 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Cost-effective Speculative Edge-Cloud Decoding with Early Exits
May 27, 2025Large Language Models (LLMs) enable various applications on edge devices such as smartphones, wearables, and embodied robots. However, their deployment often depends on expensive cloud-based APIs, creating high operational costs, which limit access for smaller organizations and raise sustainability concerns. Certain LLMs can be deployed on-device, offering a cost-effective solution with reduced latency and improved privacy. Yet, limited computing resources constrain the size and accuracy of models that can be deployed, necessitating a collaborative design between edge and cloud. We propose a fast and cost-effective speculative edge-cloud decoding framework with a large target model on the server and a small draft model on the device. By introducing early exits in the target model, tokens are generated mid-verification, allowing the client to preemptively draft subsequent tokens before final verification, thus utilizing idle time and enhancing parallelism between edge and cloud. Using an NVIDIA Jetson Nano (client) and an A100 GPU (server) with Vicuna-68M (draft) and Llama2-7B (target) models, our method achieves up to a 35% reduction in latency compared to cloud-based autoregressive decoding, with an additional 11% improvement from preemptive drafting. To demonstrate real-world applicability, we deploy our method on the Unitree Go2 quadruped robot using Vision-Language Model (VLM) based control, achieving a 21% speedup over traditional cloud-based autoregressive decoding. These results demonstrate the potential of our framework for real-time LLM and VLM applications on resource-constrained edge devices.
Event2Vec: Processing neuromorphic events directly by representations in vector space
Apr 21, 2025



The neuromorphic event cameras have overwhelming advantages in temporal resolution, power efficiency, and dynamic range compared to traditional cameras. However, the event cameras output asynchronous, sparse, and irregular events, which are not compatible with mainstream computer vision and deep learning methods. Various methods have been proposed to solve this issue but at the cost of long preprocessing procedures, losing temporal resolutions, or being incompatible with massively parallel computation. Inspired by the great success of the word to vector, we summarize the similarities between words and events, then propose the first event to vector (event2vec) representation. We validate event2vec on classifying the ASL-DVS dataset, showing impressive parameter efficiency, accuracy, and speed than previous graph/image/voxel-based representations. Beyond task performance, the most attractive advantage of event2vec is that it aligns events to the domain of natural language processing, showing the promising prospect of integrating events into large language and multimodal models. Our codes, models, and training logs are available at https://github.com/fangwei123456/event2vec.
GPTQv2: Efficient Finetuning-Free Quantization for Asymmetric Calibration
Apr 03, 2025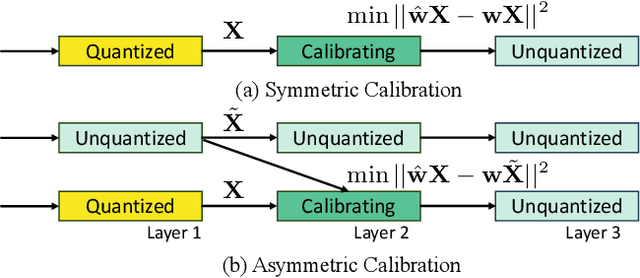
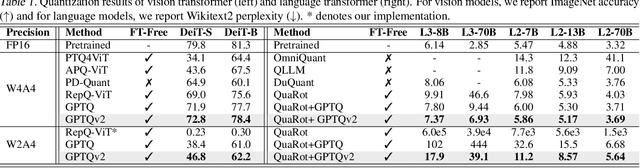
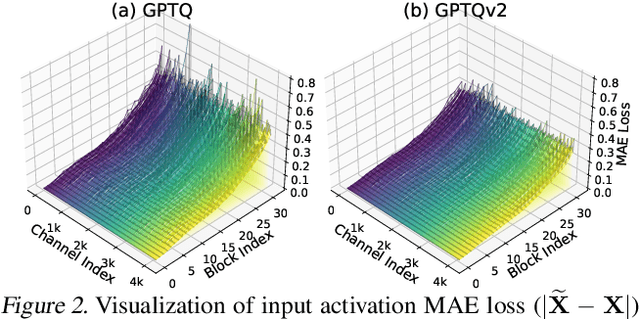
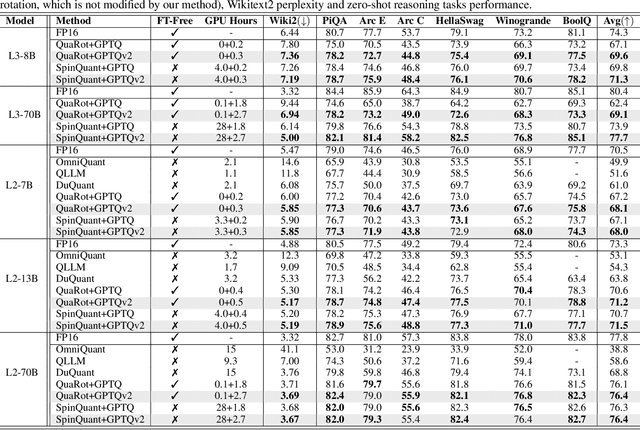
We introduce GPTQv2, a novel finetuning-free quantization method for compressing large-scale transformer architectures. Unlike the previous GPTQ method, which independently calibrates each layer, we always match the quantized layer's output to the exact output in the full-precision model, resulting in a scheme that we call asymmetric calibration. Such a scheme can effectively reduce the quantization error accumulated in previous layers. We analyze this problem using optimal brain compression to derive a close-formed solution. The new solution explicitly minimizes the quantization error as well as the accumulated asymmetry error. Furthermore, we utilize various techniques to parallelize the solution calculation, including channel parallelization, neuron decomposition, and Cholesky reformulation for matrix fusion. As a result, GPTQv2 is easy to implement, simply using 20 more lines of code than GPTQ but improving its performance under low-bit quantization. Remarkably, on a single GPU, we quantize a 405B language transformer as well as EVA-02 the rank first vision transformer that achieves 90% pretraining Imagenet accuracy. Code is available at github.com/Intelligent-Computing-Lab-Yale/GPTQv2.
Low-power Spike-based Wearable Analytics on RRAM Crossbars
Feb 10, 2025



This work introduces a spike-based wearable analytics system utilizing Spiking Neural Networks (SNNs) deployed on an In-memory Computing engine based on RRAM crossbars, which are known for their compactness and energy-efficiency. Given the hardware constraints and noise characteristics of the underlying RRAM crossbars, we propose online adaptation of pre-trained SNNs in real-time using Direct Feedback Alignment (DFA) against traditional backpropagation (BP). Direct Feedback Alignment (DFA) learning, that allows layer-parallel gradient computations, acts as a fast, energy & area-efficient method for online adaptation of SNNs on RRAM crossbars, unleashing better algorithmic performance against those adapted using BP. Through extensive simulations using our in-house hardware evaluation engine called DFA_Sim, we find that DFA achieves upto 64.1% lower energy consumption, 10.1% lower area overhead, and a 2.1x reduction in latency compared to BP, while delivering upto 7.55% higher inference accuracy on human activity recognition (HAR) tasks.
* Accepted in 2025 IEEE International Symposium on Circuits and Systems (ISCAS)
Intelligent Sensing-to-Action for Robust Autonomy at the Edge: Opportunities and Challenges
Feb 04, 2025Autonomous edge computing in robotics, smart cities, and autonomous vehicles relies on the seamless integration of sensing, processing, and actuation for real-time decision-making in dynamic environments. At its core is the sensing-to-action loop, which iteratively aligns sensor inputs with computational models to drive adaptive control strategies. These loops can adapt to hyper-local conditions, enhancing resource efficiency and responsiveness, but also face challenges such as resource constraints, synchronization delays in multi-modal data fusion, and the risk of cascading errors in feedback loops. This article explores how proactive, context-aware sensing-to-action and action-to-sensing adaptations can enhance efficiency by dynamically adjusting sensing and computation based on task demands, such as sensing a very limited part of the environment and predicting the rest. By guiding sensing through control actions, action-to-sensing pathways can improve task relevance and resource use, but they also require robust monitoring to prevent cascading errors and maintain reliability. Multi-agent sensing-action loops further extend these capabilities through coordinated sensing and actions across distributed agents, optimizing resource use via collaboration. Additionally, neuromorphic computing, inspired by biological systems, provides an efficient framework for spike-based, event-driven processing that conserves energy, reduces latency, and supports hierarchical control--making it ideal for multi-agent optimization. This article highlights the importance of end-to-end co-design strategies that align algorithmic models with hardware and environmental dynamics and improve cross-layer interdependencies to improve throughput, precision, and adaptability for energy-efficient edge autonomy in complex environments.
TesseraQ: Ultra Low-Bit LLM Post-Training Quantization with Block Reconstruction
Oct 24, 2024



Large language models (LLMs) have revolutionized natural language processing, albeit at the cost of immense memory and computation requirements. Post-training quantization (PTQ) is becoming the de facto method to reduce the memory footprint and improve the inference throughput of LLMs. In this work, we aim to push the upper limit of LLM PTQ by optimizing the weight rounding parameters with the block reconstruction technique, a predominant method in previous vision models. We propose TesseraQ, a new state-of-the-art PTQ technique, to quantize the weights of LLMs to ultra-low bits. To effectively optimize the rounding in LLMs and stabilize the reconstruction process, we introduce progressive adaptive rounding. This approach iteratively transits the soft rounding variables to hard variables during the reconstruction process. Additionally, we optimize the dequantization scale parameters to fully leverage the block reconstruction technique. We demonstrate that TesseraQ can be seamlessly integrated with existing scaling or clipping-based PTQ algorithms such as AWQ and OmniQuant, significantly enhancing their performance and establishing a new state-of-the-art. For instance, when compared to AWQ, TesseraQ improves the wikitext2 perplexity from 14.65 to 6.82 and average downstream accuracy from 50.52 to 59.27 with 2-bit weight-only quantization of LLaMA-2-7B. Across a range of quantization schemes, including W2A16, W3A16, W3A3, and W4A4, TesseraQ consistently exhibits superior performance.
Spiking Transformer with Spatial-Temporal Attention
Sep 29, 2024



Spiking Neural Networks (SNNs) present a compelling and energy-efficient alternative to traditional Artificial Neural Networks (ANNs) due to their sparse binary activation. Leveraging the success of the transformer architecture, the spiking transformer architecture is explored to scale up dataset size and performance. However, existing works only consider the spatial self-attention in spiking transformer, neglecting the inherent temporal context across the timesteps. In this work, we introduce Spiking Transformer with Spatial-Temporal Attention (STAtten), a simple and straightforward architecture designed to integrate spatial and temporal information in self-attention with negligible additional computational load. The STAtten divides the temporal or token index and calculates the self-attention in a cross-manner to effectively incorporate spatial-temporal information. We first verify our spatial-temporal attention mechanism's ability to capture long-term temporal dependencies using sequential datasets. Moreover, we validate our approach through extensive experiments on varied datasets, including CIFAR10/100, ImageNet, CIFAR10-DVS, and N-Caltech101. Notably, our cross-attention mechanism achieves an accuracy of 78.39 % on the ImageNet dataset.
ReSpike: Residual Frames-based Hybrid Spiking Neural Networks for Efficient Action Recognition
Sep 03, 2024Spiking Neural Networks (SNNs) have emerged as a compelling, energy-efficient alternative to traditional Artificial Neural Networks (ANNs) for static image tasks such as image classification and segmentation. However, in the more complex video classification domain, SNN-based methods fall considerably short of ANN-based benchmarks due to the challenges in processing dense frame sequences. To bridge this gap, we propose ReSpike, a hybrid framework that synergizes the strengths of ANNs and SNNs to tackle action recognition tasks with high accuracy and low energy cost. By decomposing film clips into spatial and temporal components, i.e., RGB image Key Frames and event-like Residual Frames, ReSpike leverages ANN for learning spatial information and SNN for learning temporal information. In addition, we propose a multi-scale cross-attention mechanism for effective feature fusion. Compared to state-of-the-art SNN baselines, our ReSpike hybrid architecture demonstrates significant performance improvements (e.g., >30% absolute accuracy improvement on HMDB-51, UCF-101, and Kinetics-400). Furthermore, ReSpike achieves comparable performance with prior ANN approaches while bringing better accuracy-energy tradeoff.
TReX- Reusing Vision Transformer's Attention for Efficient Xbar-based Computing
Aug 22, 2024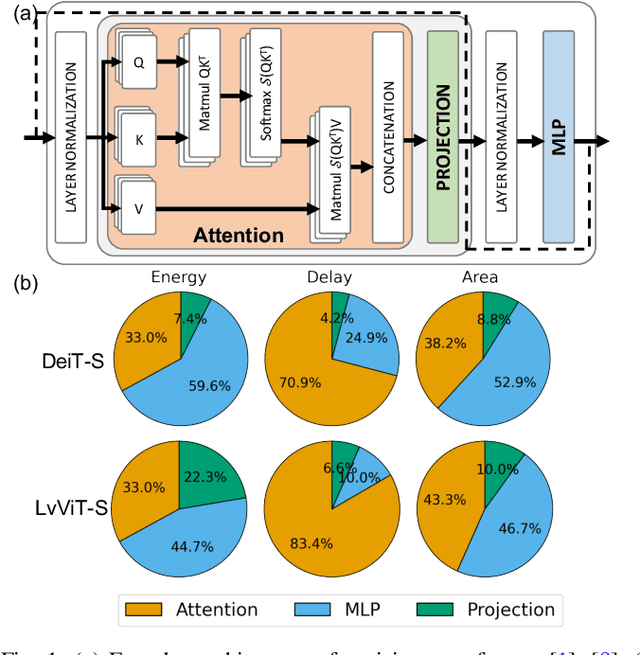
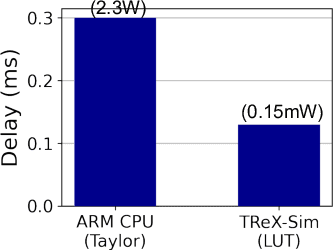
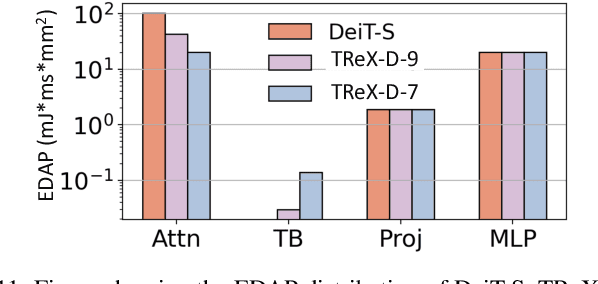
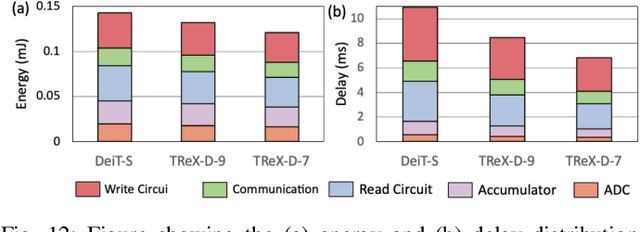
Due to the high computation overhead of Vision Transformers (ViTs), In-memory Computing architectures are being researched towards energy-efficient deployment in edge-computing scenarios. Prior works have proposed efficient algorithm-hardware co-design and IMC-architectural improvements to improve the energy-efficiency of IMC-implemented ViTs. However, all prior works have neglected the overhead and co-depencence of attention blocks on the accuracy-energy-delay-area of IMC-implemented ViTs. To this end, we propose TReX- an attention-reuse-driven ViT optimization framework that effectively performs attention reuse in ViT models to achieve optimal accuracy-energy-delay-area tradeoffs. TReX optimally chooses the transformer encoders for attention reuse to achieve near iso-accuracy performance while meeting the user-specified delay requirement. Based on our analysis on the Imagenet-1k dataset, we find that TReX achieves 2.3x (2.19x) EDAP reduction and 1.86x (1.79x) TOPS/mm2 improvement with ~1% accuracy drop in case of DeiT-S (LV-ViT-S) ViT models. Additionally, TReX achieves high accuracy at high EDAP reduction compared to state-of-the-art token pruning and weight sharing approaches. On NLP tasks such as CoLA, TReX leads to 2% higher non-ideal accuracy compared to baseline at 1.6x lower EDAP.
When In-memory Computing Meets Spiking Neural Networks -- A Perspective on Device-Circuit-System-and-Algorithm Co-design
Aug 22, 2024



This review explores the intersection of bio-plausible artificial intelligence in the form of Spiking Neural Networks (SNNs) with the analog In-Memory Computing (IMC) domain, highlighting their collective potential for low-power edge computing environments. Through detailed investigation at the device, circuit, and system levels, we highlight the pivotal synergies between SNNs and IMC architectures. Additionally, we emphasize the critical need for comprehensive system-level analyses, considering the inter-dependencies between algorithms, devices, circuit & system parameters, crucial for optimal performance. An in-depth analysis leads to identification of key system-level bottlenecks arising from device limitations which can be addressed using SNN-specific algorithm-hardware co-design techniques. This review underscores the imperative for holistic device to system design space co-exploration, highlighting the critical aspects of hardware and algorithm research endeavors for low-power neuromorphic solutions.