 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign-o-meter: Towards Evaluating and Refining Graphic Designs
Nov 22, 2024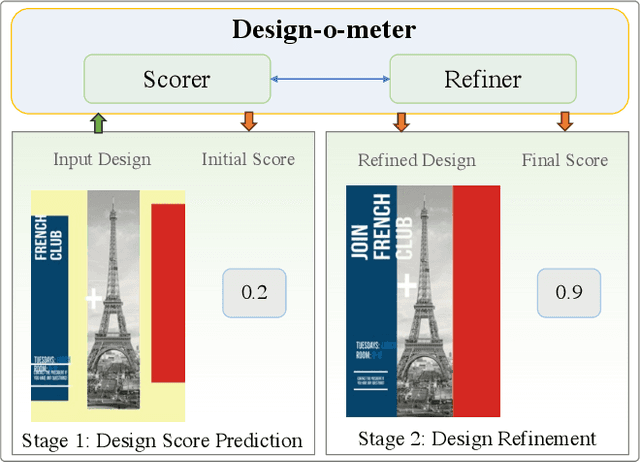
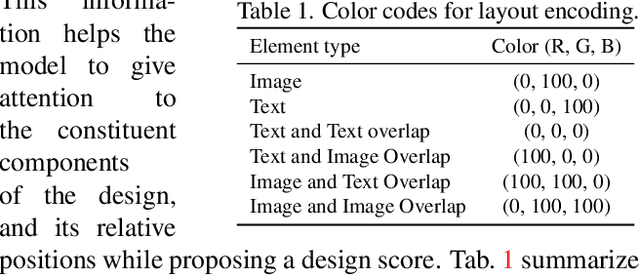
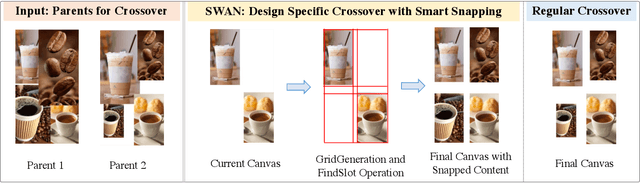
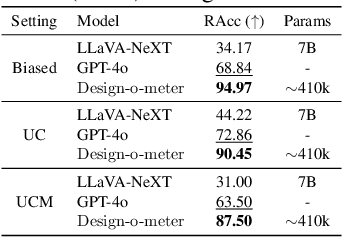
Graphic designs are an effective medium for visual communication. They range from greeting cards to corporate flyers and beyond. Off-late, machine learning techniques are able to generate such designs, which accelerates the rate of content production. An automated way of evaluating their quality becomes critical. Towards this end, we introduce Design-o-meter, a data-driven methodology to quantify the goodness of graphic designs. Further, our approach can suggest modifications to these designs to improve its visual appeal. To the best of our knowledge, Design-o-meter is the first approach that scores and refines designs in a unified framework despite the inherent subjectivity and ambiguity of the setting. Our exhaustive quantitative and qualitative analysis of our approach against baselines adapted for the task (including recent Multimodal LLM-based approaches) brings out the efficacy of our methodology. We hope our work will usher more interest in this important and pragmatic problem setting.
Development of a Dataset and a Deep Learning Baseline Named Entity Recognizer for Three Low Resource Languages: Bhojpuri, Maithili and Magahi
Sep 14, 2020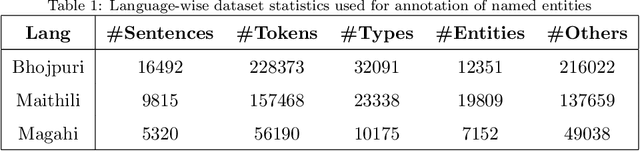
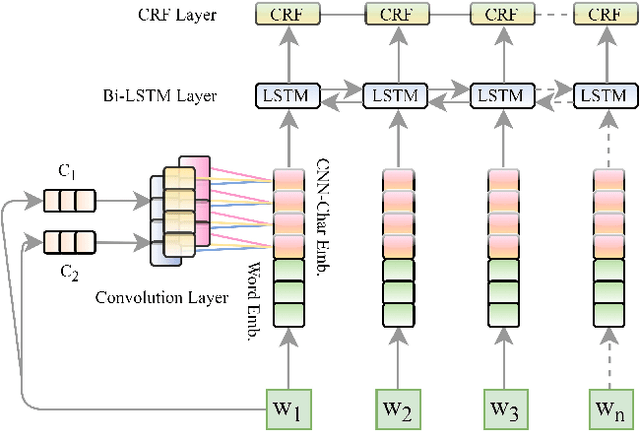
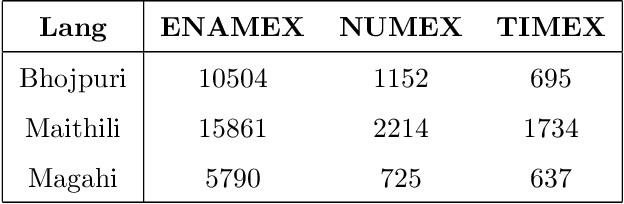
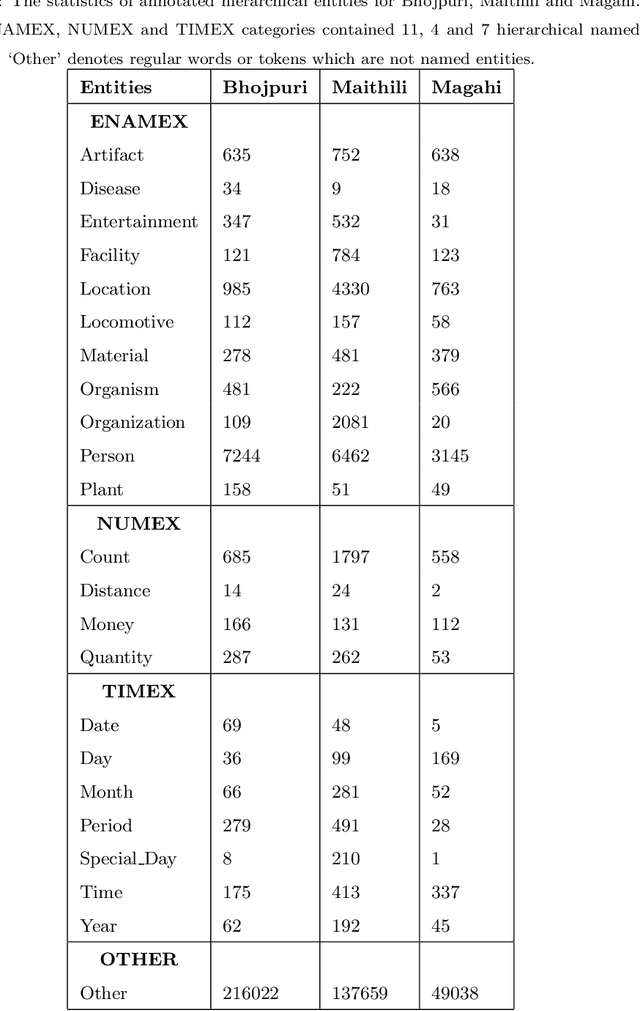
In Natural Language Processing (NLP) pipelines, Named Entity Recognition (NER) is one of the preliminary problems, which marks proper nouns and other named entities such as Location, Person, Organization, Disease etc. Such entities, without a NER module, adversely affect the performance of a machine translation system. NER helps in overcoming this problem by recognising and handling such entities separately, although it can be useful in Information Extraction systems also. Bhojpuri, Maithili and Magahi are low resource languages, usually known as Purvanchal languages. This paper focuses on the development of a NER benchmark dataset for the Machine Translation systems developed to translate from these languages to Hindi by annotating parts of their available corpora. Bhojpuri, Maithili and Magahi corpora of sizes 228373, 157468 and 56190 tokens, respectively, were annotated using 22 entity labels. The annotation considers coarse-grained annotation labels followed by the tagset used in one of the Hindi NER datasets. We also report a Deep Learning based baseline that uses an LSTM-CNNs-CRF model. The lower baseline F1-scores from the NER tool obtained by using Conditional Random Fields models are 96.73 for Bhojpuri, 93.33 for Maithili and 95.04 for Magahi. The Deep Learning-based technique (LSTM-CNNs-CRF) achieved 96.25 for Bhojpuri, 93.33 for Maithili and 95.44 for Magahi.
Basic Linguistic Resources and Baselines for Bhojpuri, Magahi and Maithili for Natural Language Processing
Apr 29, 2020
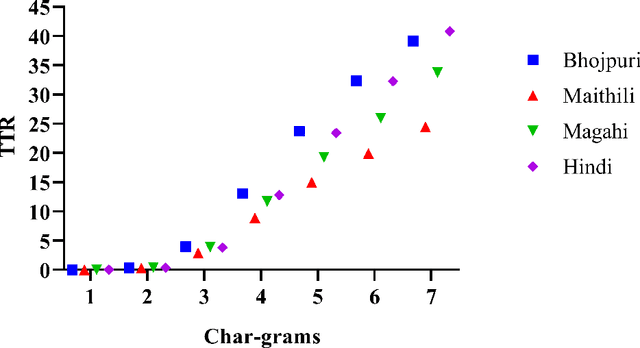

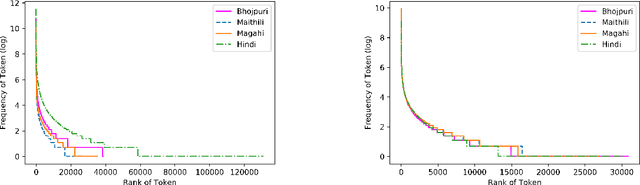
Corpus preparation for low-resource languages and for development of human language technology to analyze or computationally process them is a laborious task, primarily due to the unavailability of expert linguists who are native speakers of these languages and also due to the time and resources required. Bhojpuri, Magahi, and Maithili, languages of the Purvanchal region of India (in the north-eastern parts), are low-resource languages belonging to the Indo-Aryan (or Indic) family. They are closely related to Hindi, which is a relatively high-resource language, which is why we make our comparisons with Hindi. We collected corpora for these three languages from various sources and cleaned them to the extent possible, without changing the data in them. The text belongs to different domains and genres. We calculated some basic statistical measures for these corpora at character, word, syllable, and morpheme levels. These corpora were also annotated with parts-of-speech (POS) and chunk tags. The basic statistical measures were both absolute and relative and were meant to give an indication of linguistic properties such as morphological, lexical, phonological, and syntactic complexities (or richness). The results were compared with a standard Hindi corpus. For most of the measures, we tried to keep the size of the corpus the same across the languages so as to avoid the effect of corpus size, but in some cases it turned out that using the full corpus was better, even if sizes were very different. Although the results are not very clear, we try to draw some conclusions about the languages and the corpora. For POS tagging and chunking, the BIS tagset was used to manually annotate the data. The sizes of the POS tagged data are 16067, 14669 and 12310 sentences, respectively for Bhojpuri, Magahi and Maithili. The sizes for chunking are 9695 and 1954 sentences for Bhojpuri and Maithili, respect