not contribute to the label class distinction. Due to the widespread nature of class labels, Principal Component Analysis is a common method used for reducing the dimensionality. However,there may exist methods that incorporate all bands of the Hyperspectral image with the help of the Attention mechanism. Furthermore, to yield better spectral spatial feature extraction, recent methods have also explored the usage of Graph Convolution Networks and their unique ability to use node features in prediction, which is akin to the pixel spectral makeup. In this survey we present a comprehensive summary of Graph based and Attention based methods to perform Hyperspectral Image Classification for remote sensing and aerial HSI images. We also summarize relevant datasets on which these techniques have been evaluated and benchmark the processing techniques.
ACLM: A Selective-Denoising based Generative Data Augmentation Approach for Low-Resource Complex NER
Jun 01, 2023



Complex Named Entity Recognition (NER) is the task of detecting linguistically complex named entities in low-context text. In this paper, we present ACLM Attention-map aware keyword selection for Conditional Language Model fine-tuning), a novel data augmentation approach based on conditional generation to address the data scarcity problem in low-resource complex NER. ACLM alleviates the context-entity mismatch issue, a problem existing NER data augmentation techniques suffer from and often generates incoherent augmentations by placing complex named entities in the wrong context. ACLM builds on BART and is optimized on a novel text reconstruction or denoising task - we use selective masking (aided by attention maps) to retain the named entities and certain keywords in the input sentence that provide contextually relevant additional knowledge or hints about the named entities. Compared with other data augmentation strategies, ACLM can generate more diverse and coherent augmentations preserving the true word sense of complex entities in the sentence. We demonstrate the effectiveness of ACLM both qualitatively and quantitatively on monolingual, cross-lingual, and multilingual complex NER across various low-resource settings. ACLM outperforms all our neural baselines by a significant margin (1%-36%). In addition, we demonstrate the application of ACLM to other domains that suffer from data scarcity (e.g., biomedical). In practice, ACLM generates more effective and factual augmentations for these domains than prior methods. Code: https://github.com/Sreyan88/ACLM
The Geometry of Multilingual Language Models: An Equality Lens
May 13, 2023



Understanding the representations of different languages in multilingual language models is essential for comprehending their cross-lingual properties, predicting their performance on downstream tasks, and identifying any biases across languages. In our study, we analyze the geometry of three multilingual language models in Euclidean space and find that all languages are represented by unique geometries. Using a geometric separability index we find that although languages tend to be closer according to their linguistic family, they are almost separable with languages from other families. We also introduce a Cross-Lingual Similarity Index to measure the distance of languages with each other in the semantic space. Our findings indicate that the low-resource languages are not represented as good as high resource languages in any of the models