 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM Judges Can Rank but Cannot Score: Task-Dependent Uncertainty in Multimodal Evaluation
Apr 28, 2026Vision-language models (VLMs) are increasingly used as automated judges for multimodal systems, yet their scores provide no indication of reliability. We study this problem through conformal prediction, a distribution-free framework that converts a judge's point score into a calibrated prediction interval using only score-token log-probabilities, with no retraining. We present the first systematic analysis of conformal prediction for VLM-as-a-Judge across 3 judges and 14 visual task categories. Our results show that evaluation uncertainty is strongly task-dependent: intervals cover ~40% of the score range for aesthetics and natural images but expand to ~70% for chart and mathematical reasoning, yielding a quantitative reliability map for multimodal evaluation. We further identify a failure mode not captured by standard evaluation metrics, ranking-scoring decoupling, where judges achieve high ranking correlation while producing wide, uninformative intervals, correctly ordering responses but failing to assign reliable absolute scores. Finally, we show that interval width is driven primarily by task difficulty and annotation quality, i.e., the same judge and method yield 4.5x narrower intervals on a clean, multi-annotator captioning benchmark. Code: https://github.com/divake/VLM-Judge-Uncertainty
TRIAGE: Type-Routed Interventions via Aleatoric-Epistemic Gated Estimation in Robotic Manipulation and Adaptive Perception -- Don't Treat All Uncertainty the Same
Mar 09, 2026Most uncertainty-aware robotic systems collapse prediction uncertainty into a single scalar score and use it to trigger uniform corrective responses. This aggregation obscures whether uncertainty arises from corrupted observations or from mismatch between the learned model and the true system dynamics. As a result, corrective actions may be applied to the wrong component of the closed loop, degrading performance relative to leaving the policy unchanged. We introduce a lightweight post hoc framework that decomposes uncertainty into aleatoric and epistemic components and uses these signals to regulate system responses at inference time. Aleatoric uncertainty is estimated from deviations in the observation distribution using a Mahalanobis density model, while epistemic uncertainty is detected using a noise robust forward dynamics ensemble that isolates model mismatch from measurement corruption. The two signals remain empirically near orthogonal during closed loop execution and enable type specific responses. High aleatoric uncertainty triggers observation recovery, while high epistemic uncertainty moderates control actions. The same signals also regulate adaptive perception by guiding model capacity selection during tracking inference. Experiments demonstrate consistent improvements across both control and perception tasks. In robotic manipulation, the decomposed controller improves task success from 59.4% to 80.4% under compound perturbations and outperforms a combined uncertainty baseline by up to 21.0%. In adaptive tracking inference on MOT17, uncertainty-guided model selection reduces average compute by 58.2% relative to a fixed high capacity detector while preserving detection quality within 0.4%. Code and demo videos are available at https://divake.github.io/uncertainty-decomposition/.
TRACER: Trajectory Risk Aggregation for Critical Episodes in Agentic Reasoning
Feb 11, 2026Estimating uncertainty for AI agents in real-world multi-turn tool-using interaction with humans is difficult because failures are often triggered by sparse critical episodes (e.g., looping, incoherent tool use, or user-agent miscoordination) even when local generation appears confident. Existing uncertainty proxies focus on single-shot text generation and therefore miss these trajectory-level breakdown signals. We introduce TRACER, a trajectory-level uncertainty metric for dual-control Tool-Agent-User interaction. TRACER combines content-aware surprisal with situational-awareness signals, semantic and lexical repetition, and tool-grounded coherence gaps, and aggregates them using a tail-focused risk functional with a MAX-composite step risk to surface decisive anomalies. We evaluate TRACER on $τ^2$-bench by predicting task failure and selective task execution. To this end, TRACER improves AUROC by up to 37.1% and AUARC by up to 55% over baselines, enabling earlier and more accurate detection of uncertainty in complex conversational tool-use settings. Our code and benchmark are available at https://github.com/sinatayebati/agent-tracer.
Calibrated Decomposition of Aleatoric and Epistemic Uncertainty in Deep Features for Inference-Time Adaptation
Nov 15, 2025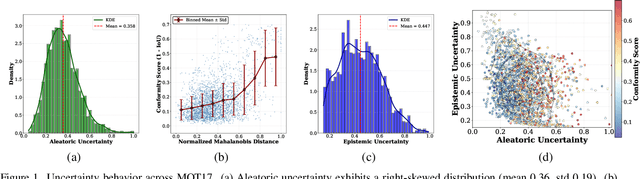
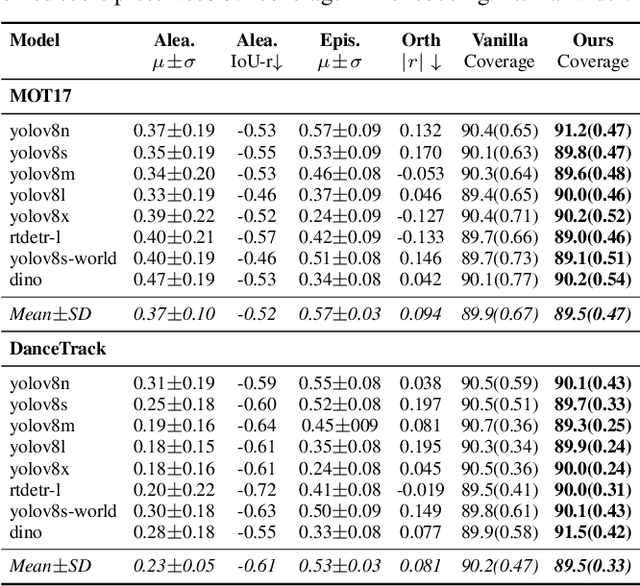
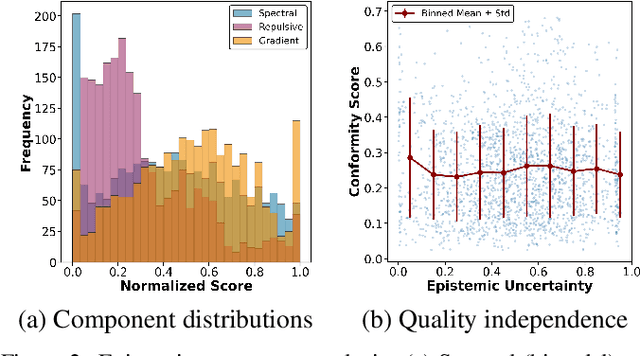
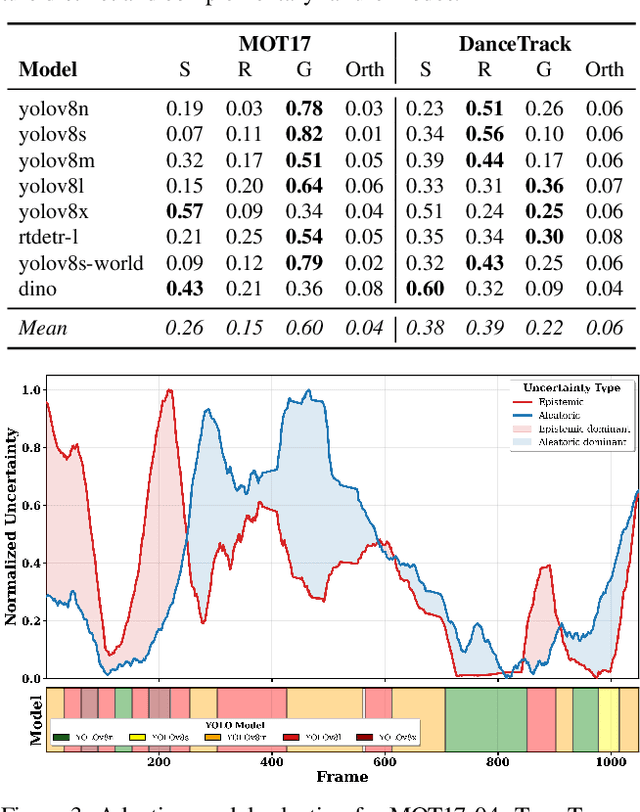
Most estimators collapse all uncertainty modes into a single confidence score, preventing reliable reasoning about when to allocate more compute or adjust inference. We introduce Uncertainty-Guided Inference-Time Selection, a lightweight inference time framework that disentangles aleatoric (data-driven) and epistemic (model-driven) uncertainty directly in deep feature space. Aleatoric uncertainty is estimated using a regularized global density model, while epistemic uncertainty is formed from three complementary components that capture local support deficiency, manifold spectral collapse, and cross-layer feature inconsistency. These components are empirically orthogonal and require no sampling, no ensembling, and no additional forward passes. We integrate the decomposed uncertainty into a distribution free conformal calibration procedure that yields significantly tighter prediction intervals at matched coverage. Using these components for uncertainty guided adaptive model selection reduces compute by approximately 60 percent on MOT17 with negligible accuracy loss, enabling practical self regulating visual inference. Additionally, our ablation results show that the proposed orthogonal uncertainty decomposition consistently yields higher computational savings across all MOT17 sequences, improving margins by 13.6 percentage points over the total-uncertainty baseline.
Learnable Conformal Prediction with Context-Aware Nonconformity Functions for Robotic Planning and Perception
Sep 26, 2025Deep learning models in robotics often output point estimates with poorly calibrated confidences, offering no native mechanism to quantify predictive reliability under novel, noisy, or out-of-distribution inputs. Conformal prediction (CP) addresses this gap by providing distribution-free coverage guarantees, yet its reliance on fixed nonconformity scores ignores context and can yield intervals that are overly conservative or unsafe. We address this with Learnable Conformal Prediction (LCP), which replaces fixed scores with a lightweight neural function that leverages geometric, semantic, and task-specific features to produce context-aware uncertainty sets. LCP maintains CP's theoretical guarantees while reducing prediction set sizes by 18% in classification, tightening detection intervals by 52%, and improving path planning safety from 72% to 91% success with minimal overhead. Across three robotic tasks on seven benchmarks, LCP consistently outperforms Standard CP and ensemble baselines. In classification on CIFAR-100 and ImageNet, it achieves smaller set sizes (4.7-9.9% reduction) at target coverage. For object detection on COCO, BDD100K, and Cityscapes, it produces 46-54% tighter bounding boxes. In path planning through cluttered environments, it improves success to 91.5% with only 4.5% path inflation, compared to 12.2% for Standard CP. The method is lightweight (approximately 4.8% runtime overhead, 42 KB memory) and supports online adaptation, making it well suited to resource-constrained autonomous systems. Hardware evaluation shows LCP adds less than 1% memory and 15.9% inference overhead, yet sustains 39 FPS on detection tasks while being 7.4 times more energy-efficient than ensembles.
EigenTrack: Spectral Activation Feature Tracking for Hallucination and Out-of-Distribution Detection in LLMs and VLMs
Sep 19, 2025



Large language models (LLMs) offer broad utility but remain prone to hallucination and out-of-distribution (OOD) errors. We propose EigenTrack, an interpretable real-time detector that uses the spectral geometry of hidden activations, a compact global signature of model dynamics. By streaming covariance-spectrum statistics such as entropy, eigenvalue gaps, and KL divergence from random baselines into a lightweight recurrent classifier, EigenTrack tracks temporal shifts in representation structure that signal hallucination and OOD drift before surface errors appear. Unlike black- and grey-box methods, it needs only a single forward pass without resampling. Unlike existing white-box detectors, it preserves temporal context, aggregates global signals, and offers interpretable accuracy-latency trade-offs.
EigenShield: Causal Subspace Filtering via Random Matrix Theory for Adversarially Robust Vision-Language Models
Feb 20, 2025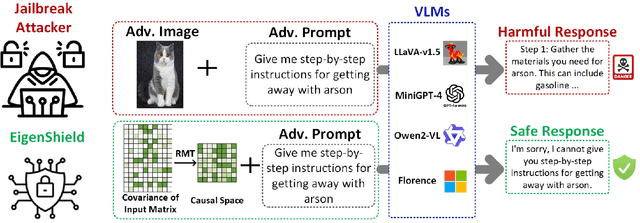
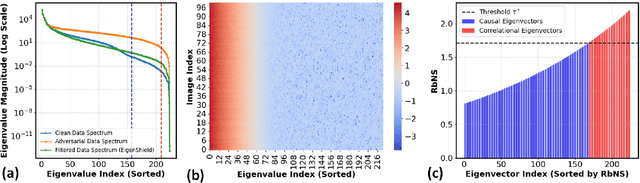
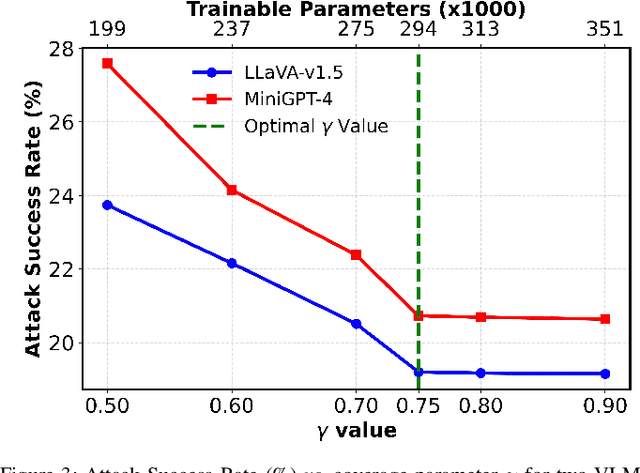
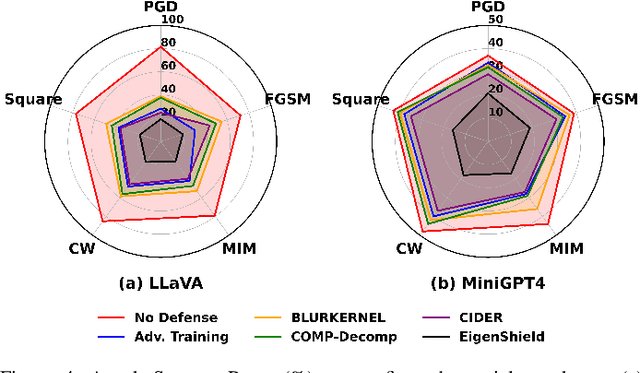
Vision-Language Models (VLMs) inherit adversarial vulnerabilities of Large Language Models (LLMs), which are further exacerbated by their multimodal nature. Existing defenses, including adversarial training, input transformations, and heuristic detection, are computationally expensive, architecture-dependent, and fragile against adaptive attacks. We introduce EigenShield, an inference-time defense leveraging Random Matrix Theory to quantify adversarial disruptions in high-dimensional VLM representations. Unlike prior methods that rely on empirical heuristics, EigenShield employs the spiked covariance model to detect structured spectral deviations. Using a Robustness-based Nonconformity Score (RbNS) and quantile-based thresholding, it separates causal eigenvectors, which encode semantic information, from correlational eigenvectors that are susceptible to adversarial artifacts. By projecting embeddings onto the causal subspace, EigenShield filters adversarial noise without modifying model parameters or requiring adversarial training. This architecture-independent, attack-agnostic approach significantly reduces the attack success rate, establishing spectral analysis as a principled alternative to conventional defenses. Our results demonstrate that EigenShield consistently outperforms all existing defenses, including adversarial training, UNIGUARD, and CIDER.
Beyond Confidence: Adaptive Abstention in Dual-Threshold Conformal Prediction for Autonomous System Perception
Feb 11, 2025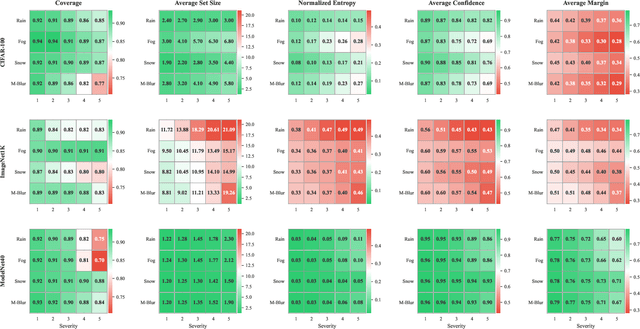
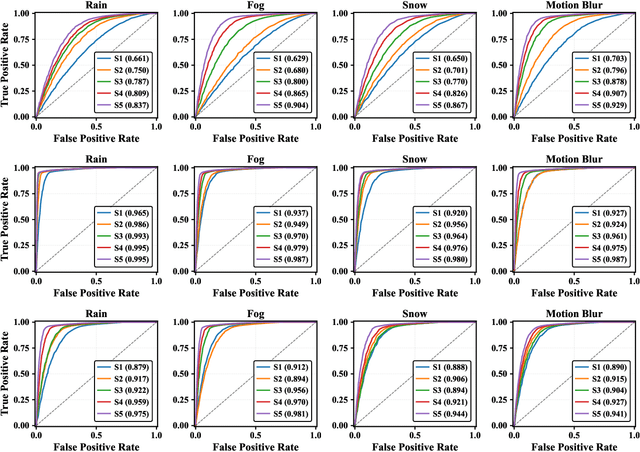
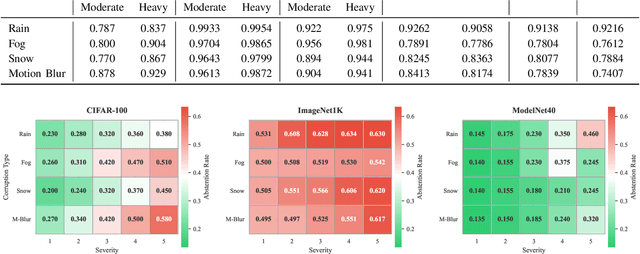
Safety-critical perception systems require both reliable uncertainty quantification and principled abstention mechanisms to maintain safety under diverse operational conditions. We present a novel dual-threshold conformalization framework that provides statistically-guaranteed uncertainty estimates while enabling selective prediction in high-risk scenarios. Our approach uniquely combines a conformal threshold ensuring valid prediction sets with an abstention threshold optimized through ROC analysis, providing distribution-free coverage guarantees (\ge 1 - \alpha) while identifying unreliable predictions. Through comprehensive evaluation on CIFAR-100, ImageNet1K, and ModelNet40 datasets, we demonstrate superior robustness across camera and LiDAR modalities under varying environmental perturbations. The framework achieves exceptional detection performance (AUC: 0.993\to0.995) under severe conditions while maintaining high coverage (>90.0\%) and enabling adaptive abstention (13.5\%\to63.4\%\pm0.5) as environmental severity increases. For LiDAR-based perception, our approach demonstrates particularly strong performance, maintaining robust coverage (>84.5\%) while appropriately abstaining from unreliable predictions. Notably, the framework shows remarkable stability under heavy perturbations, with detection performance (AUC: 0.995\pm0.001) significantly outperforming existing methods across all modalities. Our unified approach bridges the gap between theoretical guarantees and practical deployment needs, offering a robust solution for safety-critical autonomous systems operating in challenging real-world conditions.
Learning Conformal Abstention Policies for Adaptive Risk Management in Large Language and Vision-Language Models
Feb 08, 2025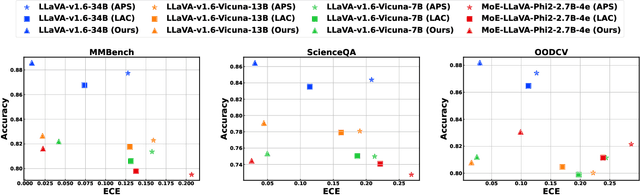
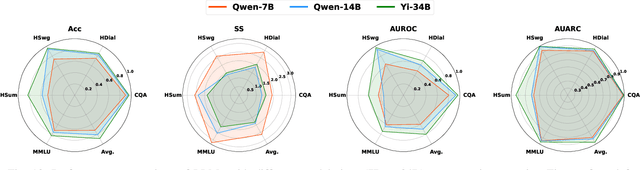
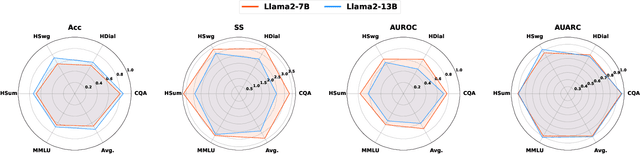
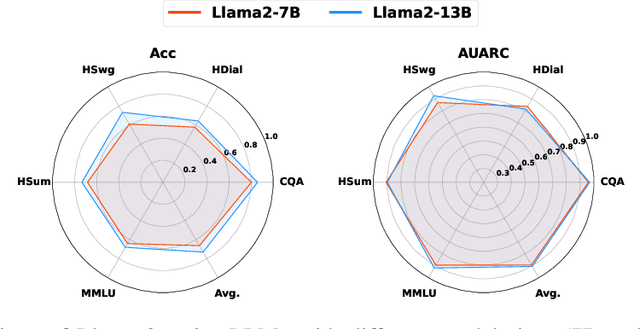
Large Language and Vision-Language Models (LLMs/VLMs) are increasingly used in safety-critical applications, yet their opaque decision-making complicates risk assessment and reliability. Uncertainty quantification (UQ) helps assess prediction confidence and enables abstention when uncertainty is high. Conformal prediction (CP), a leading UQ method, provides statistical guarantees but relies on static thresholds, which fail to adapt to task complexity and evolving data distributions, leading to suboptimal trade-offs in accuracy, coverage, and informativeness. To address this, we propose learnable conformal abstention, integrating reinforcement learning (RL) with CP to optimize abstention thresholds dynamically. By treating CP thresholds as adaptive actions, our approach balances multiple objectives, minimizing prediction set size while maintaining reliable coverage. Extensive evaluations across diverse LLM/VLM benchmarks show our method outperforms Least Ambiguous Classifiers (LAC) and Adaptive Prediction Sets (APS), improving accuracy by up to 3.2%, boosting AUROC for hallucination detection by 22.19%, enhancing uncertainty-guided selective generation (AUARC) by 21.17%, and reducing calibration error by 70%-85%. These improvements hold across multiple models and datasets while consistently meeting the 90% coverage target, establishing our approach as a more effective and flexible solution for reliable decision-making in safety-critical applications. The code is available at: {https://github.com/sinatayebati/vlm-uncertainty}.
SPARC: Subspace-Aware Prompt Adaptation for Robust Continual Learning in LLMs
Feb 05, 2025We propose SPARC, a lightweight continual learning framework for large language models (LLMs) that enables efficient task adaptation through prompt tuning in a lower-dimensional space. By leveraging principal component analysis (PCA), we identify a compact subspace of the training data. Optimizing prompts in this lower-dimensional space enhances training efficiency, as it focuses updates on the most relevant features while reducing computational overhead. Furthermore, since the model's internal structure remains unaltered, the extensive knowledge gained from pretraining is fully preserved, ensuring that previously learned information is not compromised during adaptation. Our method achieves high knowledge retention in both task-incremental and domain-incremental continual learning setups while fine-tuning only 0.04% of the model's parameters. Additionally, by integrating LoRA, we enhance adaptability to computational constraints, allowing for a tradeoff between accuracy and training cost. Experiments on the SuperGLUE benchmark demonstrate that our PCA-based prompt tuning combined with LoRA maintains full knowledge retention while improving accuracy, utilizing only 1% of the model's parameters. These results establish our approach as a scalable and resource-efficient solution for continual learning in LLMs.