 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMETRON: Metaheuristic Mechanisms for Test-time Response Optimization of Large Language Models
Jun 10, 2025Large language models (LLMs) are increasingly used for both open-ended and structured tasks, yet their inference-time behavior is still largely dictated by heuristic decoding strategies such as greedy search, sampling, or reranking. These methods provide limited control and do not explicitly optimize for task-specific objectives. We introduce MEMETRON, a task-agnostic framework that formulates LLM decoding as a discrete black-box optimization problem. MEMETRON leverages hybrid metaheuristic algorithms, GENETRON and ANNETRON, to search the response space, guided by reward models and contextual operations performed by the LLM itself. This approach enables efficient discovery of high-reward responses without requiring model retraining or gradient access. The framework is modular and generalizes across diverse tasks, requiring only a reward function and lightweight prompt templates. We evaluate our framework on the critical human preference alignment task and demonstrate that it significantly outperforms standard decoding and reranking methods, highlighting its potential to improve alignment without model retraining.
CURATRON: Complete Robust Preference Data for Robust Alignment of Large Language Models
Mar 05, 2024


This paper addresses the challenges of aligning large language models (LLMs) with human values via preference learning (PL), with a focus on the issues of incomplete and corrupted data in preference datasets. We propose a novel method for robustly and completely recalibrating values within these datasets to enhance LLMs resilience against the issues. In particular, we devise a guaranteed polynomial time ranking algorithm that robustifies several existing models, such as the classic Bradley--Terry--Luce (BTL) (Bradley and Terry, 1952) model and certain generalizations of it. To the best of our knowledge, our present work is the first to propose an algorithm that provably recovers an {\epsilon}-optimal ranking with high probability while allowing as large as O(n) perturbed pairwise comparison results per model response. Furthermore, we show robust recovery results in the partially observed setting. Our experiments confirm that our algorithms handle adversarial noise and unobserved comparisons well in both general and LLM preference dataset settings. This work contributes to the development and scaling of more reliable and ethically aligned AI models by equipping the dataset curation pipeline with the ability to handle missing and maliciously manipulated inputs.
User Friendly and Adaptable Discriminative AI: Using the Lessons from the Success of LLMs and Image Generation Models
Dec 11, 2023
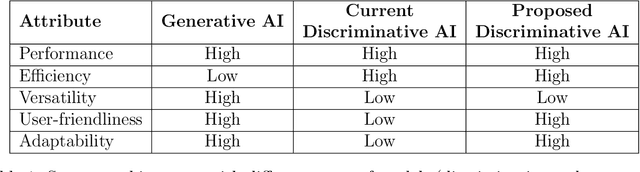


While there is significant interest in using generative AI tools as general-purpose models for specific ML applications, discriminative models are much more widely deployed currently. One of the key shortcomings of these discriminative AI tools that have been already deployed is that they are not adaptable and user-friendly compared to generative AI tools (e.g., GPT4, Stable Diffusion, Bard, etc.), where a non-expert user can iteratively refine model inputs and give real-time feedback that can be accounted for immediately, allowing users to build trust from the start. Inspired by this emerging collaborative workflow, we develop a new system architecture that enables users to work with discriminative models (such as for object detection, sentiment classification, etc.) in a fashion similar to generative AI tools, where they can easily provide immediate feedback as well as adapt the deployed models as desired. Our approach has implications on improving trust, user-friendliness, and adaptability of these versatile but traditional prediction models.
Dynamic Tiling: A Model-Agnostic, Adaptive, Scalable, and Inference-Data-Centric Approach for Efficient and Accurate Small Object Detection
Sep 20, 2023We introduce Dynamic Tiling, a model-agnostic, adaptive, and scalable approach for small object detection, anchored in our inference-data-centric philosophy. Dynamic Tiling starts with non-overlapping tiles for initial detections and utilizes dynamic overlapping rates along with a tile minimizer. This dual approach effectively resolves fragmented objects, improves detection accuracy, and minimizes computational overhead by reducing the number of forward passes through the object detection model. Adaptable to a variety of operational environments, our method negates the need for laborious recalibration. Additionally, our large-small filtering mechanism boosts the detection quality across a range of object sizes. Overall, Dynamic Tiling outperforms existing model-agnostic uniform cropping methods, setting new benchmarks for efficiency and accuracy.
Generative AI for Business Strategy: Using Foundation Models to Create Business Strategy Tools
Aug 27, 2023Generative models (foundation models) such as LLMs (large language models) are having a large impact on multiple fields. In this work, we propose the use of such models for business decision making. In particular, we combine unstructured textual data sources (e.g., news data) with multiple foundation models (namely, GPT4, transformer-based Named Entity Recognition (NER) models and Entailment-based Zero-shot Classifiers (ZSC)) to derive IT (information technology) artifacts in the form of a (sequence of) signed business networks. We posit that such artifacts can inform business stakeholders about the state of the market and their own positioning as well as provide quantitative insights into improving their future outlook.