 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgex-RAGE: eXtended Reality -- Action & Gesture Events Dataset
Oct 25, 2024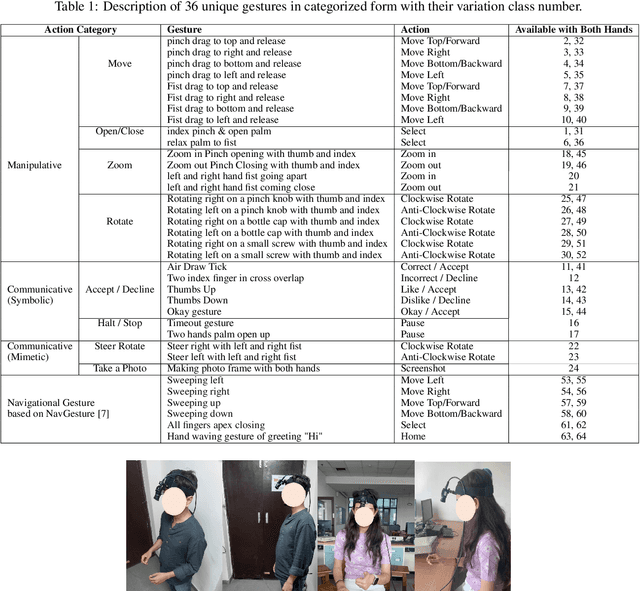


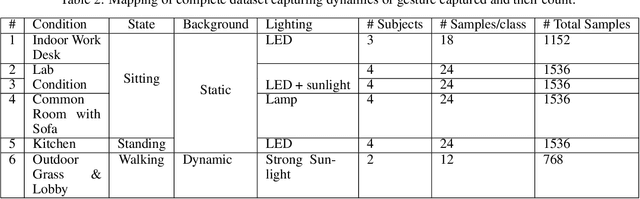
With the emergence of the Metaverse and focus on wearable devices in the recent years gesture based human-computer interaction has gained significance. To enable gesture recognition for VR/AR headsets and glasses several datasets focusing on egocentric i.e. first-person view have emerged in recent years. However, standard frame-based vision suffers from limitations in data bandwidth requirements as well as ability to capture fast motions. To overcome these limitation bio-inspired approaches such as event-based cameras present an attractive alternative. In this work, we present the first event-camera based egocentric gesture dataset for enabling neuromorphic, low-power solutions for XR-centric gesture recognition. The dataset has been made available publicly at the following URL: https://gitlab.com/NVM_IITD_Research/xrage.
Low-Power Hardware-Based Deep-Learning Diagnostics Support Case Study
Sep 03, 2022
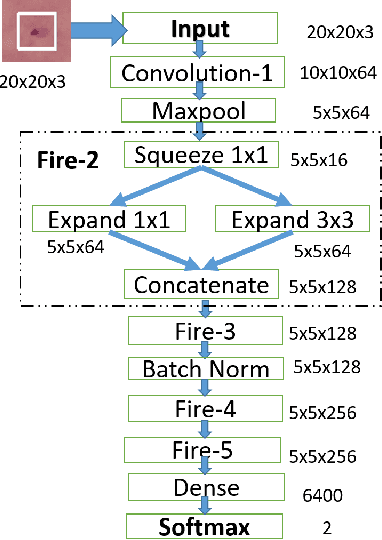
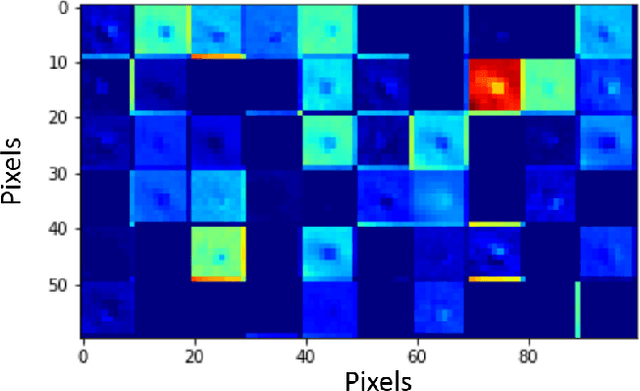

Deep learning research has generated widespread interest leading to emergence of a large variety of technological innovations and applications. As significant proportion of deep learning research focuses on vision based applications, there exists a potential for using some of these techniques to enable low-power portable health-care diagnostic support solutions. In this paper, we propose an embedded-hardware-based implementation of microscopy diagnostic support system for PoC case study on: (a) Malaria in thick blood smears, (b) Tuberculosis in sputum samples, and (c) Intestinal parasite infection in stool samples. We use a Squeeze-Net based model to reduce the network size and computation time. We also utilize the Trained Quantization technique to further reduce memory footprint of the learned models. This enables microscopy-based detection of pathogens that classifies with laboratory expert level accuracy as a standalone embedded hardware platform. The proposed implementation is 6x more power-efficient compared to conventional CPU-based implementation and has an inference time of $\sim$ 3 ms/sample.
Memory-Oriented Design-Space Exploration of Edge-AI Hardware for XR Applications
Jun 08, 2022
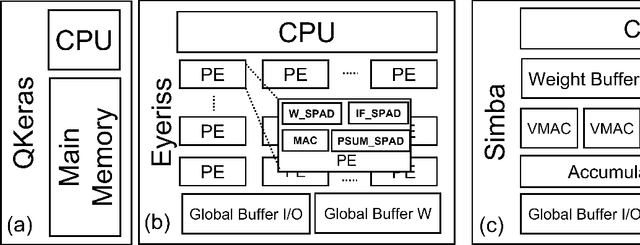
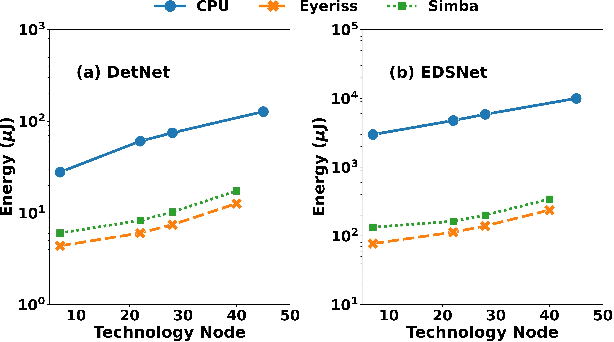
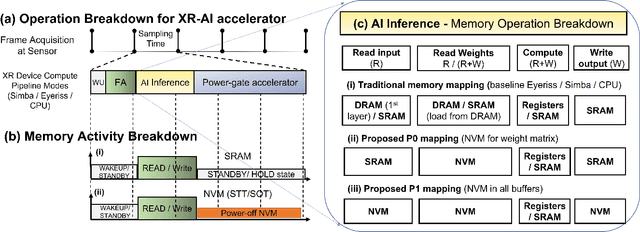
Low-Power Edge-AI capabilities are essential for on-device extended reality (XR) applications to support the vision of Metaverse. In this work, we investigate two representative XR workloads: (i) Hand detection and (ii) Eye segmentation, for hardware design space exploration. For both applications, we train deep neural networks and analyze the impact of quantization and hardware specific bottlenecks. Through simulations, we evaluate a CPU and two systolic inference accelerator implementations. Next, we compare these hardware solutions with advanced technology nodes. The impact of integrating state-of-the-art emerging non-volatile memory technology (STT/SOT/VGSOT MRAM) into the XR-AI inference pipeline is evaluated. We found that significant energy benefits (>=80%) can be achieved for hand detection (IPS=40) and eye segmentation (IPS=6) by introducing non-volatile memory in the memory hierarchy for designs at 7nm node while meeting minimum IPS (inference per second). Moreover, we can realize substantial reduction in area (>=30%) owing to the small form factor of MRAM compared to traditional SRAM.
Exploration of Optimized Semantic Segmentation Architectures for edge-Deployment on Drones
Jul 06, 2020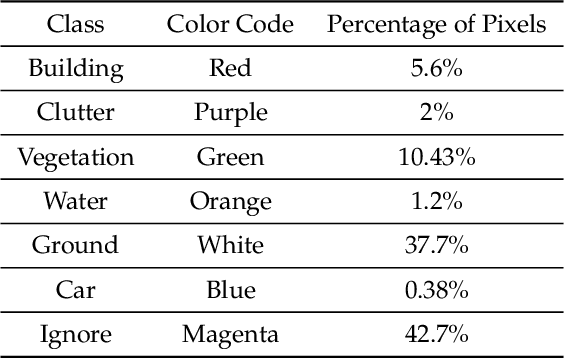
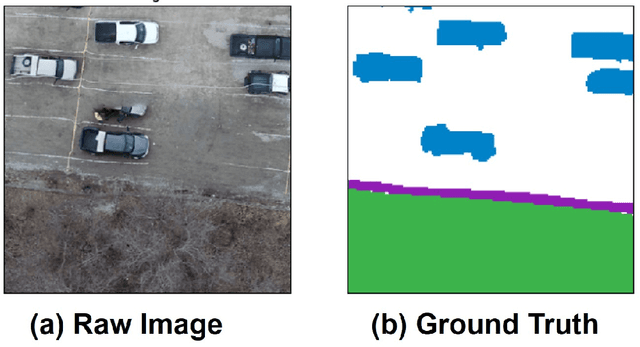
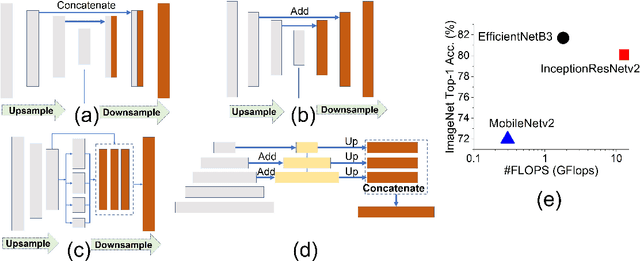

In this paper, we present an analysis on the impact of network parameters for semantic segmentation architectures in context of UAV data processing. We present the analysis on the DroneDeploy Segmentation benchmark. Based on the comparative analysis we identify the optimal network architecture to be FPN-EfficientNetB3 with pretrained encoder backbones based on Imagenet Dataset. The network achieves IoU score of 0.65 and F1-score of 0.71 over the validation dataset. We also compare the various architectures in terms of their memory footprint and inference latency with further exploration of the impact of TensorRT based optimizations. We achieve memory savings of ~4.1x and latency improvement of 10% compared to Model: FPN and Backbone: InceptionResnetV2.
Methodology for Realizing VMM with Binary RRAM Arrays: Experimental Demonstration of Binarized-ADALINE Using OxRAM Crossbar
Jun 10, 2020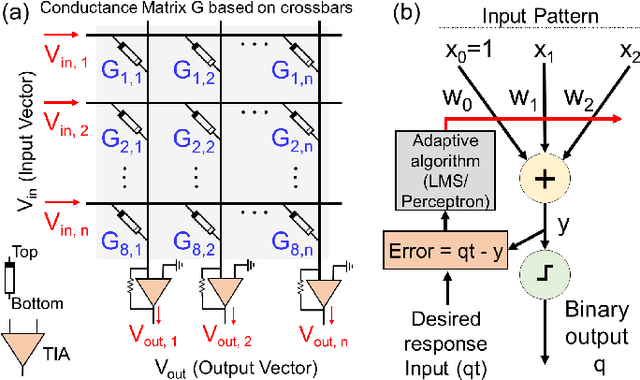
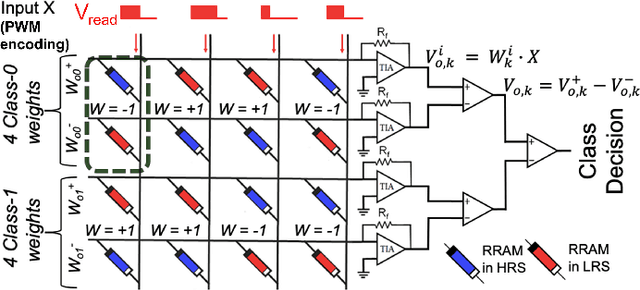


In this paper, we present an efficient hardware mapping methodology for realizing vector matrix multiplication (VMM) on resistive memory (RRAM) arrays. Using the proposed VMM computation technique, we experimentally demonstrate a binarized-ADALINE (Adaptive Linear) classifier on an OxRAM crossbar. An 8x8 OxRAM crossbar with Ni/3-nm HfO2/7 nm Al-doped-TiO2/TiN device stack is used. Weight training for the binarized-ADALINE classifier is performed ex-situ on UCI cancer dataset. Post weight generation the OxRAM array is carefully programmed to binary weight-states using the proposed weight mapping technique on a custom-built testbench. Our VMM powered binarized-ADALINE network achieves a classification accuracy of 78% in simulation and 67% in experiments. Experimental accuracy was found to drop mainly due to crossbar inherent sneak-path issues and RRAM device programming variability.
Design Exploration of Hybrid CMOS-OxRAM Deep Generative Architectures
Jan 06, 2018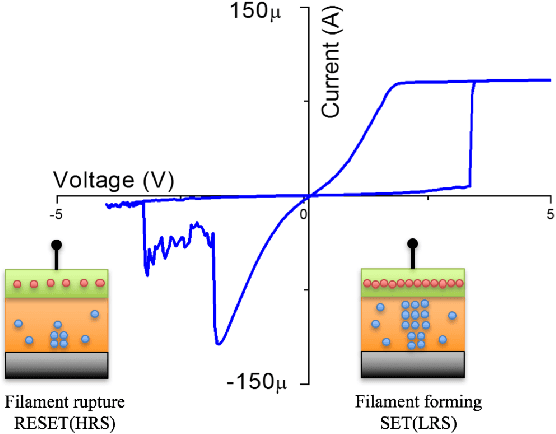
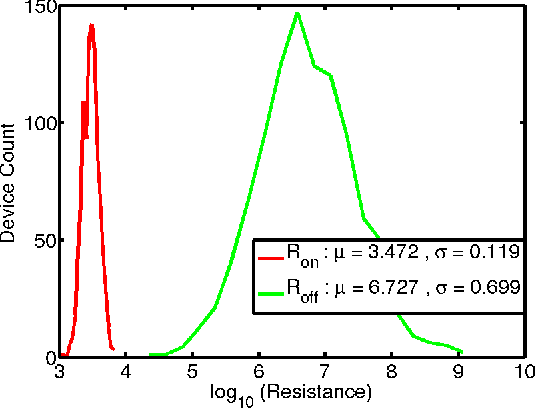
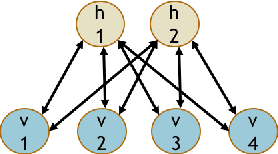
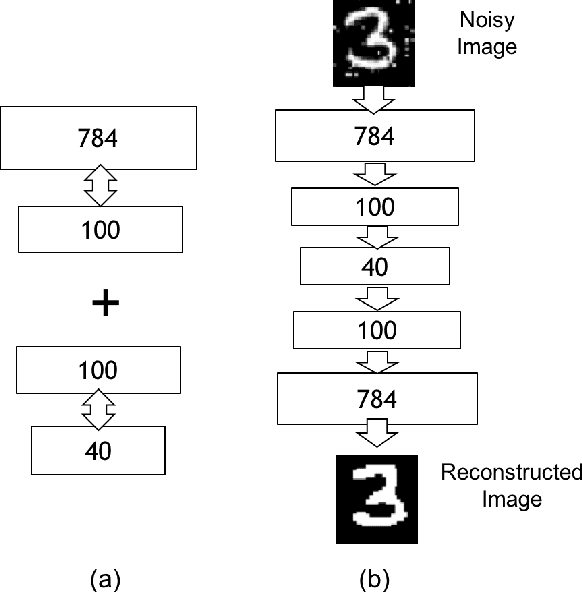
Deep Learning and its applications have gained tremendous interest recently in both academia and industry. Restricted Boltzmann Machines (RBMs) offer a key methodology to implement deep learning paradigms. This paper presents a novel approach for realizing hybrid CMOS-OxRAM based deep generative models (DGM). In our proposed hybrid DGM architectures, HfOx based (filamentary-type switching) OxRAM devices are extensively used for realizing multiple computational and non-computational functions such as: (i) Synapses (weights), (ii) internal neuron-state storage, (iii) stochastic neuron activation and (iv) programmable signal normalization. To validate the proposed scheme we have simulated two different architectures: (i) Deep Belief Network (DBN) and (ii) Stacked Denoising Autoencoder for classification and reconstruction of hand-written digits from a reduced MNIST dataset of 6000 images. Contrastive-divergence (CD) specially optimized for OxRAM devices was used to drive the synaptic weight update mechanism of each layer in the network. Overall learning rule was based on greedy-layer wise learning with no back propagation which allows the network to be trained to a good pre-training stage. Performance of the simulated hybrid CMOS-RRAM DGM model matches closely with software based model for a 2-layers deep network. Top-3 test accuracy achieved by the DBN was 95.5%. MSE of the SDA network was 0.003, lower than software based approach. Endurance analysis of the simulated architectures show that for 200 epochs of training (single RBM layer), maximum switching events/per OxRAM device was ~ 7000 cycles.