 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Rollout Allocation for Online Reinforcement Learning with Verifiable Rewards
Feb 03, 2026Sampling efficiency is a key bottleneck in reinforcement learning with verifiable rewards. Existing group-based policy optimization methods, such as GRPO, allocate a fixed number of rollouts for all training prompts. This uniform allocation implicitly treats all prompts as equally informative, and could lead to inefficient computational budget usage and impede training progress. We introduce VIP, a Variance-Informed Predictive allocation strategy that allocates a given rollout budget to the prompts in the incumbent batch to minimize the expected gradient variance of the policy update. At each iteration, VIP uses a lightweight Gaussian process model to predict per-prompt success probabilities based on recent rollouts. These probability predictions are translated into variance estimates, which are then fed into a convex optimization problem to determine the optimal rollout allocations under a hard compute budget constraint. Empirical results show that VIP consistently improves sampling efficiency and achieves higher performance than uniform or heuristic allocation strategies in multiple benchmarks.
Structured Pruning for Diverse Best-of-N Reasoning Optimization
Jun 09, 2025Model pruning in transformer-based language models, traditionally viewed as a means of achieving computational savings, can enhance the model's reasoning capabilities. In this work, we uncover a surprising phenomenon: the selective pruning of certain attention heads leads to improvements in reasoning performance, particularly on challenging tasks. Motivated by this observation, we propose SPRINT, a novel contrastive learning framework that dynamically selects the optimal head and layer to prune during inference. By aligning question embeddings with head embeddings, SPRINT identifies those pruned-head configurations that result in more accurate reasoning. Extensive experiments demonstrate that our method significantly outperforms traditional best-of-$N$ and random head selection strategies on the MATH500 and GSM8K datasets.
Mixture-of-Personas Language Models for Population Simulation
Apr 07, 2025


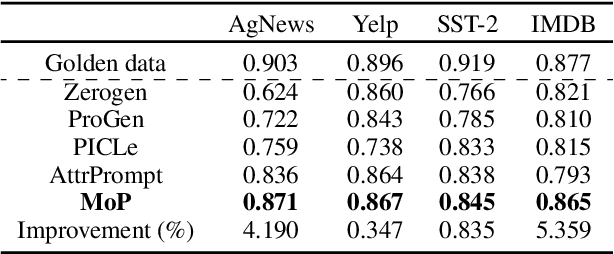
Advances in Large Language Models (LLMs) paved the way for their emerging applications in various domains, such as human behavior simulations, where LLMs could augment human-generated data in social science research and machine learning model training. However, pretrained LLMs often fail to capture the behavioral diversity of target populations due to the inherent variability across individuals and groups. To address this, we propose \textit{Mixture of Personas} (MoP), a \textit{probabilistic} prompting method that aligns the LLM responses with the target population. MoP is a contextual mixture model, where each component is an LM agent characterized by a persona and an exemplar representing subpopulation behaviors. The persona and exemplar are randomly chosen according to the learned mixing weights to elicit diverse LLM responses during simulation. MoP is flexible, requires no model finetuning, and is transferable across base models. Experiments for synthetic data generation show that MoP outperforms competing methods in alignment and diversity metrics.
Task-driven Layerwise Additive Activation Intervention
Feb 10, 2025



Modern language models (LMs) have significantly advanced generative modeling in natural language processing (NLP). Despite their success, LMs often struggle with adaptation to new contexts in real-time applications. A promising approach to task adaptation is activation intervention, which steers the LMs' generation process by identifying and manipulating the activations. However, existing interventions are highly dependent on heuristic rules or require many prompt inputs to determine effective interventions. This paper proposes a layer-wise additive activation intervention framework that optimizes the intervention process, thus enhancing the sample efficiency. We benchmark our framework on various datasets, demonstrating improvements in the accuracy of pre-trained LMs and competing intervention baselines.
Forget but Recall: Incremental Latent Rectification in Continual Learning
Jun 25, 2024



Intrinsic capability to continuously learn a changing data stream is a desideratum of deep neural networks (DNNs). However, current DNNs suffer from catastrophic forgetting, which hinders remembering past knowledge. To mitigate this issue, existing Continual Learning (CL) approaches either retain exemplars for replay, regularize learning, or allocate dedicated capacity for new tasks. This paper investigates an unexplored CL direction for incremental learning called Incremental Latent Rectification or ILR. In a nutshell, ILR learns to propagate with correction (or rectify) the representation from the current trained DNN backward to the representation space of the old task, where performing predictive decisions is easier. This rectification process only employs a chain of small representation mapping networks, called rectifier units. Empirical experiments on several continual learning benchmarks, including CIFAR10, CIFAR100, and Tiny ImageNet, demonstrate the effectiveness and potential of this novel CL direction compared to existing representative CL methods.
Generative Conditional Distributions by Neural (Entropic) Optimal Transport
Jun 04, 2024
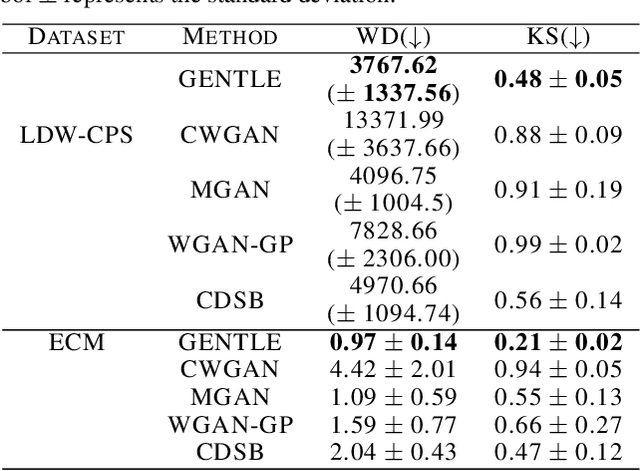
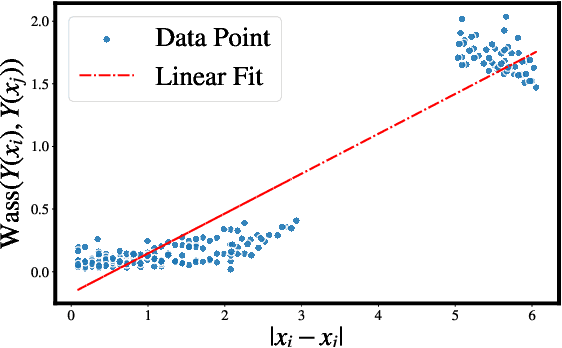
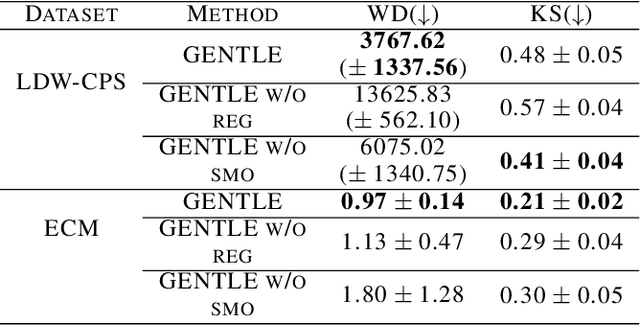
Learning conditional distributions is challenging because the desired outcome is not a single distribution but multiple distributions that correspond to multiple instances of the covariates. We introduce a novel neural entropic optimal transport method designed to effectively learn generative models of conditional distributions, particularly in scenarios characterized by limited sample sizes. Our method relies on the minimax training of two neural networks: a generative network parametrizing the inverse cumulative distribution functions of the conditional distributions and another network parametrizing the conditional Kantorovich potential. To prevent overfitting, we regularize the objective function by penalizing the Lipschitz constant of the network output. Our experiments on real-world datasets show the effectiveness of our algorithm compared to state-of-the-art conditional distribution learning techniques. Our implementation can be found at https://github.com/nguyenngocbaocmt02/GENTLE.
Cold-start Recommendation by Personalized Embedding Region Elicitation
Jun 03, 2024
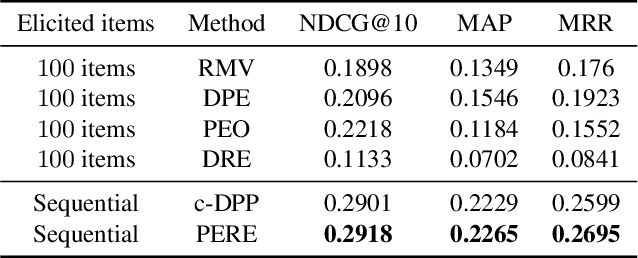
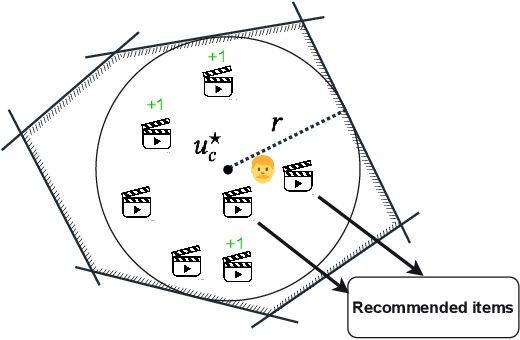
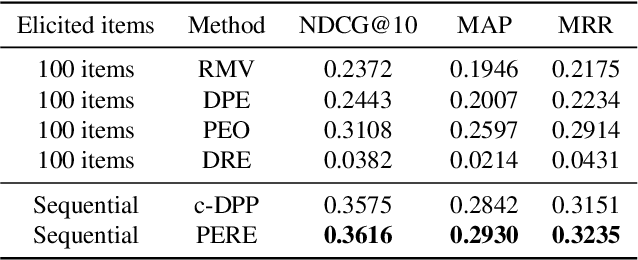
Rating elicitation is a success element for recommender systems to perform well at cold-starting, in which the systems need to recommend items to a newly arrived user with no prior knowledge about the user's preference. Existing elicitation methods employ a fixed set of items to learn the user's preference and then infer the users' preferences on the remaining items. Using a fixed seed set can limit the performance of the recommendation system since the seed set is unlikely optimal for all new users with potentially diverse preferences. This paper addresses this challenge using a 2-phase, personalized elicitation scheme. First, the elicitation scheme asks users to rate a small set of popular items in a ``burn-in'' phase. Second, it sequentially asks the user to rate adaptive items to refine the preference and the user's representation. Throughout the process, the system represents the user's embedding value not by a point estimate but by a region estimate. The value of information obtained by asking the user's rating on an item is quantified by the distance from the region center embedding space that contains with high confidence the true embedding value of the user. Finally, the recommendations are successively generated by considering the preference region of the user. We show that each subproblem in the elicitation scheme can be efficiently implemented. Further, we empirically demonstrate the effectiveness of the proposed method against existing rating-elicitation methods on several prominent datasets.
Explaining Graph Neural Networks via Structure-aware Interaction Index
May 23, 2024



The Shapley value is a prominent tool for interpreting black-box machine learning models thanks to its strong theoretical foundation. However, for models with structured inputs, such as graph neural networks, existing Shapley-based explainability approaches either focus solely on node-wise importance or neglect the graph structure when perturbing the input instance. This paper introduces the Myerson-Taylor interaction index that internalizes the graph structure into attributing the node values and the interaction values among nodes. Unlike the Shapley-based methods, the Myerson-Taylor index decomposes coalitions into components satisfying a pre-chosen connectivity criterion. We prove that the Myerson-Taylor index is the unique one that satisfies a system of five natural axioms accounting for graph structure and high-order interaction among nodes. Leveraging these properties, we propose Myerson-Taylor Structure-Aware Graph Explainer (MAGE), a novel explainer that uses the second-order Myerson-Taylor index to identify the most important motifs influencing the model prediction, both positively and negatively. Extensive experiments on various graph datasets and models demonstrate that our method consistently provides superior subgraph explanations compared to state-of-the-art methods.