 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Personas Language Models for Population Simulation
Apr 07, 2025


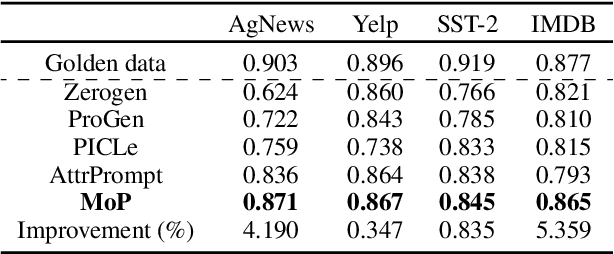
Advances in Large Language Models (LLMs) paved the way for their emerging applications in various domains, such as human behavior simulations, where LLMs could augment human-generated data in social science research and machine learning model training. However, pretrained LLMs often fail to capture the behavioral diversity of target populations due to the inherent variability across individuals and groups. To address this, we propose \textit{Mixture of Personas} (MoP), a \textit{probabilistic} prompting method that aligns the LLM responses with the target population. MoP is a contextual mixture model, where each component is an LM agent characterized by a persona and an exemplar representing subpopulation behaviors. The persona and exemplar are randomly chosen according to the learned mixing weights to elicit diverse LLM responses during simulation. MoP is flexible, requires no model finetuning, and is transferable across base models. Experiments for synthetic data generation show that MoP outperforms competing methods in alignment and diversity metrics.