 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVSD: Adaptive-View Self-Distillation by Balancing Consensus and Teacher-Specific Privileged Signals
May 20, 2026Self-distillation enables language models to learn on-policy from their own trajectories by using the same model as both student and teacher, with the teacher being conditioned on privileged information unavailable to the student. Such information can come in different types or views, such as solutions, demonstrations, feedback, or final answers. This setup provides dense token-level feedback without relying on a separate external model, but creates a fundamental asymmetry: the teacher may rely on view-specific information that the student cannot access at inference time. Moreover, the best type of privileged information is often task-dependent, making it difficult to choose a single teacher view. In this work, we address both these challenges jointly by introducing AVSD (Adaptive-View Self-Distillation), a novel method of self-distillation with multiple privileged-information views, which reconstructs token-level supervision by separating stable cross-view consensus from view-specific residual signals. AVSD identifies the consensus signal shared across views, which provides a reliable update direction, and then selectively adds the view-specific residual signal to adjust the update magnitude when it both aligns with the consensus direction and remains proportionate to the consensus signal. Experiments on math competition benchmarks (AIME24, AIME25, and HMMT25) show that AVSD consistently outperforms both single-view self-distillation baselines and GRPO, achieving average Avg@8 gains of 3.1% and 2.2% over the strongest baselines on Qwen3-8B and Qwen3-4B, respectively. Moreover, on code-generation benchmarks (Codeforces, LiveCodeBench v6) using Qwen3-8B, AVSD outperforms the single-view self-distillation baseline by 2.4% on average.
CodeGraphVLP: Code-as-Planner Meets Semantic-Graph State for Non-Markovian Vision-Language-Action Models
Apr 24, 2026Vision-Language-Action (VLA) models promise generalist robot manipulation, but are typically trained and deployed as short-horizon policies that assume the latest observation is sufficient for action reasoning. This assumption breaks in non-Markovian long-horizon tasks, where task-relevant evidence can be occluded or appear only earlier in the trajectory, and where clutter and distractors make fine-grained visual grounding brittle. We present CodeGraphVLP, a hierarchical framework that enables reliable long-horizon manipulation by combining a persistent semantic-graph state with an executable code-based planner and progress-guided visual-language prompting. The semantic-graph maintains task-relevant entities and relations under partial observability. The synthesized planner executes over this semantic-graph to perform efficient progress checks and outputs a subtask instruction together with subtask-relevant objects. We use these outputs to construct clutter-suppressed observations that focus the VLA executor on critical evidence. On real-world non-Markovian tasks, CodeGraphVLP improves task completion over strong VLA baselines and history-enabled variants while substantially lowering planning latency compared to VLM-in-the-loop planning. We also conduct extensive ablation studies to confirm the contributions of each component.
Self-Supervised Learning via Flow-Guided Neural Operator on Time-Series Data
Feb 12, 2026Self-supervised learning (SSL) is a powerful paradigm for learning from unlabeled time-series data. However, popular methods such as masked autoencoders (MAEs) rely on reconstructing inputs from a fixed, predetermined masking ratio. Instead of this static design, we propose treating the corruption level as a new degree of freedom for representation learning, enhancing flexibility and performance. To achieve this, we introduce the Flow-Guided Neural Operator (FGNO), a novel framework combining operator learning with flow matching for SSL training. FGNO learns mappings in functional spaces by using Short-Time Fourier Transform to unify different time resolutions. We extract a rich hierarchy of features by tapping into different network layers and flow times that apply varying strengths of noise to the input data. This enables the extraction of versatile representations, from low-level patterns to high-level global features, using a single model adaptable to specific tasks. Unlike prior generative SSL methods that use noisy inputs during inference, we propose using clean inputs for representation extraction while learning representations with noise; this eliminates randomness and boosts accuracy. We evaluate FGNO across three biomedical domains, where it consistently outperforms established baselines. Our method yields up to 35% AUROC gains in neural signal decoding (BrainTreeBank), 16% RMSE reductions in skin temperature prediction (DREAMT), and over 20% improvement in accuracy and macro-F1 on SleepEDF under low-data regimes. These results highlight FGNO's robustness to data scarcity and its superior capacity to learn expressive representations for diverse time series.
Conflict-Resolving and Sharpness-Aware Minimization for Generalized Knowledge Editing with Multiple Updates
Feb 03, 2026Large language models (LLMs) rely on internal knowledge to solve many downstream tasks, making it crucial to keep them up to date. Since full retraining is expensive, prior work has explored efficient alternatives such as model editing and parameter-efficient fine-tuning. However, these approaches often break down in practice due to poor generalization across inputs, limited stability, and knowledge conflict. To address these limitations, we propose the CoRSA (Conflict-Resolving and Sharpness-Aware Minimization) training framework, a parameter-efficient, holistic approach for knowledge editing with multiple updates. CoRSA tackles multiple challenges simultaneously: it improves generalization to different input forms and enhances stability across multiple updates by minimizing loss curvature, and resolves conflicts by maximizing the margin between new and prior knowledge. Across three widely used fact editing benchmarks, CoRSA achieves significant gains in generalization, outperforming baselines with average absolute improvements of 12.42% over LoRA and 10% over model editing methods. With multiple updates, it maintains high update efficacy while reducing catastrophic forgetting by 27.82% compared to LoRA. CoRSA also generalizes to the code domain, outperforming the strongest baseline by 5.48% Pass@5 in update efficacy.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
VirDA: Reusing Backbone for Unsupervised Domain Adaptation with Visual Reprogramming
Oct 02, 2025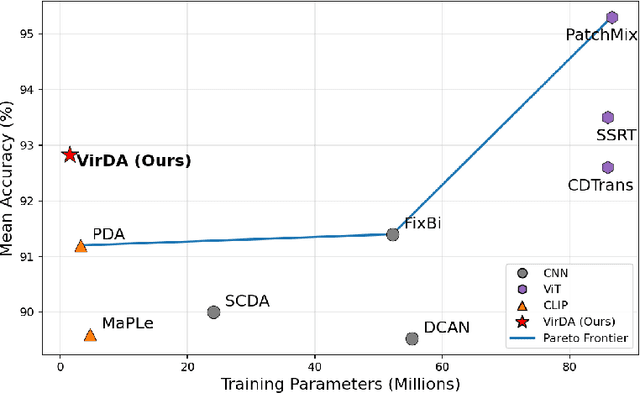
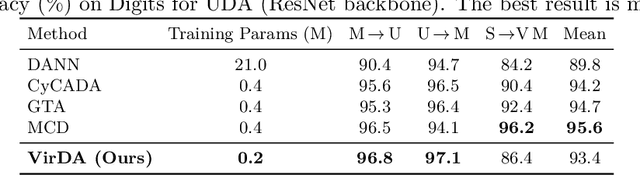
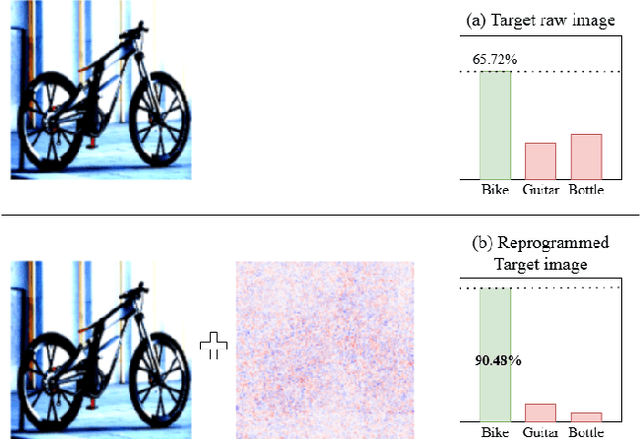
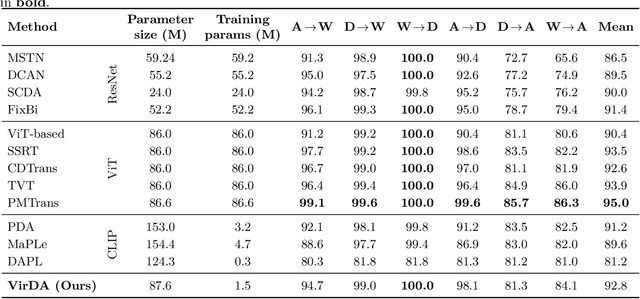
Existing UDA pipelines fine-tune already well-trained backbone parameters for every new source-and-target pair, resulting in the number of training parameters and storage memory growing linearly with each new pair, and also preventing the reuse of these well-trained backbone parameters. Inspired by recent implications that existing backbones have textural biases, we propose making use of domain-specific textural bias for domain adaptation via visual reprogramming, namely VirDA.Instead of fine-tuning the full backbone, VirDA prepends a domain-specific visual reprogramming layer to the backbone. This layer produces visual prompts that act as an added textural bias to the input image, adapting its ``style'' to a target domain. To optimize these visual reprogramming layers, we use multiple objective functions that optimize the intra- and inter-domain distribution differences when domain-adapting visual prompts are applied. This process does not require modifying the backbone parameters, allowing the same backbone to be reused across different domains. We evaluate VirDA on Office-31 and obtain 92.8% mean accuracy with only 1.5M trainable parameters. VirDA surpasses PDA, the state-of-the-art parameter-efficient UDA baseline, by +1.6% accuracy while using just 46% of its parameters. Compared with full-backbone fine-tuning, VirDA outperforms CDTrans and FixBi by +0.2% and +1.4%, respectively, while requiring only 1.7% and 2.8% of their trainable parameters. Relative to the strongest current methods (PMTrans and TVT), VirDA uses ~1.7% of their parameters and trades off only 2.2% and 1.1% accuracy, respectively.
GrAInS: Gradient-based Attribution for Inference-Time Steering of LLMs and VLMs
Jul 24, 2025Inference-time steering methods offer a lightweight alternative to fine-tuning large language models (LLMs) and vision-language models (VLMs) by modifying internal activations at test time without updating model weights. However, most existing approaches rely on fixed, global intervention vectors, overlook the causal influence of individual input tokens, and fail to leverage informative gradients from the model's logits, particularly in multimodal settings where visual and textual inputs contribute unevenly. To address these limitations, we introduce GrAInS, an inference-time steering approach that operates across both language-only and vision-language models and tasks. GrAInS uses contrastive, gradient-based attribution via Integrated Gradients to identify the top-k most influential tokens, both positively and negatively attributed based on their contribution to preferred versus dispreferred outputs. These tokens are then used to construct directional steering vectors that capture semantic shifts from undesirable to desirable behavior. During inference, GrAInS adjusts hidden activations at transformer layers guided by token-level attribution signals, and normalizes activations to preserve representational scale. This enables fine-grained, interpretable, and modular control over model behavior, without retraining or auxiliary supervision. Empirically, GrAInS consistently outperforms both fine-tuning and existing steering baselines: it achieves a 13.22% accuracy gain on TruthfulQA using Llama-3.1-8B, reduces hallucination rates on MMHal-Bench from 0.624 to 0.514 with LLaVA-1.6-7B, and improves alignment win rates on SPA-VL by 8.11%, all while preserving the model's fluency and general capabilities.
Multi-Attribute Steering of Language Models via Targeted Intervention
Feb 18, 2025Inference-time intervention (ITI) has emerged as a promising method for steering large language model (LLM) behavior in a particular direction (e.g., improving helpfulness) by intervening on token representations without costly updates to the LLM's parameters. However, existing ITI approaches fail to scale to multi-attribute settings with conflicts, such as enhancing helpfulness while also reducing toxicity. To address this, we introduce Multi-Attribute Targeted Steering (MAT-Steer), a novel steering framework designed for selective token-level intervention across multiple attributes. MAT-Steer learns steering vectors using an alignment objective that shifts the model's internal representations of undesirable outputs closer to those of desirable ones while enforcing sparsity and orthogonality among vectors for different attributes, thereby reducing inter-attribute conflicts. We evaluate MAT-Steer in two distinct settings: (i) on question answering (QA) tasks where we balance attributes like truthfulness, bias, and toxicity; (ii) on generative tasks where we simultaneously improve attributes like helpfulness, correctness, and coherence. MAT-Steer outperforms existing ITI and parameter-efficient finetuning approaches across both task types (e.g., 3% average accuracy gain across QA tasks and 55.82% win rate against the best ITI baseline).
Risk-Aware Distributional Intervention Policies for Language Models
Jan 27, 2025Language models are prone to occasionally undesirable generations, such as harmful or toxic content, despite their impressive capability to produce texts that appear accurate and coherent. This paper presents a new two-stage approach to detect and mitigate undesirable content generations by rectifying activations. First, we train an ensemble of layerwise classifiers to detect undesirable content using activations by minimizing a smooth surrogate of the risk-aware score. Then, for contents that are detected as undesirable, we propose layerwise distributional intervention policies that perturb the attention heads minimally while guaranteeing probabilistically the effectiveness of the intervention. Benchmarks on several language models and datasets show that our method outperforms baselines in reducing the generation of undesirable output.
Fake Advertisements Detection Using Automated Multimodal Learning: A Case Study for Vietnamese Real Estate Data
Jan 18, 2025The popularity of e-commerce has given rise to fake advertisements that can expose users to financial and data risks while damaging the reputation of these e-commerce platforms. For these reasons, detecting and removing such fake advertisements are important for the success of e-commerce websites. In this paper, we propose FADAML, a novel end-to-end machine learning system to detect and filter out fake online advertisements. Our system combines techniques in multimodal machine learning and automated machine learning to achieve a high detection rate. As a case study, we apply FADAML to detect fake advertisements on popular Vietnamese real estate websites. Our experiments show that we can achieve 91.5% detection accuracy, which significantly outperforms three different state-of-the-art fake news detection systems.