 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Personas Language Models for Population Simulation
Apr 07, 2025


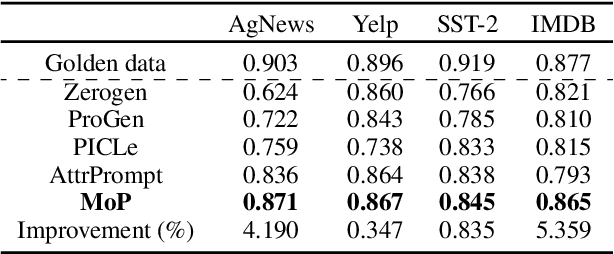
Advances in Large Language Models (LLMs) paved the way for their emerging applications in various domains, such as human behavior simulations, where LLMs could augment human-generated data in social science research and machine learning model training. However, pretrained LLMs often fail to capture the behavioral diversity of target populations due to the inherent variability across individuals and groups. To address this, we propose \textit{Mixture of Personas} (MoP), a \textit{probabilistic} prompting method that aligns the LLM responses with the target population. MoP is a contextual mixture model, where each component is an LM agent characterized by a persona and an exemplar representing subpopulation behaviors. The persona and exemplar are randomly chosen according to the learned mixing weights to elicit diverse LLM responses during simulation. MoP is flexible, requires no model finetuning, and is transferable across base models. Experiments for synthetic data generation show that MoP outperforms competing methods in alignment and diversity metrics.
Development of a Dataset and a Deep Learning Baseline Named Entity Recognizer for Three Low Resource Languages: Bhojpuri, Maithili and Magahi
Sep 14, 2020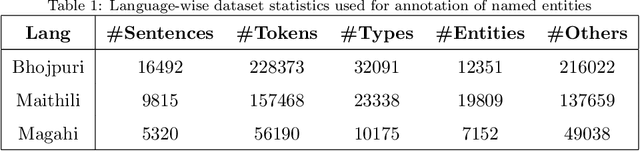
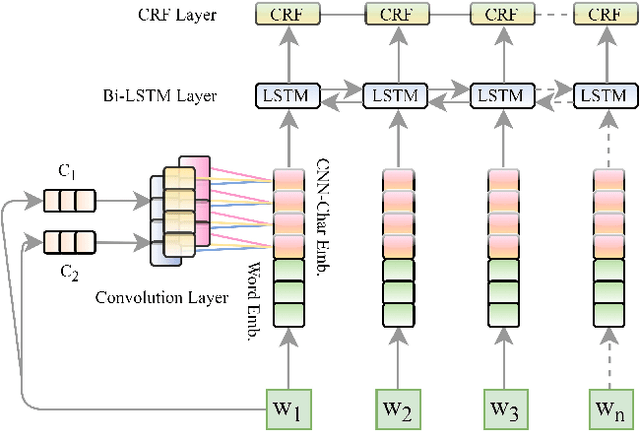
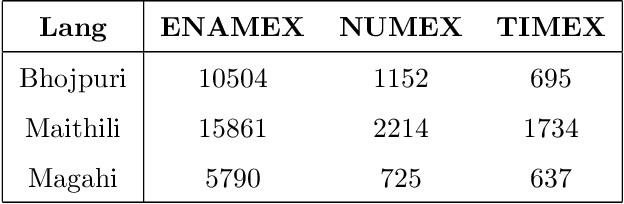
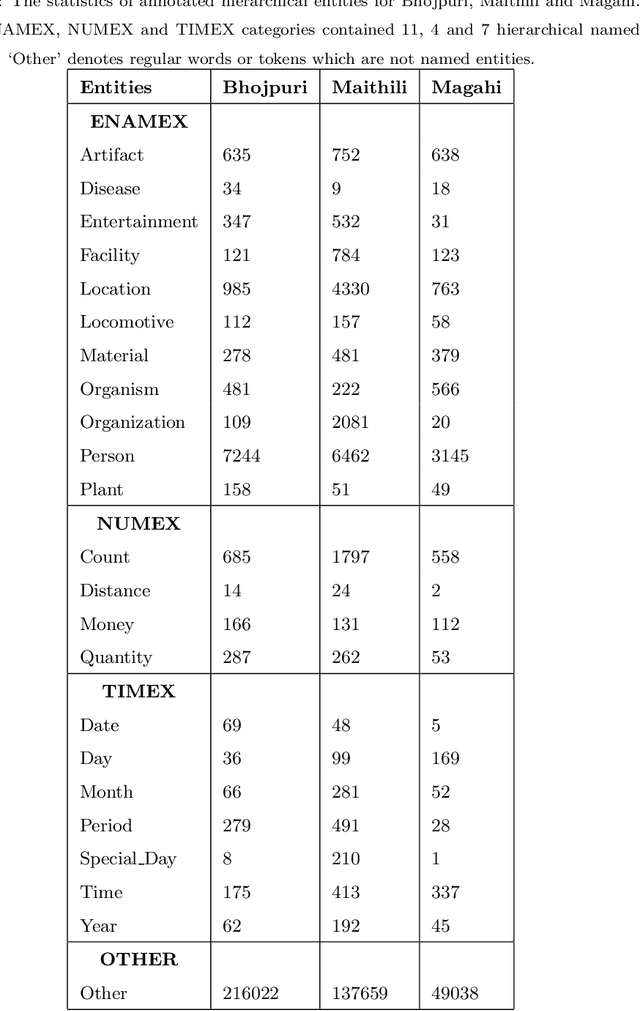
In Natural Language Processing (NLP) pipelines, Named Entity Recognition (NER) is one of the preliminary problems, which marks proper nouns and other named entities such as Location, Person, Organization, Disease etc. Such entities, without a NER module, adversely affect the performance of a machine translation system. NER helps in overcoming this problem by recognising and handling such entities separately, although it can be useful in Information Extraction systems also. Bhojpuri, Maithili and Magahi are low resource languages, usually known as Purvanchal languages. This paper focuses on the development of a NER benchmark dataset for the Machine Translation systems developed to translate from these languages to Hindi by annotating parts of their available corpora. Bhojpuri, Maithili and Magahi corpora of sizes 228373, 157468 and 56190 tokens, respectively, were annotated using 22 entity labels. The annotation considers coarse-grained annotation labels followed by the tagset used in one of the Hindi NER datasets. We also report a Deep Learning based baseline that uses an LSTM-CNNs-CRF model. The lower baseline F1-scores from the NER tool obtained by using Conditional Random Fields models are 96.73 for Bhojpuri, 93.33 for Maithili and 95.04 for Magahi. The Deep Learning-based technique (LSTM-CNNs-CRF) achieved 96.25 for Bhojpuri, 93.33 for Maithili and 95.44 for Magahi.
A Survey of Deep Learning Methods for Relation Extraction
May 10, 2017



Relation Extraction is an important sub-task of Information Extraction which has the potential of employing deep learning (DL) models with the creation of large datasets using distant supervision. In this review, we compare the contributions and pitfalls of the various DL models that have been used for the task, to help guide the path ahead.