 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceNAS: Zero-shot LLM Pruning via Gradient Trace Correlation
Feb 02, 2026Structured pruning is essential for efficient deployment of Large Language Models (LLMs). The varying sensitivity of LLM sub-blocks to pruning necessitates the identification of optimal non-uniformly pruned models. Existing methods evaluate the importance of layers, attention heads, or weight channels in isolation. Such localized focus ignores the complex global structural dependencies that exist across the model. Training-aware structured pruning addresses global dependencies, but its computational cost can be just as expensive as post-pruning training. To alleviate the computational burden of training-aware pruning and capture global structural dependencies, we propose TraceNAS, a training-free Neural Architecture Search (NAS) framework that jointly explores structured pruning of LLM depth and width. TraceNAS identifies pruned models that maintain a high degree of loss landscape alignment with the pretrained model using a scale-invariant zero-shot proxy, effectively selecting models that exhibit maximal performance potential during post-pruning training. TraceNAS is highly efficient, enabling high-fidelity discovery of pruned models on a single GPU in 8.5 hours, yielding a 10$\times$ reduction in GPU-hours compared to training-aware methods. Evaluations on the Llama and Qwen families demonstrate that TraceNAS is competitive with training-aware baselines across commonsense and reasoning benchmarks.
TSkips: Efficiency Through Explicit Temporal Delay Connections in Spiking Neural Networks
Nov 22, 2024



Spiking Neural Networks (SNNs) with their bio-inspired Leaky Integrate-and-Fire (LIF) neurons inherently capture temporal information. This makes them well-suited for sequential tasks like processing event-based data from Dynamic Vision Sensors (DVS) and event-based speech tasks. Harnessing the temporal capabilities of SNNs requires mitigating vanishing spikes during training, capturing spatio-temporal patterns and enhancing precise spike timing. To address these challenges, we propose TSkips, augmenting SNN architectures with forward and backward skip connections that incorporate explicit temporal delays. These connections capture long-term spatio-temporal dependencies and facilitate better spike flow over long sequences. The introduction of TSkips creates a vast search space of possible configurations, encompassing skip positions and time delay values. To efficiently navigate this search space, this work leverages training-free Neural Architecture Search (NAS) to identify optimal network structures and corresponding delays. We demonstrate the effectiveness of our approach on four event-based datasets: DSEC-flow for optical flow estimation, DVS128 Gesture for hand gesture recognition and Spiking Heidelberg Digits (SHD) and Spiking Speech Commands (SSC) for speech recognition. Our method achieves significant improvements across these datasets: up to 18% reduction in Average Endpoint Error (AEE) on DSEC-flow, 8% increase in classification accuracy on DVS128 Gesture, and up to 8% and 16% higher classification accuracy on SHD and SSC, respectively.
SpiDR: A Reconfigurable Digital Compute-in-Memory Spiking Neural Network Accelerator for Event-based Perception
Nov 05, 2024



Spiking Neural Networks (SNNs), with their inherent recurrence, offer an efficient method for processing the asynchronous temporal data generated by Dynamic Vision Sensors (DVS), making them well-suited for event-based vision applications. However, existing SNN accelerators suffer from limitations in adaptability to diverse neuron models, bit precisions and network sizes, inefficient membrane potential (Vmem) handling, and limited sparse optimizations. In response to these challenges, we propose a scalable and reconfigurable digital compute-in-memory (CIM) SNN accelerator \chipname with a set of key features: 1) It uses in-memory computations and reconfigurable operating modes to minimize data movement associated with weight and Vmem data structures while efficiently adapting to different workloads. 2) It supports multiple weight/Vmem bit precision values, enabling a trade-off between accuracy and energy efficiency and enhancing adaptability to diverse application demands. 3) A zero-skipping mechanism for sparse inputs significantly reduces energy usage by leveraging the inherent sparsity of spikes without introducing high overheads for low sparsity. 4) Finally, the asynchronous handshaking mechanism maintains the computational efficiency of the pipeline for variable execution times of different computation units. We fabricated \chipname in 65 nm Taiwan Semiconductor Manufacturing Company (TSMC) low-power (LP) technology. It demonstrates competitive performance (scaled to the same technology node) to other digital SNN accelerators proposed in the recent literature and supports advanced reconfigurability. It achieves up to 5 TOPS/W energy efficiency at 95% input sparsity with 4-bit weights and 7-bit Vmem precision.
Approximate ADCs for In-Memory Computing
Aug 11, 2024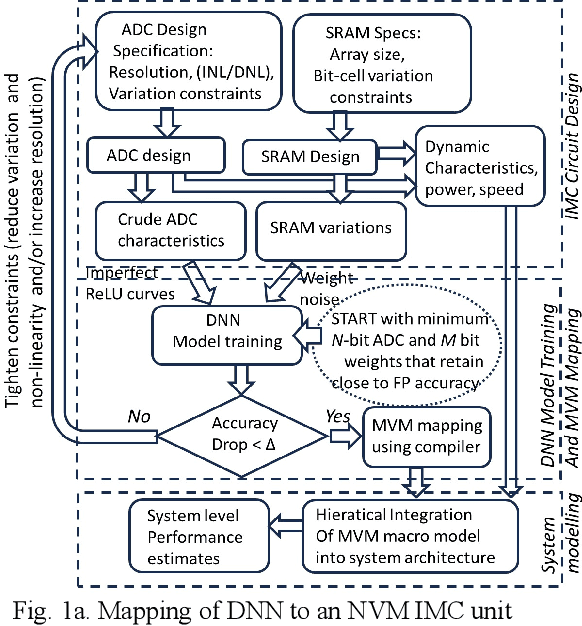
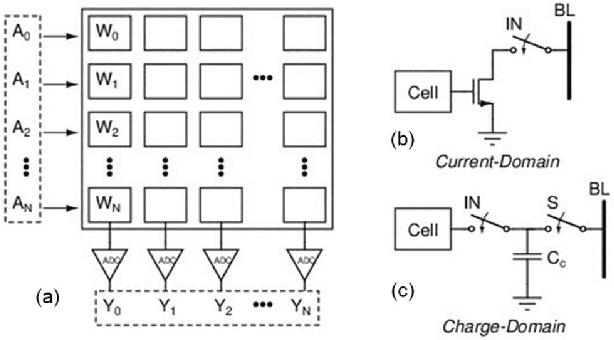
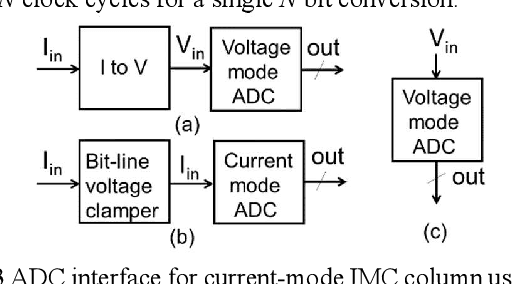
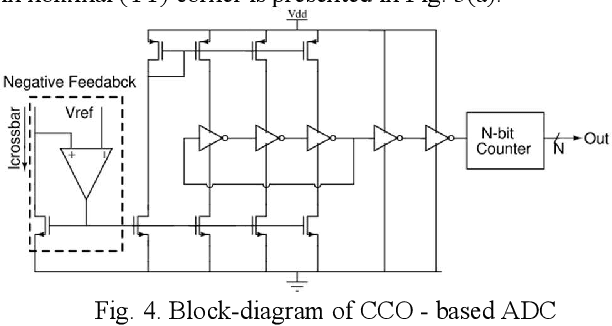
In memory computing (IMC) architectures for deep learning (DL) accelerators leverage energy-efficient and highly parallel matrix vector multiplication (MVM) operations, implemented directly in memory arrays. Such IMC designs have been explored based on CMOS as well as emerging non-volatile memory (NVM) technologies like RRAM. IMC architectures generally involve a large number of cores consisting of memory arrays, storing the trained weights of the DL model. Peripheral units like DACs and ADCs are also used for applying inputs and reading out the output values. Recently reported designs reveal that the ADCs required for reading out the MVM results, consume more than 85% of the total compute power and also dominate the area, thereby eschewing the benefits of the IMC scheme. Mitigation of imperfections in the ADCs, namely, non-linearity and variations, incur significant design overheads, due to dedicated calibration units. In this work we present peripheral aware design of IMC cores, to mitigate such overheads. It involves incorporating the non-idealities of ADCs in the training of the DL models, along with that of the memory units. The proposed approach applies equally well to both current mode as well as charge mode MVM operations demonstrated in recent years., and can significantly simplify the design of mixed-signal IMC units.
Best of Both Worlds: Hybrid SNN-ANN Architecture for Event-based Optical Flow Estimation
Jun 05, 2023



Event-based cameras offer a low-power alternative to frame-based cameras for capturing high-speed motion and high dynamic range scenes. They provide asynchronous streams of sparse events. Spiking Neural Networks (SNNs) with their asynchronous event-driven compute, show great potential for extracting the spatio-temporal features from these event streams. In contrast, the standard Analog Neural Networks (ANNs1) fail to process event data effectively. However, training SNNs is difficult due to additional trainable parameters (thresholds and leaks), vanishing spikes at deeper layers, non-differentiable binary activation function etc. Moreover, an additional data structure "membrane potential" responsible for keeping track of temporal information, must be fetched and updated at every timestep in SNNs. To overcome these, we propose a novel SNN-ANN hybrid architecture that combines the strengths of both. Specifically, we leverage the asynchronous compute capabilities of SNN layers to effectively extract the input temporal information. While the ANN layers offer trouble-free training and implementation on standard machine learning hardware such as GPUs. We provide extensive experimental analysis for assigning each layer to be spiking or analog in nature, leading to a network configuration optimized for performance and ease of training. We evaluate our hybrid architectures for optical flow estimation using event-data on DSEC-flow and Mutli-Vehicle Stereo Event-Camera (MVSEC) datasets. The results indicate that our configured hybrid architectures outperform the state-of-the-art ANN-only, SNN-only and past hybrid architectures both in terms of accuracy and efficiency. Specifically, our hybrid architecture exhibit a 31% and 24.8% lower average endpoint error (AEE) at 2.1x and 3.1x lower energy, compared to an SNN-only architecture on DSEC and MVSEC datasets, respectively.
NAX: Co-Designing Neural Network and Hardware Architecture for Memristive Xbar based Computing Systems
Jun 23, 2021
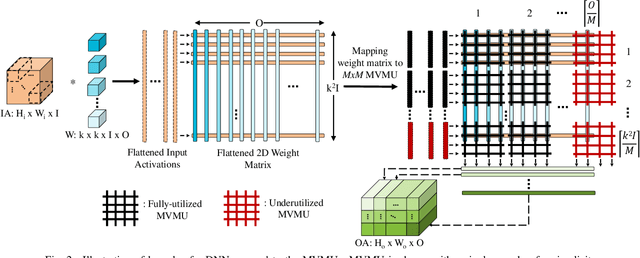
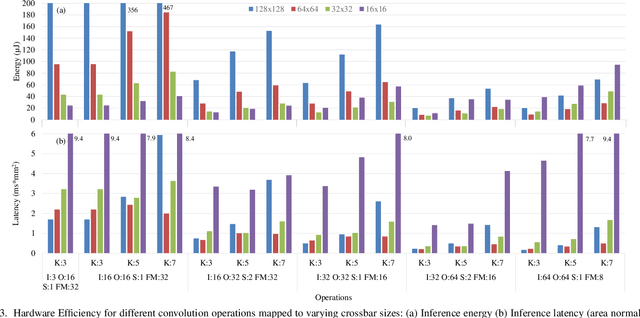

In-Memory Computing (IMC) hardware using Memristive Crossbar Arrays (MCAs) are gaining popularity to accelerate Deep Neural Networks (DNNs) since it alleviates the "memory wall" problem associated with von-Neumann architecture. The hardware efficiency (energy, latency and area) as well as application accuracy (considering device and circuit non-idealities) of DNNs mapped to such hardware are co-dependent on network parameters, such as kernel size, depth etc. and hardware architecture parameters such as crossbar size. However, co-optimization of both network and hardware parameters presents a challenging search space comprising of different kernel sizes mapped to varying crossbar sizes. To that effect, we propose NAX -- an efficient neural architecture search engine that co-designs neural network and IMC based hardware architecture. NAX explores the aforementioned search space to determine kernel and corresponding crossbar sizes for each DNN layer to achieve optimal tradeoffs between hardware efficiency and application accuracy. Our results from NAX show that the networks have heterogeneous crossbar sizes across different network layers, and achieves optimal hardware efficiency and accuracy considering the non-idealities in crossbars. On CIFAR-10 and Tiny ImageNet, our models achieve 0.8%, 0.2% higher accuracy, and 17%, 4% lower EDAP (energy-delay-area product) compared to a baseline ResNet-20 and ResNet-18 models, respectively.
Exploration of Optimized Semantic Segmentation Architectures for edge-Deployment on Drones
Jul 06, 2020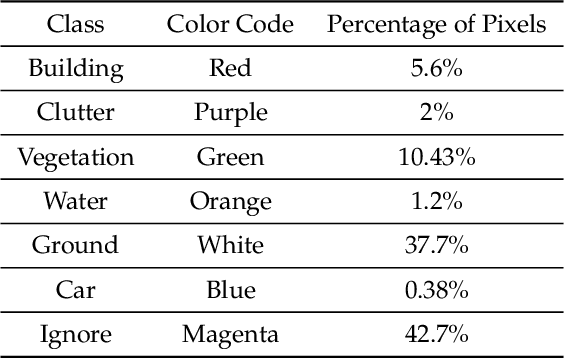
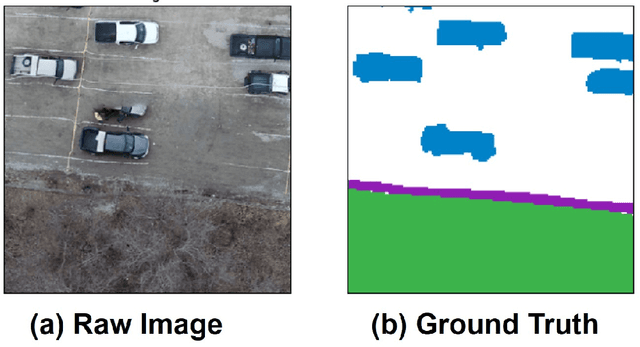
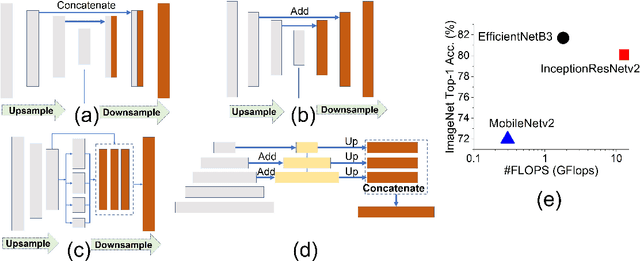

In this paper, we present an analysis on the impact of network parameters for semantic segmentation architectures in context of UAV data processing. We present the analysis on the DroneDeploy Segmentation benchmark. Based on the comparative analysis we identify the optimal network architecture to be FPN-EfficientNetB3 with pretrained encoder backbones based on Imagenet Dataset. The network achieves IoU score of 0.65 and F1-score of 0.71 over the validation dataset. We also compare the various architectures in terms of their memory footprint and inference latency with further exploration of the impact of TensorRT based optimizations. We achieve memory savings of ~4.1x and latency improvement of 10% compared to Model: FPN and Backbone: InceptionResnetV2.
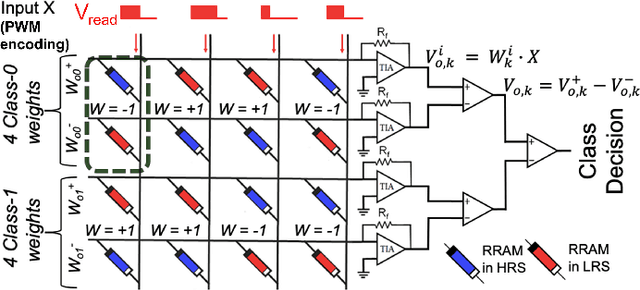
Methodology for Realizing VMM with Binary RRAM Arrays: Experimental Demonstration of Binarized-ADALINE Using OxRAM Crossbar
Jun 10, 2020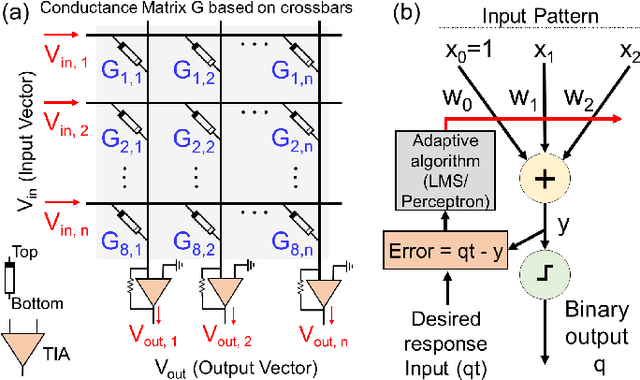


In this paper, we present an efficient hardware mapping methodology for realizing vector matrix multiplication (VMM) on resistive memory (RRAM) arrays. Using the proposed VMM computation technique, we experimentally demonstrate a binarized-ADALINE (Adaptive Linear) classifier on an OxRAM crossbar. An 8x8 OxRAM crossbar with Ni/3-nm HfO2/7 nm Al-doped-TiO2/TiN device stack is used. Weight training for the binarized-ADALINE classifier is performed ex-situ on UCI cancer dataset. Post weight generation the OxRAM array is carefully programmed to binary weight-states using the proposed weight mapping technique on a custom-built testbench. Our VMM powered binarized-ADALINE network achieves a classification accuracy of 78% in simulation and 67% in experiments. Experimental accuracy was found to drop mainly due to crossbar inherent sneak-path issues and RRAM device programming variability.