 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARNet: Sensor Trustworthiness and Anomaly Recognition via Approximated Likelihood Regret for Robust Edge Autonomy
Sep 20, 2023



Complex sensors such as LiDAR, RADAR, and event cameras have proliferated in autonomous robotics to enhance perception and understanding of the environment. Meanwhile, these sensors are also vulnerable to diverse failure mechanisms that can intricately interact with their operation environment. In parallel, the limited availability of training data on complex sensors also affects the reliability of their deep learning-based prediction flow, where their prediction models can fail to generalize to environments not adequately captured in the training set. To address these reliability concerns, this paper introduces STARNet, a Sensor Trustworthiness and Anomaly Recognition Network designed to detect untrustworthy sensor streams that may arise from sensor malfunctions and/or challenging environments. We specifically benchmark STARNet on LiDAR and camera data. STARNet employs the concept of approximated likelihood regret, a gradient-free framework tailored for low-complexity hardware, especially those with only fixed-point precision capabilities. Through extensive simulations, we demonstrate the efficacy of STARNet in detecting untrustworthy sensor streams in unimodal and multimodal settings. In particular, the network shows superior performance in addressing internal sensor failures, such as cross-sensor interference and crosstalk. In diverse test scenarios involving adverse weather and sensor malfunctions, we show that STARNet enhances prediction accuracy by approximately 10% by filtering out untrustworthy sensor streams. STARNet is publicly available at \url{https://github.com/sinatayebati/STARNet}.
Robust Monocular Localization of Drones by Adapting Domain Maps to Depth Prediction Inaccuracies
Oct 27, 2022

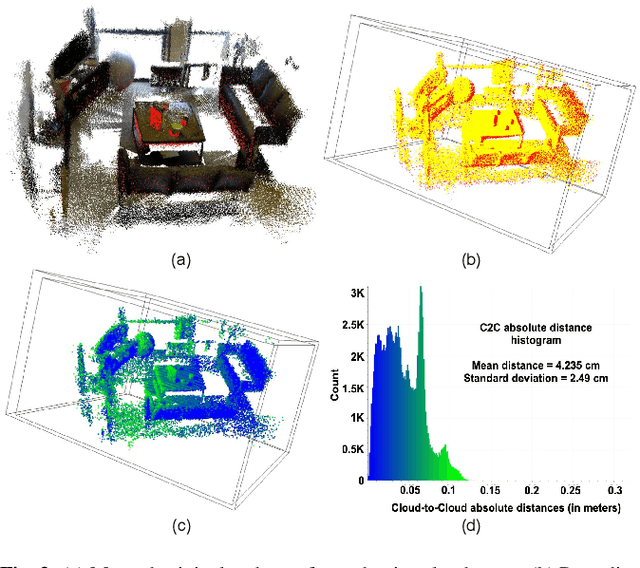
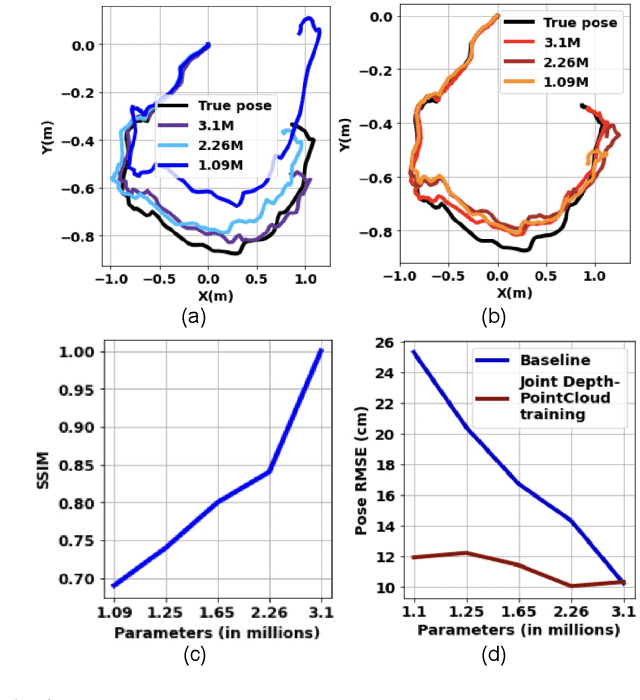
We present a novel monocular localization framework by jointly training deep learning-based depth prediction and Bayesian filtering-based pose reasoning. The proposed cross-modal framework significantly outperforms deep learning-only predictions with respect to model scalability and tolerance to environmental variations. Specifically, we show little-to-no degradation of pose accuracy even with extremely poor depth estimates from a lightweight depth predictor. Our framework also maintains high pose accuracy in extreme lighting variations compared to standard deep learning, even without explicit domain adaptation. By openly representing the map and intermediate feature maps (such as depth estimates), our framework also allows for faster updates and reusing intermediate predictions for other tasks, such as obstacle avoidance, resulting in much higher resource efficiency.