 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAX: Co-Designing Neural Network and Hardware Architecture for Memristive Xbar based Computing Systems
Jun 23, 2021
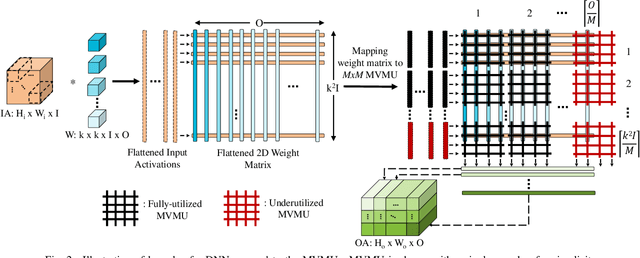
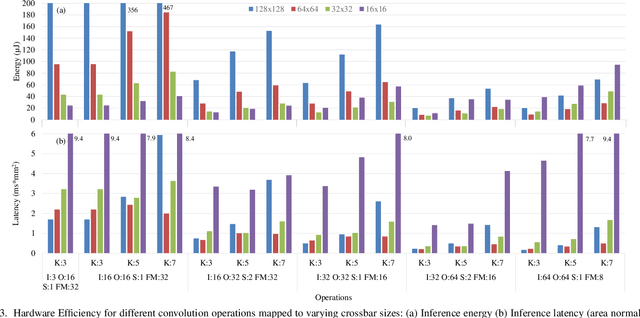

In-Memory Computing (IMC) hardware using Memristive Crossbar Arrays (MCAs) are gaining popularity to accelerate Deep Neural Networks (DNNs) since it alleviates the "memory wall" problem associated with von-Neumann architecture. The hardware efficiency (energy, latency and area) as well as application accuracy (considering device and circuit non-idealities) of DNNs mapped to such hardware are co-dependent on network parameters, such as kernel size, depth etc. and hardware architecture parameters such as crossbar size. However, co-optimization of both network and hardware parameters presents a challenging search space comprising of different kernel sizes mapped to varying crossbar sizes. To that effect, we propose NAX -- an efficient neural architecture search engine that co-designs neural network and IMC based hardware architecture. NAX explores the aforementioned search space to determine kernel and corresponding crossbar sizes for each DNN layer to achieve optimal tradeoffs between hardware efficiency and application accuracy. Our results from NAX show that the networks have heterogeneous crossbar sizes across different network layers, and achieves optimal hardware efficiency and accuracy considering the non-idealities in crossbars. On CIFAR-10 and Tiny ImageNet, our models achieve 0.8%, 0.2% higher accuracy, and 17%, 4% lower EDAP (energy-delay-area product) compared to a baseline ResNet-20 and ResNet-18 models, respectively.
Structured Compression and Sharing of Representational Space for Continual Learning
Jan 29, 2020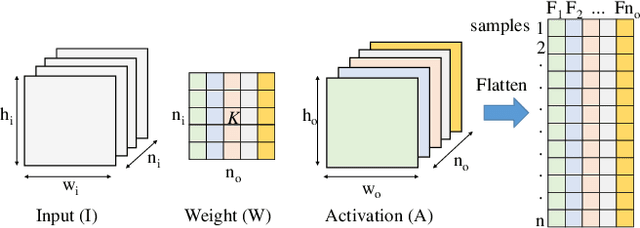
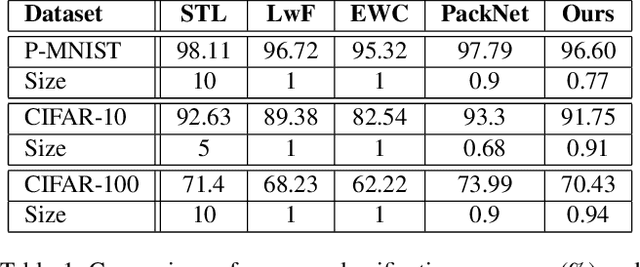
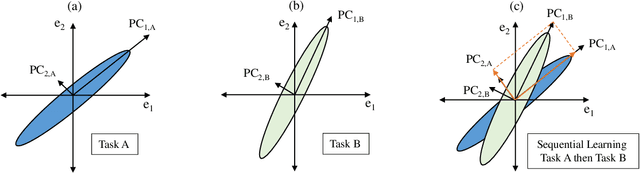
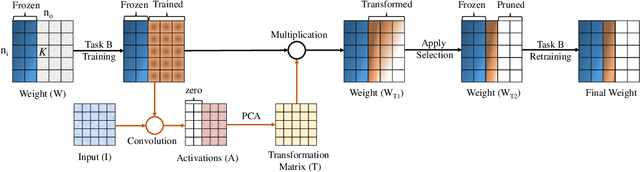
Humans are skilled at learning adaptively and efficiently throughout their lives, but learning tasks incrementally causes artificial neural networks to overwrite relevant information learned about older tasks, resulting in 'Catastrophic Forgetting'. Efforts to overcome this phenomenon suffer from poor utilization of resources in many ways, such as through the need to save older data or parametric importance scores, or to grow the network architecture. We propose an algorithm that enables a network to learn continually and efficiently by partitioning the representational space into a Core space, that contains the condensed information from previously learned tasks, and a Residual space, which is akin to a scratch space for learning the current task. The information in the Residual space is then compressed using Principal Component Analysis and added to the Core space, freeing up parameters for the next task. We evaluate our algorithm on P-MNIST, CIFAR-10 and CIFAR-100 datasets. We achieve comparable accuracy to state-of-the-art methods while overcoming the problem of catastrophic forgetting completely. Additionally, we get up to 4.5x improvement in energy efficiency during inference due to the structured nature of the resulting architecture.
PABO: Pseudo Agent-Based Multi-Objective Bayesian Hyperparameter Optimization for Efficient Neural Accelerator Design
Jun 11, 2019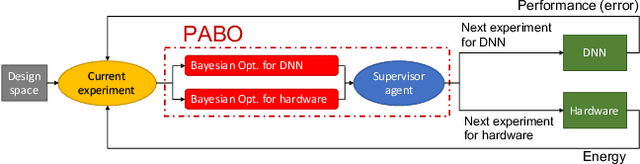
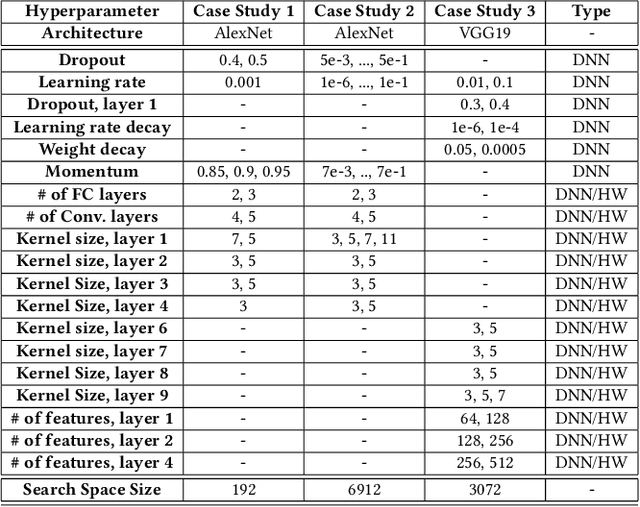


The ever increasing computational cost of Deep Neural Networks (DNN) and the demand for energy efficient hardware for DNN acceleration has made accuracy and hardware cost co-optimization for DNNs tremendously important, especially for edge devices. Owing to the large parameter space and cost of evaluating each parameter in the search space, manually tuning of DNN hyperparameters is impractical. Automatic joint DNN and hardware hyperparameter optimization is indispensable for such problems. Bayesian optimization-based approaches have shown promising results for hyperparameter optimization of DNNs. However, most of these techniques have been developed without considering the underlying hardware, thereby leading to inefficient designs. Further, the few works that perform joint optimization are not generalizable and mainly focus on CMOS-based architectures. In this work, we present a novel pseudo agent-based multi-objective hyperparameter optimization (PABO) for maximizing the DNN performance while obtaining low hardware cost. Compared to the existing methods, our work poses a theoretically different approach for joint optimization of accuracy and hardware cost and focuses on memristive crossbar-based accelerators. PABO uses a supervisor agent to establish connections between the posterior Gaussian distribution models of network accuracy and hardware cost requirements. The agent reduces the mathematical complexity of the co-optimization problem by removing unnecessary computations and updates of acquisition functions, thereby achieving significant speed-ups for the optimization procedure. PABO outputs a Pareto frontier that underscores the trade-offs between designing high-accuracy and hardware efficiency. Our results demonstrate a superior performance compared to the state-of-the-art methods both in terms of accuracy and computational speed (~100x speed up).
PCA-driven Hybrid network design for enabling Intelligence at the Edge
Jun 04, 2019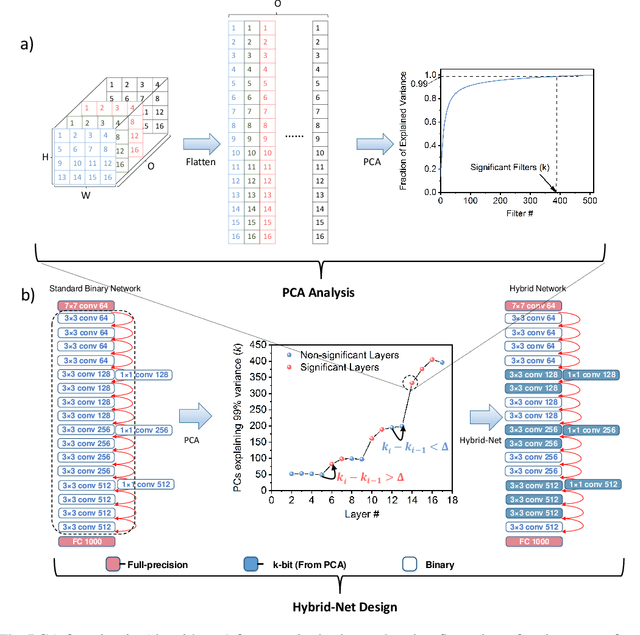

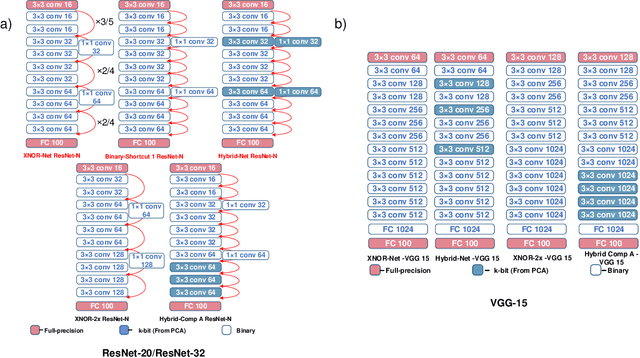
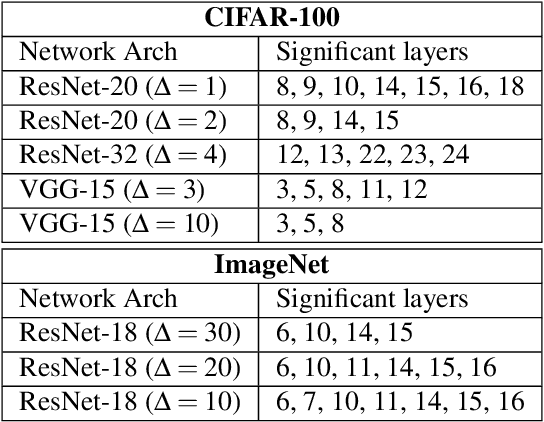
The recent advent of IOT has increased the demand for enabling AI-based edge computing in several applications including healthcare monitoring systems, autonomous vehicles etc. This has necessitated the search for efficient implementations of neural networks in terms of both computation and storage. Although extreme quantization has proven to be a powerful tool to achieve significant compression over full-precision networks, it can result in significant degradation in performance for complex image classification tasks. In this work, we propose a Principal Component Analysis (PCA) driven methodology to design mixed-precision, hybrid networks. Unlike standard practices of using PCA for dimensionality reduction, we leverage PCA to identify significant layers in a binary network which contribute relevant transformations on the input data by increasing the number of significant dimensions. Subsequently, we propose Hybrid-Net, a network with increased bit-precision of the weights and activations of the significant layers in a binary network. We show that the proposed Hybrid-Net achieves over 10% improvement in classification accuracy over binary networks such as XNOR-Net for ResNet and VGG architectures on CIFAR-100 and ImageNet datasets while still achieving upto 94% of the energy-efficiency of XNOR-Nets. The proposed design methodology allows us to move closer to the accuracy of standard full-precision networks by keeping more than half of the network binary. This work demonstrates an effective, one-shot methodology for designing hybrid, mixed-precision networks which significantly improve the classification performance of binary networks while attaining remarkable compression. The proposed hybrid networks further the feasibility of using highly compressed neural networks for energy-efficient neural computing in IOT-based edge devices.
Efficient Hybrid Network Architectures for Extremely Quantized Neural Networks Enabling Intelligence at the Edge
Feb 01, 2019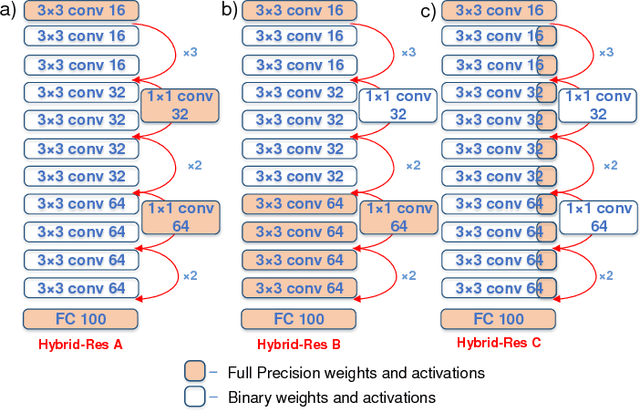

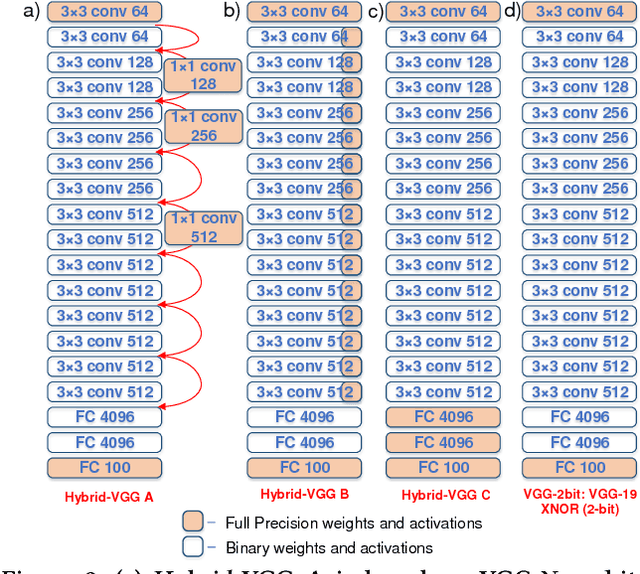
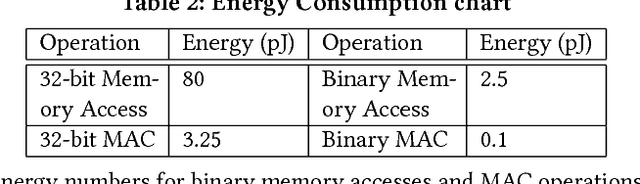
The recent advent of `Internet of Things' (IOT) has increased the demand for enabling AI-based edge computing. This has necessitated the search for efficient implementations of neural networks in terms of both computations and storage. Although extreme quantization has proven to be a powerful tool to achieve significant compression over full-precision networks, it can result in significant degradation in performance. In this work, we propose extremely quantized hybrid network architectures with both binary and full-precision sections to emulate the classification performance of full-precision networks while ensuring significant energy efficiency and memory compression. We explore several hybrid network architectures and analyze the performance of the networks in terms of accuracy, energy efficiency and memory compression. We perform our analysis on ResNet and VGG network architectures. Among the proposed network architectures, we show that the hybrid networks with full-precision residual connections emerge as the optimum by attaining accuracies close to full-precision networks while achieving excellent memory compression, up to 21.8x in case of VGG-19. This work demonstrates an effective way of hybridizing networks which achieve performance close to full-precision networks while attaining significant compression, furthering the feasibility of using such networks for energy-efficient neural computing in IOT-based edge devices.
Incremental Learning in Deep Convolutional Neural Networks Using Partial Network Sharing
Sep 17, 2018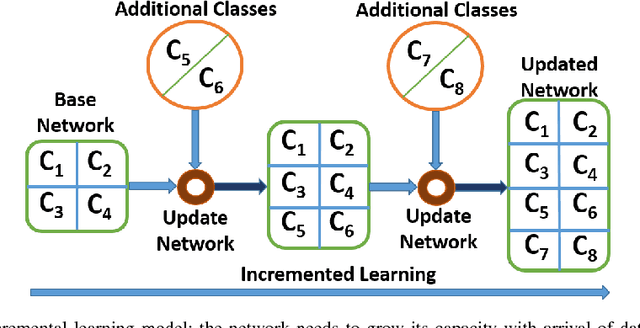
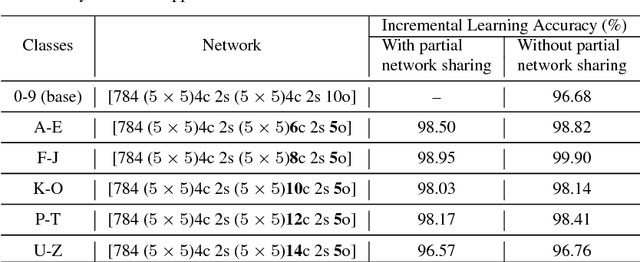


Deep convolutional neural network (DCNN) based supervised learning is a widely practiced approach for large-scale image classification. However, retraining these large networks to accommodate new, previously unseen data demands high computational time and energy requirements. Also, previously seen training samples may not be available at the time of retraining. We propose an efficient training methodology and incrementally growing a DCNN to allow new classes to be learned while sharing part of the base network. Our proposed methodology is inspired by transfer learning techniques, although it does not forget previously learned classes. An updated network for learning new set of classes is formed using previously learned convolutional layers (shared from initial part of base network) with addition of few newly added convolutional kernels included in the later layers of the network. We evaluated the proposed scheme on several recognition applications. The classification accuracy achieved by our approach is comparable to the regular incremental learning approach (where networks are updated with new training samples only, without any network sharing).
TraNNsformer: Neural network transformation for memristive crossbar based neuromorphic system design
Mar 04, 2018
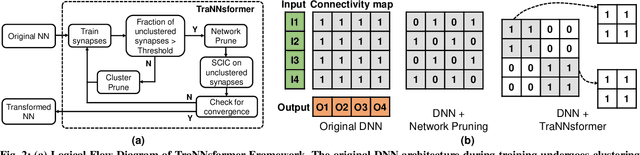

Implementation of Neuromorphic Systems using post Complementary Metal-Oxide-Semiconductor (CMOS) technology based Memristive Crossbar Array (MCA) has emerged as a promising solution to enable low-power acceleration of neural networks. However, the recent trend to design Deep Neural Networks (DNNs) for achieving human-like cognitive abilities poses significant challenges towards the scalable design of neuromorphic systems (due to the increase in computation/storage demands). Network pruning [7] is a powerful technique to remove redundant connections for designing optimally connected (maximally sparse) DNNs. However, such pruning techniques induce irregular connections that are incoherent to the crossbar structure. Eventually they produce DNNs with highly inefficient hardware realizations (in terms of area and energy). In this work, we propose TraNNsformer - an integrated training framework that transforms DNNs to enable their efficient realization on MCA-based systems. TraNNsformer first prunes the connectivity matrix while forming clusters with the remaining connections. Subsequently, it retrains the network to fine tune the connections and reinforce the clusters. This is done iteratively to transform the original connectivity into an optimally pruned and maximally clustered mapping. Without accuracy loss, TraNNsformer reduces the area (energy) consumption by 28% - 55% (49% - 67%) with respect to the original network. Compared to network pruning, TraNNsformer achieves 28% - 49% (15% - 29%) area (energy) savings. Furthermore, TraNNsformer is a technology-aware framework that allows mapping a given DNN to any MCA size permissible by the memristive technology for reliable operations.
FALCON: Feature Driven Selective Classification for Energy-Efficient Image Recognition
Mar 08, 2017



Machine-learning algorithms have shown outstanding image recognition or classification performance for computer vision applications. However, the compute and energy requirement for implementing such classifier models for large-scale problems is quite high. In this paper, we propose Feature Driven Selective Classification (FALCON) inspired by the biological visual attention mechanism in the brain to optimize the energy-efficiency of machine-learning classifiers. We use the consensus in the characteristic features (color/texture) across images in a dataset to decompose the original classification problem and construct a tree of classifiers (nodes) with a generic-to-specific transition in the classification hierarchy. The initial nodes of the tree separate the instances based on feature information and selectively enable the latter nodes to perform object specific classification. The proposed methodology allows selective activation of only those branches and nodes of the classification tree that are relevant to the input while keeping the remaining nodes idle. Additionally, we propose a programmable and scalable Neuromorphic Engine (NeuE) that utilizes arrays of specialized neural computational elements to execute the FALCON based classifier models for diverse datasets. The structure of FALCON facilitates the reuse of nodes while scaling up from small classification problems to larger ones thus allowing us to construct classifier implementations that are significantly more efficient. We evaluate our approach for a 12-object classification task on the Caltech101 dataset and 10-object task on CIFAR-10 dataset by constructing FALCON models on the NeuE platform in 45nm technology. Our results demonstrate significant improvement in energy-efficiency and training time for minimal loss in output quality.
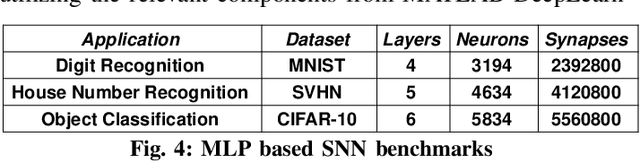
RESPARC: A Reconfigurable and Energy-Efficient Architecture with Memristive Crossbars for Deep Spiking Neural Networks
Feb 20, 2017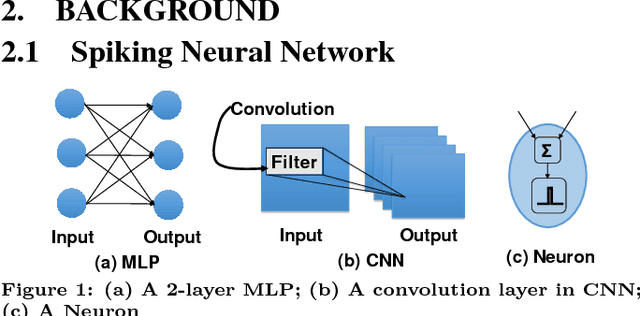


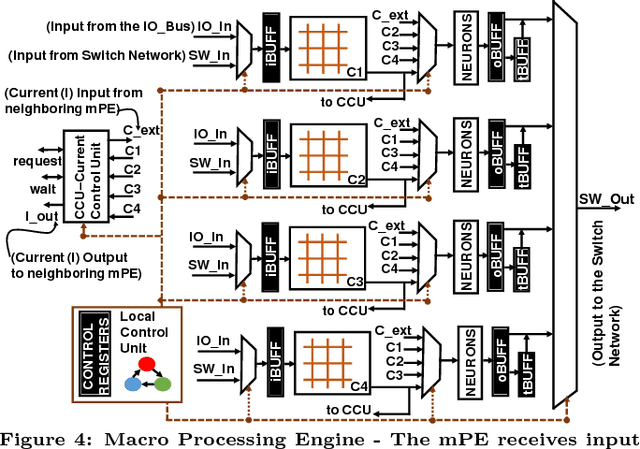
Neuromorphic computing using post-CMOS technologies is gaining immense popularity due to its promising abilities to address the memory and power bottlenecks in von-Neumann computing systems. In this paper, we propose RESPARC - a reconfigurable and energy efficient architecture built-on Memristive Crossbar Arrays (MCA) for deep Spiking Neural Networks (SNNs). Prior works were primarily focused on device and circuit implementations of SNNs on crossbars. RESPARC advances this by proposing a complete system for SNN acceleration and its subsequent analysis. RESPARC utilizes the energy-efficiency of MCAs for inner-product computation and realizes a hierarchical reconfigurable design to incorporate the data-flow patterns in an SNN in a scalable fashion. We evaluate the proposed architecture on different SNNs ranging in complexity from 2k-230k neurons and 1.2M-5.5M synapses. Simulation results on these networks show that compared to the baseline digital CMOS architecture, RESPARC achieves 500X (15X) efficiency in energy benefits at 300X (60X) higher throughput for multi-layer perceptrons (deep convolutional networks). Furthermore, RESPARC is a technology-aware architecture that maps a given SNN topology to the most optimized MCA size for the given crossbar technology.