 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Graph Structure Estimation for Learning Multivariate Point Process using Spiking Neural Networks
Apr 01, 2025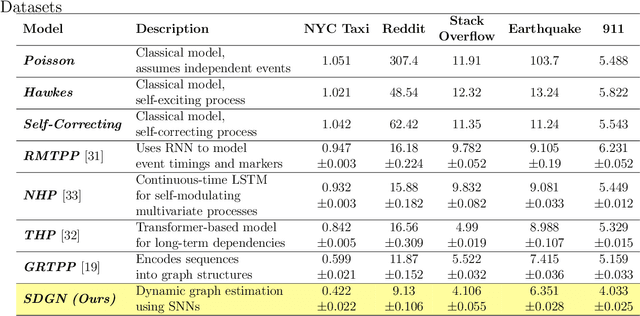
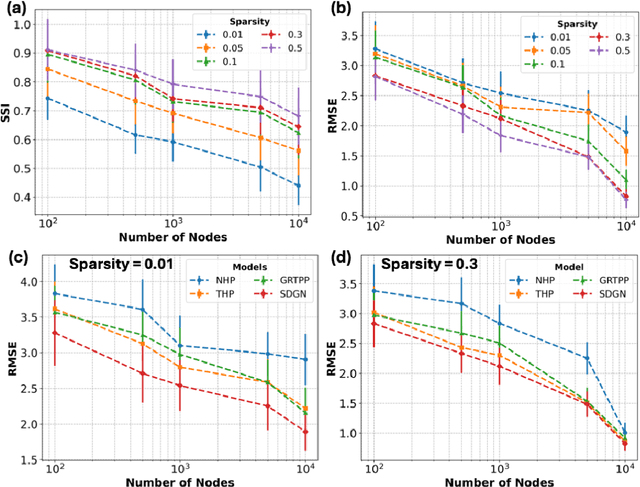
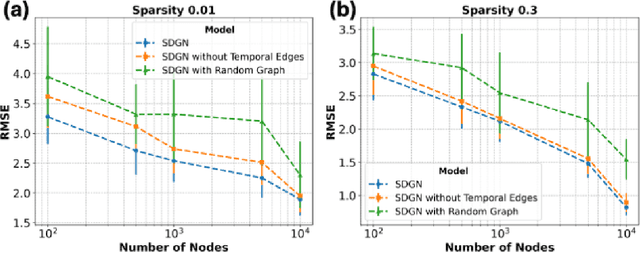
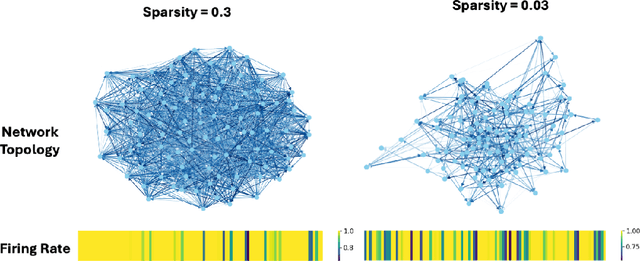
Modeling and predicting temporal point processes (TPPs) is critical in domains such as neuroscience, epidemiology, finance, and social sciences. We introduce the Spiking Dynamic Graph Network (SDGN), a novel framework that leverages the temporal processing capabilities of spiking neural networks (SNNs) and spike-timing-dependent plasticity (STDP) to dynamically estimate underlying spatio-temporal functional graphs. Unlike existing methods that rely on predefined or static graph structures, SDGN adapts to any dataset by learning dynamic spatio-temporal dependencies directly from the event data, enhancing generalizability and robustness. While SDGN offers significant improvements over prior methods, we acknowledge its limitations in handling dense graphs and certain non-Gaussian dependencies, providing opportunities for future refinement. Our evaluations, conducted on both synthetic and real-world datasets including NYC Taxi, 911, Reddit, and Stack Overflow, demonstrate that SDGN achieves superior predictive accuracy while maintaining computational efficiency. Furthermore, we include ablation studies to highlight the contributions of its core components.
Intelligent Sensing-to-Action for Robust Autonomy at the Edge: Opportunities and Challenges
Feb 04, 2025Autonomous edge computing in robotics, smart cities, and autonomous vehicles relies on the seamless integration of sensing, processing, and actuation for real-time decision-making in dynamic environments. At its core is the sensing-to-action loop, which iteratively aligns sensor inputs with computational models to drive adaptive control strategies. These loops can adapt to hyper-local conditions, enhancing resource efficiency and responsiveness, but also face challenges such as resource constraints, synchronization delays in multi-modal data fusion, and the risk of cascading errors in feedback loops. This article explores how proactive, context-aware sensing-to-action and action-to-sensing adaptations can enhance efficiency by dynamically adjusting sensing and computation based on task demands, such as sensing a very limited part of the environment and predicting the rest. By guiding sensing through control actions, action-to-sensing pathways can improve task relevance and resource use, but they also require robust monitoring to prevent cascading errors and maintain reliability. Multi-agent sensing-action loops further extend these capabilities through coordinated sensing and actions across distributed agents, optimizing resource use via collaboration. Additionally, neuromorphic computing, inspired by biological systems, provides an efficient framework for spike-based, event-driven processing that conserves energy, reduces latency, and supports hierarchical control--making it ideal for multi-agent optimization. This article highlights the importance of end-to-end co-design strategies that align algorithmic models with hardware and environmental dynamics and improve cross-layer interdependencies to improve throughput, precision, and adaptability for energy-efficient edge autonomy in complex environments.
AdaCred: Adaptive Causal Decision Transformers with Feature Crediting
Dec 19, 2024



Reinforcement learning (RL) can be formulated as a sequence modeling problem, where models predict future actions based on historical state-action-reward sequences. Current approaches typically require long trajectory sequences to model the environment in offline RL settings. However, these models tend to over-rely on memorizing long-term representations, which impairs their ability to effectively attribute importance to trajectories and learned representations based on task-specific relevance. In this work, we introduce AdaCred, a novel approach that represents trajectories as causal graphs built from short-term action-reward-state sequences. Our model adaptively learns control policy by crediting and pruning low-importance representations, retaining only those most relevant for the downstream task. Our experiments demonstrate that AdaCred-based policies require shorter trajectory sequences and consistently outperform conventional methods in both offline reinforcement learning and imitation learning environments.
RoboKoop: Efficient Control Conditioned Representations from Visual Input in Robotics using Koopman Operator
Sep 04, 2024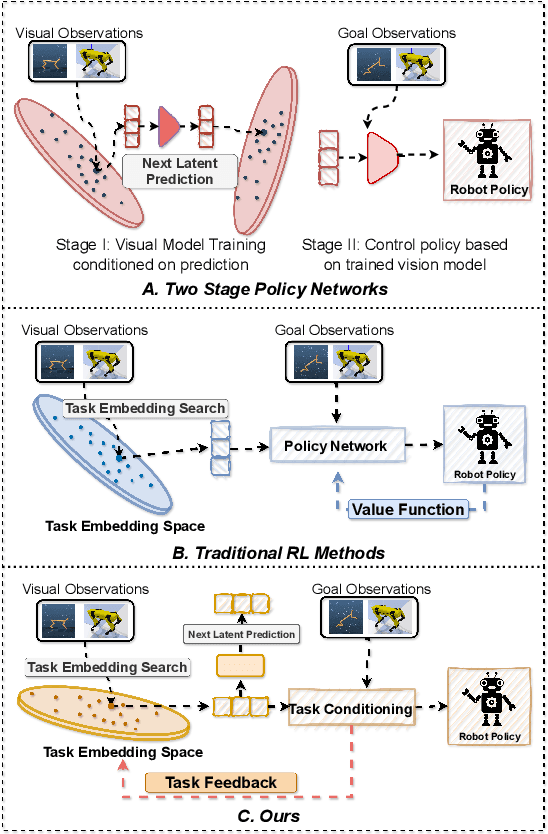

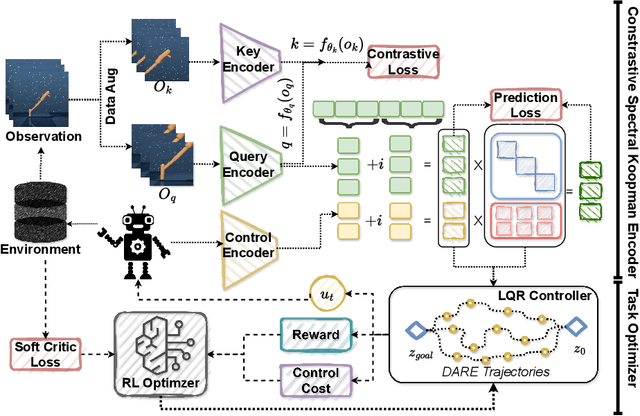
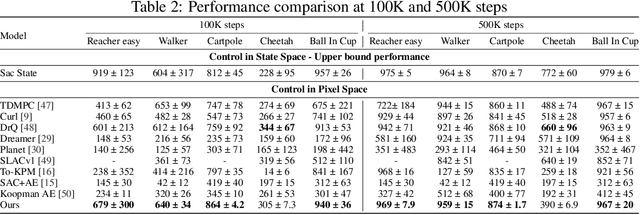
Developing agents that can perform complex control tasks from high-dimensional observations is a core ability of autonomous agents that requires underlying robust task control policies and adapting the underlying visual representations to the task. Most existing policies need a lot of training samples and treat this problem from the lens of two-stage learning with a controller learned on top of pre-trained vision models. We approach this problem from the lens of Koopman theory and learn visual representations from robotic agents conditioned on specific downstream tasks in the context of learning stabilizing control for the agent. We introduce a Contrastive Spectral Koopman Embedding network that allows us to learn efficient linearized visual representations from the agent's visual data in a high dimensional latent space and utilizes reinforcement learning to perform off-policy control on top of the extracted representations with a linear controller. Our method enhances stability and control in gradient dynamics over time, significantly outperforming existing approaches by improving efficiency and accuracy in learning task policies over extended horizons.
Radar Guided Dynamic Visual Attention for Resource-Efficient RGB Object Detection
Jun 03, 2022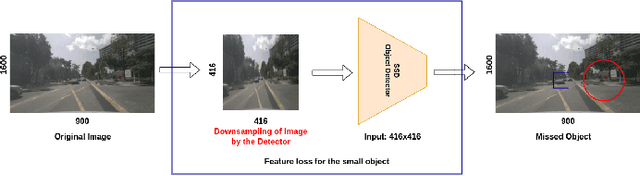



An autonomous system's perception engine must provide an accurate understanding of the environment for it to make decisions. Deep learning based object detection networks experience degradation in the performance and robustness for small and far away objects due to a reduction in object's feature map as we move to higher layers of the network. In this work, we propose a novel radar-guided spatial attention for RGB images to improve the perception quality of autonomous vehicles operating in a dynamic environment. In particular, our method improves the perception of small and long range objects, which are often not detected by the object detectors in RGB mode. The proposed method consists of two RGB object detectors, namely the Primary detector and a lightweight Secondary detector. The primary detector takes a full RGB image and generates primary detections. Next, the radar proposal framework creates regions of interest (ROIs) for object proposals by projecting the radar point cloud onto the 2D RGB image. These ROIs are cropped and fed to the secondary detector to generate secondary detections which are then fused with the primary detections via non-maximum suppression. This method helps in recovering the small objects by preserving the object's spatial features through an increase in their receptive field. We evaluate our fusion method on the challenging nuScenes dataset and show that our fusion method with SSD-lite as primary and secondary detector improves the baseline primary yolov3 detector's recall by 14% while requiring three times fewer computational resources.