 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Guided Inference-Time Depth Adaptation for Transformer-Based Visual Tracking
Feb 18, 2026Transformer-based single-object trackers achieve state-of-the-art accuracy but rely on fixed-depth inference, executing the full encoder--decoder stack for every frame regardless of visual complexity, thereby incurring unnecessary computational cost in long video sequences dominated by temporally coherent frames. We propose UncL-STARK, an architecture-preserving approach that enables dynamic, uncertainty-aware depth adaptation in transformer-based trackers without modifying the underlying network or adding auxiliary heads. The model is fine-tuned to retain predictive robustness at multiple intermediate depths using random-depth training with knowledge distillation, thus enabling safe inference-time truncation. At runtime, we derive a lightweight uncertainty estimate directly from the model's corner localization heatmaps and use it in a feedback-driven policy that selects the encoder and decoder depth for the next frame based on the prediction confidence by exploiting temporal coherence in video. Extensive experiments on GOT-10k and LaSOT demonstrate up to 12\% GFLOPs reduction, 8.9\% latency reduction, and 10.8\% energy savings while maintaining tracking accuracy within 0.2\% of the full-depth baseline across both short-term and long-term sequences.
MEMETRON: Metaheuristic Mechanisms for Test-time Response Optimization of Large Language Models
Jun 10, 2025Large language models (LLMs) are increasingly used for both open-ended and structured tasks, yet their inference-time behavior is still largely dictated by heuristic decoding strategies such as greedy search, sampling, or reranking. These methods provide limited control and do not explicitly optimize for task-specific objectives. We introduce MEMETRON, a task-agnostic framework that formulates LLM decoding as a discrete black-box optimization problem. MEMETRON leverages hybrid metaheuristic algorithms, GENETRON and ANNETRON, to search the response space, guided by reward models and contextual operations performed by the LLM itself. This approach enables efficient discovery of high-reward responses without requiring model retraining or gradient access. The framework is modular and generalizes across diverse tasks, requiring only a reward function and lightweight prompt templates. We evaluate our framework on the critical human preference alignment task and demonstrate that it significantly outperforms standard decoding and reranking methods, highlighting its potential to improve alignment without model retraining.
Prediction of Lung Metastasis from Hepatocellular Carcinoma using the SEER Database
Jan 20, 2025Hepatocellular carcinoma (HCC) is a leading cause of cancer-related mortality, with lung metastases being the most common site of distant spread and significantly worsening prognosis. Despite the growing availability of clinical and demographic data, predictive models for lung metastasis in HCC remain limited in scope and clinical applicability. In this study, we develop and validate an end-to-end machine learning pipeline using data from the Surveillance, Epidemiology, and End Results (SEER) database. We evaluated three machine learning models (Random Forest, XGBoost, and Logistic Regression) alongside a multilayer perceptron (MLP) neural network. Our models achieved high AUROC values and recall, with the Random Forest and MLP models demonstrating the best overall performance (AUROC = 0.82). However, the low precision across models highlights the challenges of accurately predicting positive cases. To address these limitations, we developed a custom loss function incorporating recall optimization, enabling the MLP model to achieve the highest sensitivity. An ensemble approach further improved overall recall by leveraging the strengths of individual models. Feature importance analysis revealed key predictors such as surgery status, tumor staging, and follow up duration, emphasizing the relevance of clinical interventions and disease progression in metastasis prediction. While this study demonstrates the potential of machine learning for identifying high-risk patients, limitations include reliance on imbalanced datasets, incomplete feature annotations, and the low precision of predictions. Future work should leverage the expanding SEER dataset, improve data imputation techniques, and explore advanced pre-trained models to enhance predictive accuracy and clinical utility.
Sense Less, Generate More: Pre-training LiDAR Perception with Masked Autoencoders for Ultra-Efficient 3D Sensing
Jun 12, 2024In this work, we propose a disruptively frugal LiDAR perception dataflow that generates rather than senses parts of the environment that are either predictable based on the extensive training of the environment or have limited consequence to the overall prediction accuracy. Therefore, the proposed methodology trades off sensing energy with training data for low-power robotics and autonomous navigation to operate frugally with sensors, extending their lifetime on a single battery charge. Our proposed generative pre-training strategy for this purpose, called as radially masked autoencoding (R-MAE), can also be readily implemented in a typical LiDAR system by selectively activating and controlling the laser power for randomly generated angular regions during on-field operations. Our extensive evaluations show that pre-training with R-MAE enables focusing on the radial segments of the data, thereby capturing spatial relationships and distances between objects more effectively than conventional procedures. Therefore, the proposed methodology not only reduces sensing energy but also improves prediction accuracy. For example, our extensive evaluations on Waymo, nuScenes, and KITTI datasets show that the approach achieves over a 5% average precision improvement in detection tasks across datasets and over a 4% accuracy improvement in transferring domains from Waymo and nuScenes to KITTI. In 3D object detection, it enhances small object detection by up to 4.37% in AP at moderate difficulty levels in the KITTI dataset. Even with 90% radial masking, it surpasses baseline models by up to 5.59% in mAP/mAPH across all object classes in the Waymo dataset. Additionally, our method achieves up to 3.17% and 2.31% improvements in mAP and NDS, respectively, on the nuScenes dataset, demonstrating its effectiveness with both single and fused LiDAR-camera modalities. https://github.com/sinatayebati/Radial_MAE.
CURATRON: Complete Robust Preference Data for Robust Alignment of Large Language Models
Mar 05, 2024


This paper addresses the challenges of aligning large language models (LLMs) with human values via preference learning (PL), with a focus on the issues of incomplete and corrupted data in preference datasets. We propose a novel method for robustly and completely recalibrating values within these datasets to enhance LLMs resilience against the issues. In particular, we devise a guaranteed polynomial time ranking algorithm that robustifies several existing models, such as the classic Bradley--Terry--Luce (BTL) (Bradley and Terry, 1952) model and certain generalizations of it. To the best of our knowledge, our present work is the first to propose an algorithm that provably recovers an {\epsilon}-optimal ranking with high probability while allowing as large as O(n) perturbed pairwise comparison results per model response. Furthermore, we show robust recovery results in the partially observed setting. Our experiments confirm that our algorithms handle adversarial noise and unobserved comparisons well in both general and LLM preference dataset settings. This work contributes to the development and scaling of more reliable and ethically aligned AI models by equipping the dataset curation pipeline with the ability to handle missing and maliciously manipulated inputs.
InteraRec: Interactive Recommendations Using Multimodal Large Language Models
Feb 26, 2024



Weblogs, comprised of records detailing user activities on any website, offer valuable insights into user preferences, behavior, and interests. Numerous recommendation algorithms, employing strategies such as collaborative filtering, content-based filtering, and hybrid methods, leverage the data mined through these weblogs to provide personalized recommendations to users. Despite the abundance of information available in these weblogs, identifying and extracting pertinent information and key features necessitates extensive engineering endeavors. The intricate nature of the data also poses a challenge for interpretation, especially for non-experts. In this study, we introduce a sophisticated and interactive recommendation framework denoted as InteraRec, which diverges from conventional approaches that exclusively depend on weblogs for recommendation generation. This framework captures high-frequency screenshots of web pages as users navigate through a website. Leveraging state-of-the-art multimodal large language models (MLLMs), it extracts valuable insights into user preferences from these screenshots by generating a user behavioral summary based on predefined keywords. Subsequently, this summary is utilized as input to an LLM-integrated optimization setup to generate tailored recommendations. Through our experiments, we demonstrate the effectiveness of InteraRec in providing users with valuable and personalized offerings.
Echoes of Socratic Doubt: Embracing Uncertainty in Calibrated Evidential Reinforcement Learning
Feb 13, 2024We present a novel statistical approach to incorporating uncertainty awareness in model-free distributional reinforcement learning involving quantile regression-based deep Q networks. The proposed algorithm, $\textit{Calibrated Evidential Quantile Regression in Deep Q Networks (CEQR-DQN)}$, aims to address key challenges associated with separately estimating aleatoric and epistemic uncertainty in stochastic environments. It combines deep evidential learning with quantile calibration based on principles of conformal inference to provide explicit, sample-free computations of $\textit{global}$ uncertainty as opposed to $\textit{local}$ estimates based on simple variance, overcoming limitations of traditional methods in computational and statistical efficiency and handling of out-of-distribution (OOD) observations. Tested on a suite of miniaturized Atari games (i.e., MinAtar), CEQR-DQN is shown to surpass similar existing frameworks in scores and learning speed. Its ability to rigorously evaluate uncertainty improves exploration strategies and can serve as a blueprint for other algorithms requiring uncertainty awareness.
User Friendly and Adaptable Discriminative AI: Using the Lessons from the Success of LLMs and Image Generation Models
Dec 11, 2023
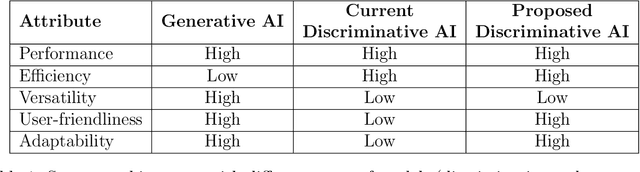


While there is significant interest in using generative AI tools as general-purpose models for specific ML applications, discriminative models are much more widely deployed currently. One of the key shortcomings of these discriminative AI tools that have been already deployed is that they are not adaptable and user-friendly compared to generative AI tools (e.g., GPT4, Stable Diffusion, Bard, etc.), where a non-expert user can iteratively refine model inputs and give real-time feedback that can be accounted for immediately, allowing users to build trust from the start. Inspired by this emerging collaborative workflow, we develop a new system architecture that enables users to work with discriminative models (such as for object detection, sentiment classification, etc.) in a fashion similar to generative AI tools, where they can easily provide immediate feedback as well as adapt the deployed models as desired. Our approach has implications on improving trust, user-friendliness, and adaptability of these versatile but traditional prediction models.
InteraSSort: Interactive Assortment Planning Using Large Language Models
Nov 20, 2023


Assortment planning, integral to multiple commercial offerings, is a key problem studied in e-commerce and retail settings. Numerous variants of the problem along with their integration into business solutions have been thoroughly investigated in the existing literature. However, the nuanced complexities of in-store planning and a lack of optimization proficiency among store planners with strong domain expertise remain largely overlooked. These challenges frequently necessitate collaborative efforts with multiple stakeholders which often lead to prolonged decision-making processes and significant delays. To mitigate these challenges and capitalize on the advancements of Large Language Models (LLMs), we propose an interactive assortment planning framework, InteraSSort that augments LLMs with optimization tools to assist store planners in making decisions through interactive conversations. Specifically, we develop a solution featuring a user-friendly interface that enables users to express their optimization objectives as input text prompts to InteraSSort and receive tailored optimized solutions as output. Our framework extends beyond basic functionality by enabling the inclusion of additional constraints through interactive conversation, facilitating precise and highly customized decision-making. Extensive experiments demonstrate the effectiveness of our framework and potential extensions to a broad range of operations management challenges.
Dynamic Tiling: A Model-Agnostic, Adaptive, Scalable, and Inference-Data-Centric Approach for Efficient and Accurate Small Object Detection
Sep 20, 2023We introduce Dynamic Tiling, a model-agnostic, adaptive, and scalable approach for small object detection, anchored in our inference-data-centric philosophy. Dynamic Tiling starts with non-overlapping tiles for initial detections and utilizes dynamic overlapping rates along with a tile minimizer. This dual approach effectively resolves fragmented objects, improves detection accuracy, and minimizes computational overhead by reducing the number of forward passes through the object detection model. Adaptable to a variety of operational environments, our method negates the need for laborious recalibration. Additionally, our large-small filtering mechanism boosts the detection quality across a range of object sizes. Overall, Dynamic Tiling outperforms existing model-agnostic uniform cropping methods, setting new benchmarks for efficiency and accuracy.