 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Cost-effective Speculative Edge-Cloud Decoding with Early Exits
May 27, 2025Large Language Models (LLMs) enable various applications on edge devices such as smartphones, wearables, and embodied robots. However, their deployment often depends on expensive cloud-based APIs, creating high operational costs, which limit access for smaller organizations and raise sustainability concerns. Certain LLMs can be deployed on-device, offering a cost-effective solution with reduced latency and improved privacy. Yet, limited computing resources constrain the size and accuracy of models that can be deployed, necessitating a collaborative design between edge and cloud. We propose a fast and cost-effective speculative edge-cloud decoding framework with a large target model on the server and a small draft model on the device. By introducing early exits in the target model, tokens are generated mid-verification, allowing the client to preemptively draft subsequent tokens before final verification, thus utilizing idle time and enhancing parallelism between edge and cloud. Using an NVIDIA Jetson Nano (client) and an A100 GPU (server) with Vicuna-68M (draft) and Llama2-7B (target) models, our method achieves up to a 35% reduction in latency compared to cloud-based autoregressive decoding, with an additional 11% improvement from preemptive drafting. To demonstrate real-world applicability, we deploy our method on the Unitree Go2 quadruped robot using Vision-Language Model (VLM) based control, achieving a 21% speedup over traditional cloud-based autoregressive decoding. These results demonstrate the potential of our framework for real-time LLM and VLM applications on resource-constrained edge devices.
Intelligent Sensing-to-Action for Robust Autonomy at the Edge: Opportunities and Challenges
Feb 04, 2025Autonomous edge computing in robotics, smart cities, and autonomous vehicles relies on the seamless integration of sensing, processing, and actuation for real-time decision-making in dynamic environments. At its core is the sensing-to-action loop, which iteratively aligns sensor inputs with computational models to drive adaptive control strategies. These loops can adapt to hyper-local conditions, enhancing resource efficiency and responsiveness, but also face challenges such as resource constraints, synchronization delays in multi-modal data fusion, and the risk of cascading errors in feedback loops. This article explores how proactive, context-aware sensing-to-action and action-to-sensing adaptations can enhance efficiency by dynamically adjusting sensing and computation based on task demands, such as sensing a very limited part of the environment and predicting the rest. By guiding sensing through control actions, action-to-sensing pathways can improve task relevance and resource use, but they also require robust monitoring to prevent cascading errors and maintain reliability. Multi-agent sensing-action loops further extend these capabilities through coordinated sensing and actions across distributed agents, optimizing resource use via collaboration. Additionally, neuromorphic computing, inspired by biological systems, provides an efficient framework for spike-based, event-driven processing that conserves energy, reduces latency, and supports hierarchical control--making it ideal for multi-agent optimization. This article highlights the importance of end-to-end co-design strategies that align algorithmic models with hardware and environmental dynamics and improve cross-layer interdependencies to improve throughput, precision, and adaptability for energy-efficient edge autonomy in complex environments.
Examining the Role and Limits of Batchnorm Optimization to Mitigate Diverse Hardware-noise in In-memory Computing
May 28, 2023In-Memory Computing (IMC) platforms such as analog crossbars are gaining focus as they facilitate the acceleration of low-precision Deep Neural Networks (DNNs) with high area- & compute-efficiencies. However, the intrinsic non-idealities in crossbars, which are often non-deterministic and non-linear, degrade the performance of the deployed DNNs. In addition to quantization errors, most frequently encountered non-idealities during inference include crossbar circuit-level parasitic resistances and device-level non-idealities such as stochastic read noise and temporal drift. In this work, our goal is to closely examine the distortions caused by these non-idealities on the dot-product operations in analog crossbars and explore the feasibility of a nearly training-less solution via crossbar-aware fine-tuning of batchnorm parameters in real-time to mitigate the impact of the non-idealities. This enables reduction in hardware costs in terms of memory and training energy for IMC noise-aware retraining of the DNN weights on crossbars.
* Accepted in Great Lakes Symposium on VLSI 2023 (GLSVLSI 2023) conference
Divide-and-Conquer the NAS puzzle in Resource Constrained Federated Learning Systems
May 11, 2023Federated Learning (FL) is a privacy-preserving distributed machine learning approach geared towards applications in edge devices. However, the problem of designing custom neural architectures in federated environments is not tackled from the perspective of overall system efficiency. In this paper, we propose DC-NAS -- a divide-and-conquer approach that performs supernet-based Neural Architecture Search (NAS) in a federated system by systematically sampling the search space. We propose a novel diversified sampling strategy that balances exploration and exploitation of the search space by initially maximizing the distance between the samples and progressively shrinking this distance as the training progresses. We then perform channel pruning to reduce the training complexity at the devices further. We show that our approach outperforms several sampling strategies including Hadamard sampling, where the samples are maximally separated. We evaluate our method on the CIFAR10, CIFAR100, EMNIST, and TinyImagenet benchmarks and show a comprehensive analysis of different aspects of federated learning such as scalability, and non-IID data. DC-NAS achieves near iso-accuracy as compared to full-scale federated NAS with 50% fewer resources.
Exploring Temporal Information Dynamics in Spiking Neural Networks
Nov 30, 2022



Most existing Spiking Neural Network (SNN) works state that SNNs may utilize temporal information dynamics of spikes. However, an explicit analysis of temporal information dynamics is still missing. In this paper, we ask several important questions for providing a fundamental understanding of SNNs: What are temporal information dynamics inside SNNs? How can we measure the temporal information dynamics? How do the temporal information dynamics affect the overall learning performance? To answer these questions, we estimate the Fisher Information of the weights to measure the distribution of temporal information during training in an empirical manner. Surprisingly, as training goes on, Fisher information starts to concentrate in the early timesteps. After training, we observe that information becomes highly concentrated in earlier few timesteps, a phenomenon we refer to as temporal information concentration. We observe that the temporal information concentration phenomenon is a common learning feature of SNNs by conducting extensive experiments on various configurations such as architecture, dataset, optimization strategy, time constant, and timesteps. Furthermore, to reveal how temporal information concentration affects the performance of SNNs, we design a loss function to change the trend of temporal information. We find that temporal information concentration is crucial to building a robust SNN but has little effect on classification accuracy. Finally, we propose an efficient iterative pruning method based on our observation on temporal information concentration. Code is available at https://github.com/Intelligent-Computing-Lab-Yale/Exploring-Temporal-Information-Dynamics-in-Spiking-Neural-Networks.
Lottery Ticket Hypothesis for Spiking Neural Networks
Jul 04, 2022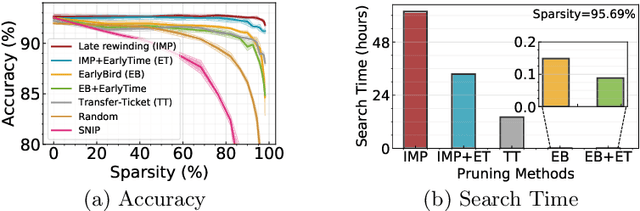
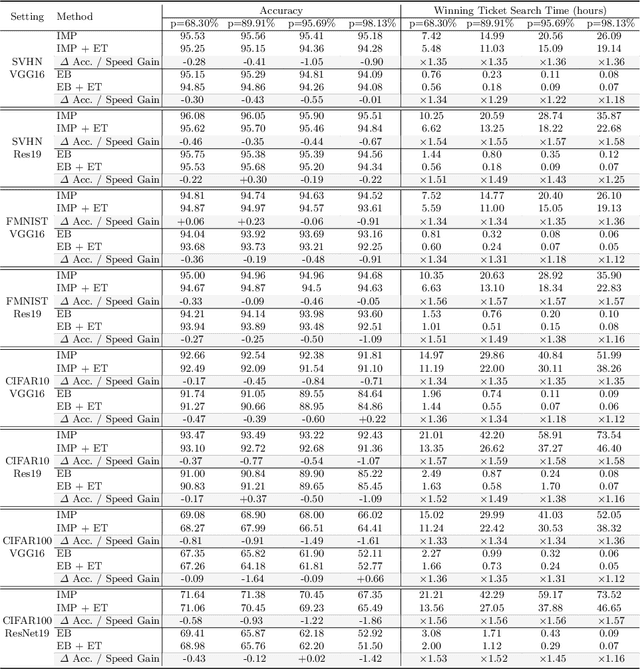
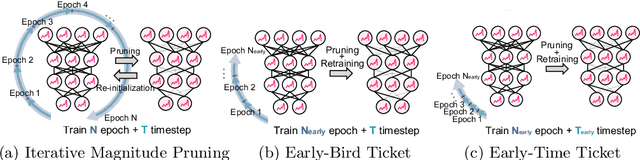
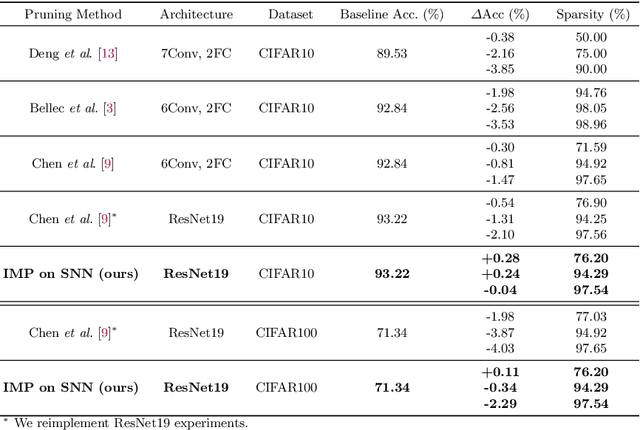
Spiking Neural Networks (SNNs) have recently emerged as a new generation of low-power deep neural networks where binary spikes convey information across multiple timesteps. Pruning for SNNs is highly important as they become deployed on a resource-constraint mobile/edge device. The previous SNN pruning works focus on shallow SNNs (2~6 layers), however, deeper SNNs (>16 layers) are proposed by state-of-the-art SNN works, which is difficult to be compatible with the current pruning work. To scale up a pruning technique toward deep SNNs, we investigate Lottery Ticket Hypothesis (LTH) which states that dense networks contain smaller subnetworks (i.e., winning tickets) that achieve comparable performance to the dense networks. Our studies on LTH reveal that the winning tickets consistently exist in deep SNNs across various datasets and architectures, providing up to 97% sparsity without huge performance degradation. However, the iterative searching process of LTH brings a huge training computational cost when combined with the multiple timesteps of SNNs. To alleviate such heavy searching cost, we propose Early-Time (ET) ticket where we find the important weight connectivity from a smaller number of timesteps. The proposed ET ticket can be seamlessly combined with common pruning techniques for finding winning tickets, such as Iterative Magnitude Pruning (IMP) and Early-Bird (EB) tickets. Our experiment results show that the proposed ET ticket reduces search time by up to 38% compared to IMP or EB methods.
MIME: Adapting a Single Neural Network for Multi-task Inference with Memory-efficient Dynamic Pruning
Apr 11, 2022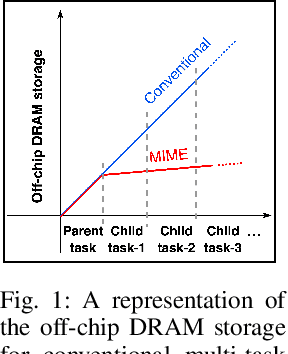
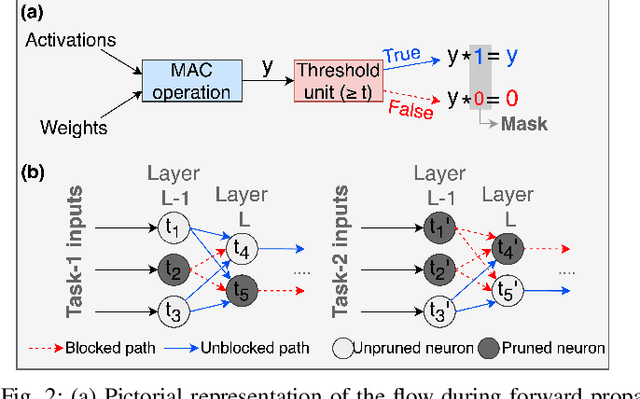
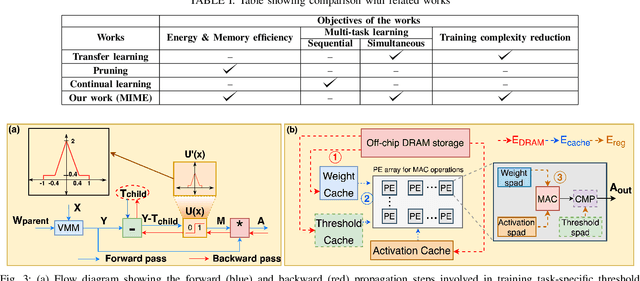
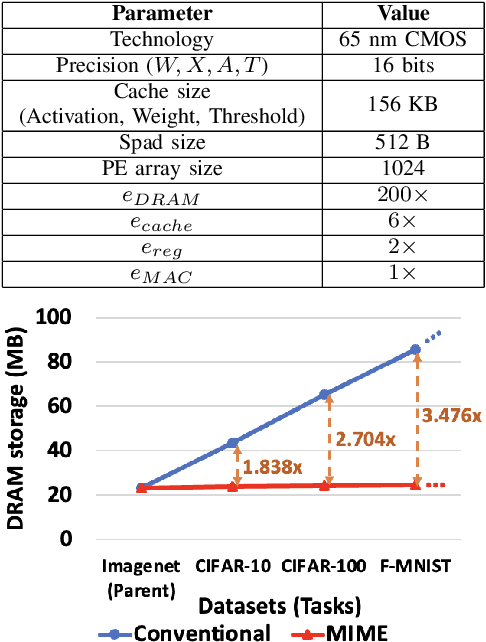
Recent years have seen a paradigm shift towards multi-task learning. This calls for memory and energy-efficient solutions for inference in a multi-task scenario. We propose an algorithm-hardware co-design approach called MIME. MIME reuses the weight parameters of a trained parent task and learns task-specific threshold parameters for inference on multiple child tasks. We find that MIME results in highly memory-efficient DRAM storage of neural-network parameters for multiple tasks compared to conventional multi-task inference. In addition, MIME results in input-dependent dynamic neuronal pruning, thereby enabling energy-efficient inference with higher throughput on a systolic-array hardware. Our experiments with benchmark datasets (child tasks)- CIFAR10, CIFAR100, and Fashion-MNIST, show that MIME achieves ~3.48x memory-efficiency and ~2.4-3.1x energy-savings compared to conventional multi-task inference in Pipelined task mode.
* Accepted in Design Automation Conference (DAC), 2022
Addressing Client Drift in Federated Continual Learning with Adaptive Optimization
Mar 24, 2022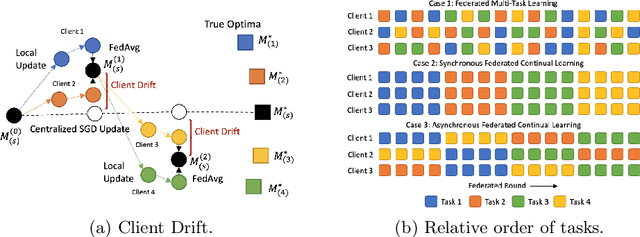
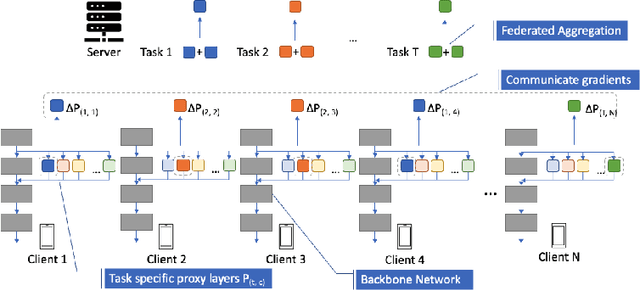
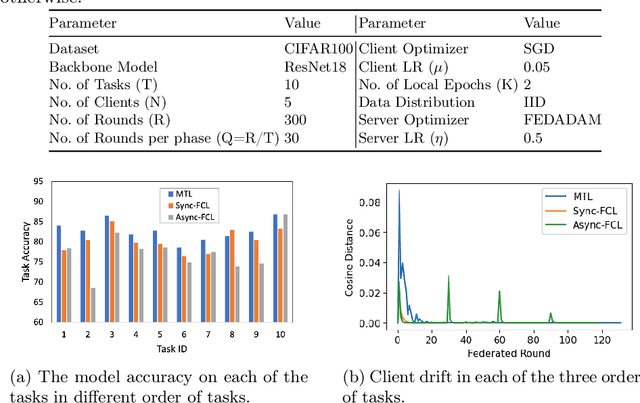
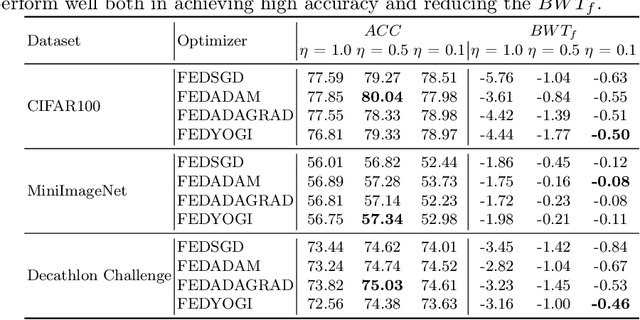
Federated learning has been extensively studied and is the prevalent method for privacy-preserving distributed learning in edge devices. Correspondingly, continual learning is an emerging field targeted towards learning multiple tasks sequentially. However, there is little attention towards additional challenges emerging when federated aggregation is performed in a continual learning system. We identify \textit{client drift} as one of the key weaknesses that arise when vanilla federated averaging is applied in such a system, especially since each client can independently have different order of tasks. We outline a framework for performing Federated Continual Learning (FCL) by using NetTailor as a candidate continual learning approach and show the extent of the problem of client drift. We show that adaptive federated optimization can reduce the adverse impact of client drift and showcase its effectiveness on CIFAR100, MiniImagenet, and Decathlon benchmarks. Further, we provide an empirical analysis highlighting the interplay between different hyperparameters such as client and server learning rates, the number of local training iterations, and communication rounds. Finally, we evaluate our framework on useful characteristics of federated learning systems such as scalability, robustness to the skewness in clients' data distribution, and stragglers.
Rate Coding or Direct Coding: Which One is Better for Accurate, Robust, and Energy-efficient Spiking Neural Networks?
Jan 31, 2022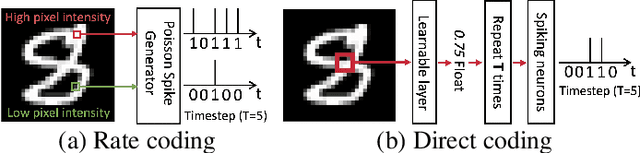

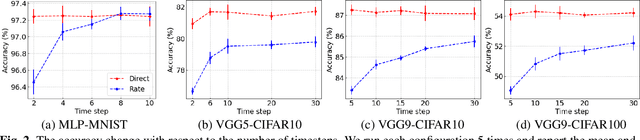
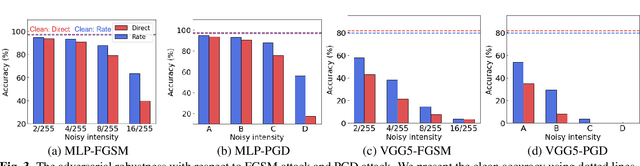
Recent Spiking Neural Networks (SNNs) works focus on an image classification task, therefore various coding techniques have been proposed to convert an image into temporal binary spikes. Among them, rate coding and direct coding are regarded as prospective candidates for building a practical SNN system as they show state-of-the-art performance on large-scale datasets. Despite their usage, there is little attention to comparing these two coding schemes in a fair manner. In this paper, we conduct a comprehensive analysis of the two codings from three perspectives: accuracy, adversarial robustness, and energy-efficiency. First, we compare the performance of two coding techniques with various architectures and datasets. Then, we measure the robustness of the coding techniques on two adversarial attack methods. Finally, we compare the energy-efficiency of two coding schemes on a digital hardware platform. Our results show that direct coding can achieve better accuracy especially for a small number of timesteps. In contrast, rate coding shows better robustness to adversarial attacks owing to the non-differentiable spike generation process. Rate coding also yields higher energy-efficiency than direct coding which requires multi-bit precision for the first layer. Our study explores the characteristics of two codings, which is an important design consideration for building SNNs. The code is made available at https://github.com/Intelligent-Computing-Lab-Yale/Rate-vs-Direct.
Neural Architecture Search for Spiking Neural Networks
Jan 23, 2022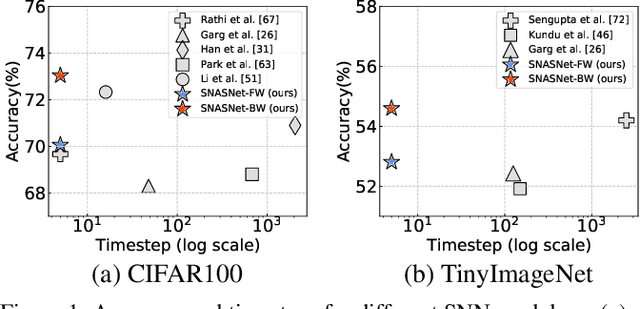
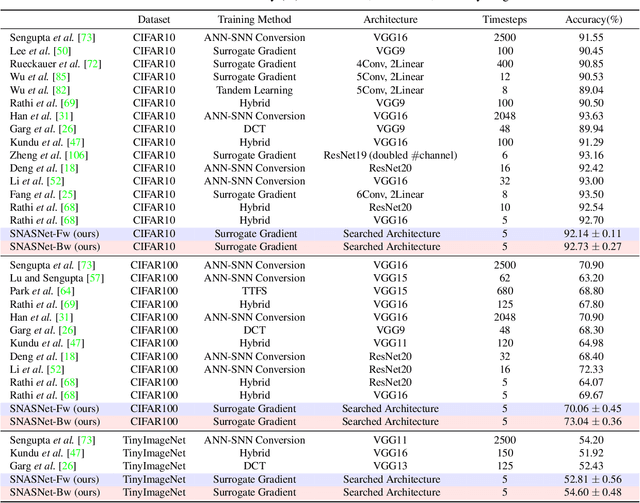
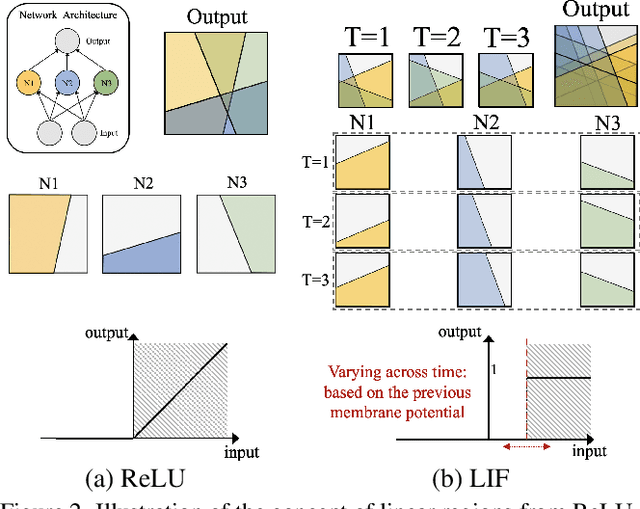
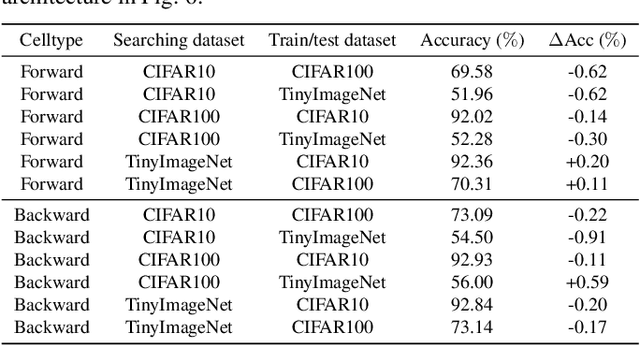
Spiking Neural Networks (SNNs) have gained huge attention as a potential energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their inherent high-sparsity activation. However, most prior SNN methods use ANN-like architectures (e.g., VGG-Net or ResNet), which could provide sub-optimal performance for temporal sequence processing of binary information in SNNs. To address this, in this paper, we introduce a novel Neural Architecture Search (NAS) approach for finding better SNN architectures. Inspired by recent NAS approaches that find the optimal architecture from activation patterns at initialization, we select the architecture that can represent diverse spike activation patterns across different data samples without training. Furthermore, to leverage the temporal correlation among the spikes, we search for feed forward connections as well as backward connections (i.e., temporal feedback connections) between layers. Interestingly, SNASNet found by our search algorithm achieves higher performance with backward connections, demonstrating the importance of designing SNN architecture for suitably using temporal information. We conduct extensive experiments on three image recognition benchmarks where we show that SNASNet achieves state-of-the-art performance with significantly lower timesteps (5 timesteps).