 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Unknown: Uncertainty-Aware Compute-in-Memory Autonomy of Edge Robotics
Jan 30, 2024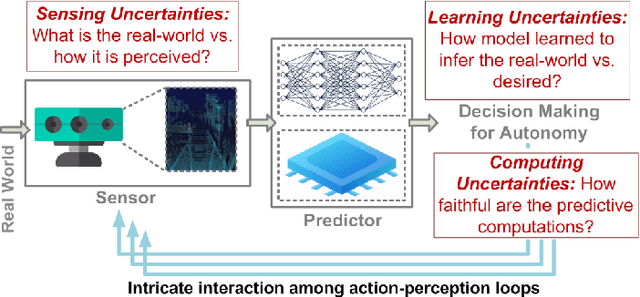
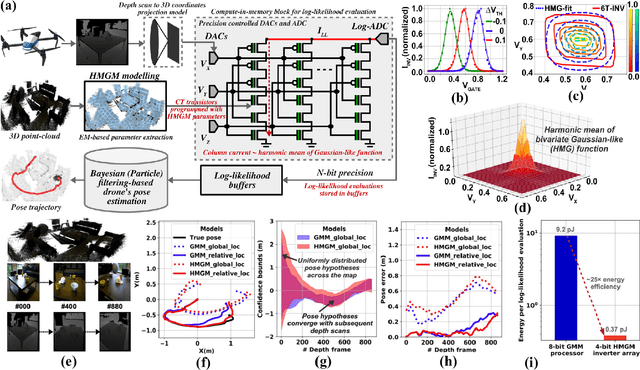
This paper addresses the challenging problem of energy-efficient and uncertainty-aware pose estimation in insect-scale drones, which is crucial for tasks such as surveillance in constricted spaces and for enabling non-intrusive spatial intelligence in smart homes. Since tiny drones operate in highly dynamic environments, where factors like lighting and human movement impact their predictive accuracy, it is crucial to deploy uncertainty-aware prediction algorithms that can account for environmental variations and express not only the prediction but also confidence in the prediction. We address both of these challenges with Compute-in-Memory (CIM) which has become a pivotal technology for deep learning acceleration at the edge. While traditional CIM techniques are promising for energy-efficient deep learning, to bring in the robustness of uncertainty-aware predictions at the edge, we introduce a suite of novel techniques: First, we discuss CIM-based acceleration of Bayesian filtering methods uniquely by leveraging the Gaussian-like switching current of CMOS inverters along with co-design of kernel functions to operate with extreme parallelism and with extreme energy efficiency. Secondly, we discuss the CIM-based acceleration of variational inference of deep learning models through probabilistic processing while unfolding iterative computations of the method with a compute reuse strategy to significantly minimize the workload. Overall, our co-design methodologies demonstrate the potential of CIM to improve the processing efficiency of uncertainty-aware algorithms by orders of magnitude, thereby enabling edge robotics to access the robustness of sophisticated prediction frameworks within their extremely stringent area/power resources.
Conformalized Multimodal Uncertainty Regression and Reasoning
Sep 20, 2023



This paper introduces a lightweight uncertainty estimator capable of predicting multimodal (disjoint) uncertainty bounds by integrating conformal prediction with a deep-learning regressor. We specifically discuss its application for visual odometry (VO), where environmental features such as flying domain symmetries and sensor measurements under ambiguities and occlusion can result in multimodal uncertainties. Our simulation results show that uncertainty estimates in our framework adapt sample-wise against challenging operating conditions such as pronounced noise, limited training data, and limited parametric size of the prediction model. We also develop a reasoning framework that leverages these robust uncertainty estimates and incorporates optical flow-based reasoning to improve prediction prediction accuracy. Thus, by appropriately accounting for predictive uncertainties of data-driven learning and closing their estimation loop via rule-based reasoning, our methodology consistently surpasses conventional deep learning approaches on all these challenging scenarios--pronounced noise, limited training data, and limited model size-reducing the prediction error by 2-3x.
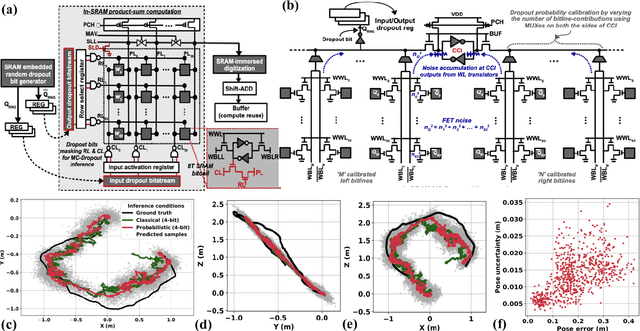
Mutual Information-calibrated Conformal Feature Fusion for Uncertainty-Aware Multimodal 3D Object Detection at the Edge
Sep 18, 2023



In the expanding landscape of AI-enabled robotics, robust quantification of predictive uncertainties is of great importance. Three-dimensional (3D) object detection, a critical robotics operation, has seen significant advancements; however, the majority of current works focus only on accuracy and ignore uncertainty quantification. Addressing this gap, our novel study integrates the principles of conformal inference (CI) with information theoretic measures to perform lightweight, Monte Carlo-free uncertainty estimation within a multimodal framework. Through a multivariate Gaussian product of the latent variables in a Variational Autoencoder (VAE), features from RGB camera and LiDAR sensor data are fused to improve the prediction accuracy. Normalized mutual information (NMI) is leveraged as a modulator for calibrating uncertainty bounds derived from CI based on a weighted loss function. Our simulation results show an inverse correlation between inherent predictive uncertainty and NMI throughout the model's training. The framework demonstrates comparable or better performance in KITTI 3D object detection benchmarks to similar methods that are not uncertainty-aware, making it suitable for real-time edge robotics.
Lightweight, Uncertainty-Aware Conformalized Visual Odometry
Mar 03, 2023Data-driven visual odometry (VO) is a critical subroutine for autonomous edge robotics, and recent progress in the field has produced highly accurate point predictions in complex environments. However, emerging autonomous edge robotics devices like insect-scale drones and surgical robots lack a computationally efficient framework to estimate VO's predictive uncertainties. Meanwhile, as edge robotics continue to proliferate into mission-critical application spaces, awareness of model's the predictive uncertainties has become crucial for risk-aware decision-making. This paper addresses this challenge by presenting a novel, lightweight, and statistically robust framework that leverages conformal inference (CI) to extract VO's uncertainty bands. Our approach represents the uncertainties using flexible, adaptable, and adjustable prediction intervals that, on average, guarantee the inclusion of the ground truth across all degrees of freedom (DOF) of pose estimation. We discuss the architectures of generative deep neural networks for estimating multivariate uncertainty bands along with point (mean) prediction. We also present techniques to improve the uncertainty estimation accuracy, such as leveraging Monte Carlo dropout (MC-dropout) for data augmentation. Finally, we propose a novel training loss function that combines interval scoring and calibration loss with traditional training metrics--mean-squared error and KL-divergence--to improve uncertainty-aware learning. Our simulation results demonstrate that the presented framework consistently captures true uncertainty in pose estimations across different datasets, estimation models, and applied noise types, indicating its wide applicability.
Robust Monocular Localization of Drones by Adapting Domain Maps to Depth Prediction Inaccuracies
Oct 27, 2022

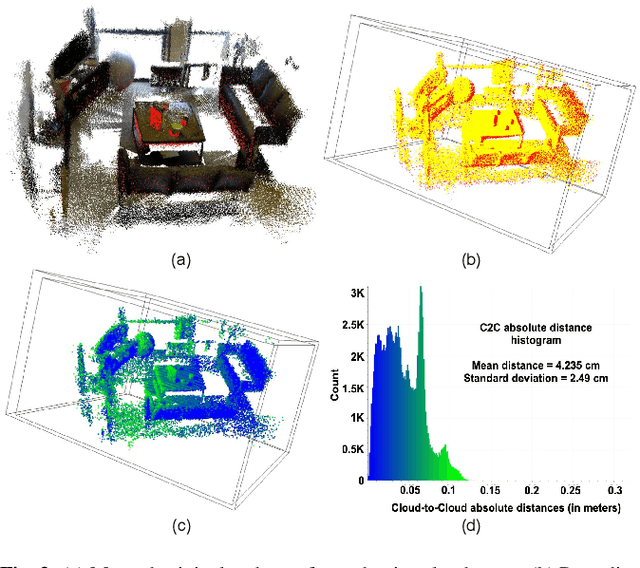
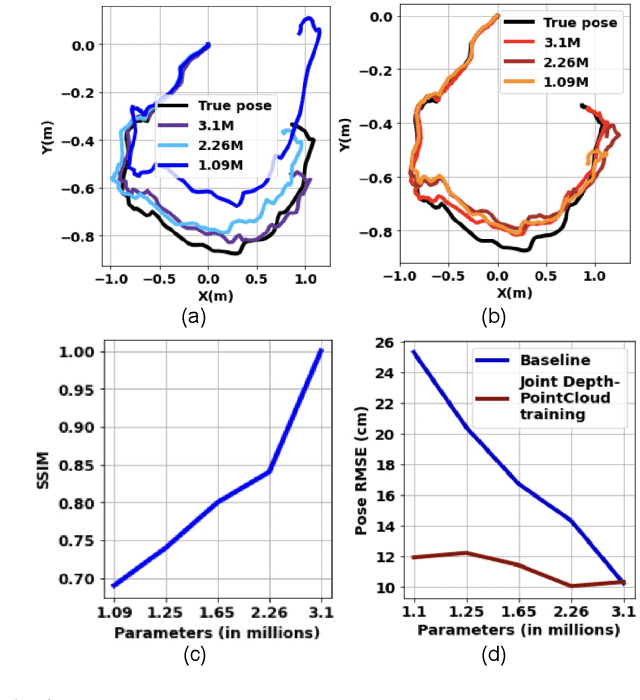
We present a novel monocular localization framework by jointly training deep learning-based depth prediction and Bayesian filtering-based pose reasoning. The proposed cross-modal framework significantly outperforms deep learning-only predictions with respect to model scalability and tolerance to environmental variations. Specifically, we show little-to-no degradation of pose accuracy even with extremely poor depth estimates from a lightweight depth predictor. Our framework also maintains high pose accuracy in extreme lighting variations compared to standard deep learning, even without explicit domain adaptation. By openly representing the map and intermediate feature maps (such as depth estimates), our framework also allows for faster updates and reusing intermediate predictions for other tasks, such as obstacle avoidance, resulting in much higher resource efficiency.