 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePADRe: A Unifying Polynomial Attention Drop-in Replacement for Efficient Vision Transformer
Jul 16, 2024



We present Polynomial Attention Drop-in Replacement (PADRe), a novel and unifying framework designed to replace the conventional self-attention mechanism in transformer models. Notably, several recent alternative attention mechanisms, including Hyena, Mamba, SimA, Conv2Former, and Castling-ViT, can be viewed as specific instances of our PADRe framework. PADRe leverages polynomial functions and draws upon established results from approximation theory, enhancing computational efficiency without compromising accuracy. PADRe's key components include multiplicative nonlinearities, which we implement using straightforward, hardware-friendly operations such as Hadamard products, incurring only linear computational and memory costs. PADRe further avoids the need for using complex functions such as Softmax, yet it maintains comparable or superior accuracy compared to traditional self-attention. We assess the effectiveness of PADRe as a drop-in replacement for self-attention across diverse computer vision tasks. These tasks include image classification, image-based 2D object detection, and 3D point cloud object detection. Empirical results demonstrate that PADRe runs significantly faster than the conventional self-attention (11x ~ 43x faster on server GPU and mobile NPU) while maintaining similar accuracy when substituting self-attention in the transformer models.
ToSA: Token Selective Attention for Efficient Vision Transformers
Jun 13, 2024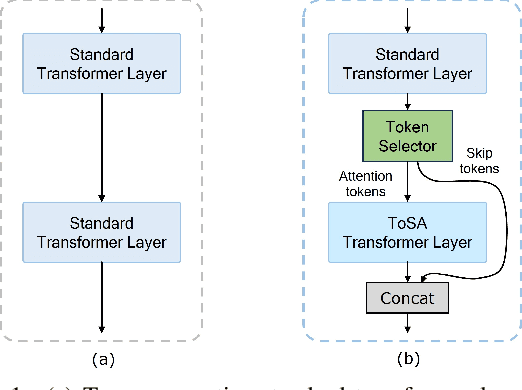
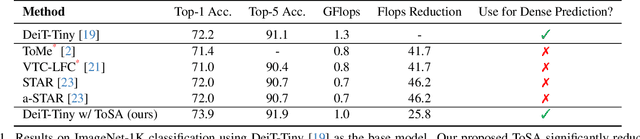
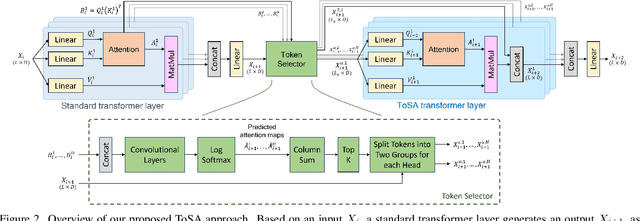

In this paper, we propose a novel token selective attention approach, ToSA, which can identify tokens that need to be attended as well as those that can skip a transformer layer. More specifically, a token selector parses the current attention maps and predicts the attention maps for the next layer, which are then used to select the important tokens that should participate in the attention operation. The remaining tokens simply bypass the next layer and are concatenated with the attended ones to re-form a complete set of tokens. In this way, we reduce the quadratic computation and memory costs as fewer tokens participate in self-attention while maintaining the features for all the image patches throughout the network, which allows it to be used for dense prediction tasks. Our experiments show that by applying ToSA, we can significantly reduce computation costs while maintaining accuracy on the ImageNet classification benchmark. Furthermore, we evaluate on the dense prediction task of monocular depth estimation on NYU Depth V2, and show that we can achieve similar depth prediction accuracy using a considerably lighter backbone with ToSA.
GreenShield: CNN-Based Real-Time Forest Monitoring and Response
Jun 10, 2024This research introduces an innovative forest monitoring system designed to detect and mitigate the threats of forest fires. The proposed system leverages Arduino-based technology integrated with state-of-the-art sensors, including DHT11 for temperature and humidity detection and Flame sensor along with GSM module for gas and smoke detection. The integration of these sensors enables real-time data acquisition and analysis, providing a comprehensive and accurate assessment of environmental conditions within the forest ecosystem. The Arduino platform serves as the central processing unit, orchestrating the communication and synchronization of the sensor data. The DHT11 sensor monitors ambient temperature and humidity levels, crucial indicators for assessing fire risk and identifying potential deforestation activities. Simultaneously, the Flame sensor module detects the occurrence of fire flames nearby thus indicating it by a buzzer. The collected data is processed through an intelligent algorithm that employs machine learning techniques to discern patterns indicative of potential threats. The system is equipped with an adaptive threshold mechanism, allowing it to dynamically adjust to changing environmental conditions. In the event of abnormal readings or anomalies, the system triggers immediate alerts, notifying forest rangers and relevant authorities to facilitate timely response and intervention. The integration of low-cost, easily deployable Arduino-based devices makes this solution scalable and accessible for implementation across diverse forest environments. The proposed system represents a significant step towards leveraging technology to address environmental challenges and protect our forests.
FutureDepth: Learning to Predict the Future Improves Video Depth Estimation
Mar 19, 2024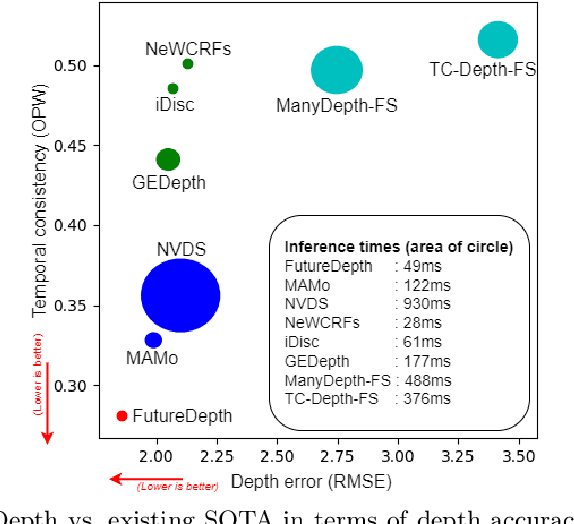
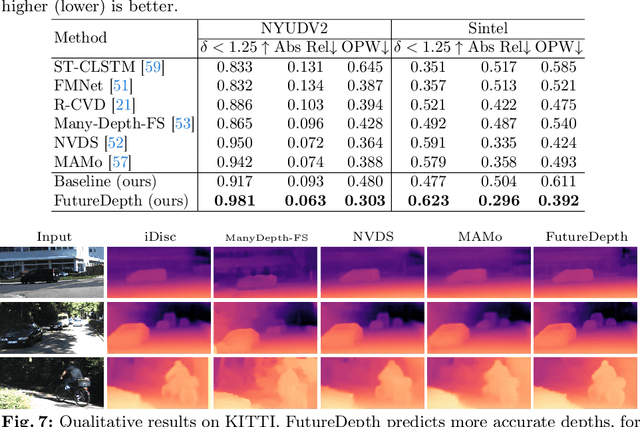
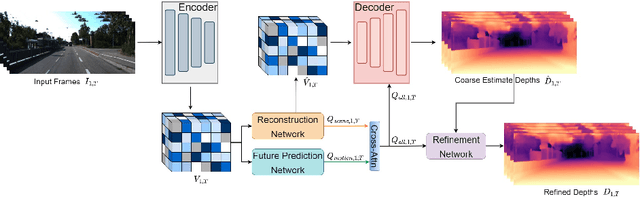
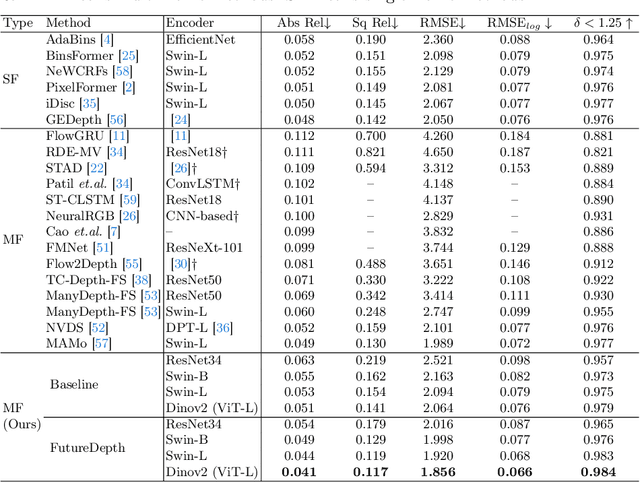
In this paper, we propose a novel video depth estimation approach, FutureDepth, which enables the model to implicitly leverage multi-frame and motion cues to improve depth estimation by making it learn to predict the future at training. More specifically, we propose a future prediction network, F-Net, which takes the features of multiple consecutive frames and is trained to predict multi-frame features one time step ahead iteratively. In this way, F-Net learns the underlying motion and correspondence information, and we incorporate its features into the depth decoding process. Additionally, to enrich the learning of multiframe correspondence cues, we further leverage a reconstruction network, R-Net, which is trained via adaptively masked auto-encoding of multiframe feature volumes. At inference time, both F-Net and R-Net are used to produce queries to work with the depth decoder, as well as a final refinement network. Through extensive experiments on several benchmarks, i.e., NYUDv2, KITTI, DDAD, and Sintel, which cover indoor, driving, and open-domain scenarios, we show that FutureDepth significantly improves upon baseline models, outperforms existing video depth estimation methods, and sets new state-of-the-art (SOTA) accuracy. Furthermore, FutureDepth is more efficient than existing SOTA video depth estimation models and has similar latencies when comparing to monocular models
DeCoTR: Enhancing Depth Completion with 2D and 3D Attentions
Mar 18, 2024In this paper, we introduce a novel approach that harnesses both 2D and 3D attentions to enable highly accurate depth completion without requiring iterative spatial propagations. Specifically, we first enhance a baseline convolutional depth completion model by applying attention to 2D features in the bottleneck and skip connections. This effectively improves the performance of this simple network and sets it on par with the latest, complex transformer-based models. Leveraging the initial depths and features from this network, we uplift the 2D features to form a 3D point cloud and construct a 3D point transformer to process it, allowing the model to explicitly learn and exploit 3D geometric features. In addition, we propose normalization techniques to process the point cloud, which improves learning and leads to better accuracy than directly using point transformers off the shelf. Furthermore, we incorporate global attention on downsampled point cloud features, which enables long-range context while still being computationally feasible. We evaluate our method, DeCoTR, on established depth completion benchmarks, including NYU Depth V2 and KITTI, showcasing that it sets new state-of-the-art performance. We further conduct zero-shot evaluations on ScanNet and DDAD benchmarks and demonstrate that DeCoTR has superior generalizability compared to existing approaches.
Differentiable bit-rate estimation for neural-based video codec enhancement
Jan 24, 2023



Neural networks (NN) can improve standard video compression by pre- and post-processing the encoded video. For optimal NN training, the standard codec needs to be replaced with a codec proxy that can provide derivatives of estimated bit-rate and distortion, which are used for gradient back-propagation. Since entropy coding of standard codecs is designed to take into account non-linear dependencies between transform coefficients, bit-rates cannot be well approximated with simple per-coefficient estimators. This paper presents a new approach for bit-rate estimation that is similar to the type employed in training end-to-end neural codecs, and able to efficiently take into account those statistical dependencies. It is defined from a mathematical model that provides closed-form formulas for the estimates and their gradients, reducing the computational complexity. Experimental results demonstrate the method's accuracy in estimating HEVC/H.265 codec bit-rates.
Multitask Bandit Learning through Heterogeneous Feedback Aggregation
Oct 29, 2020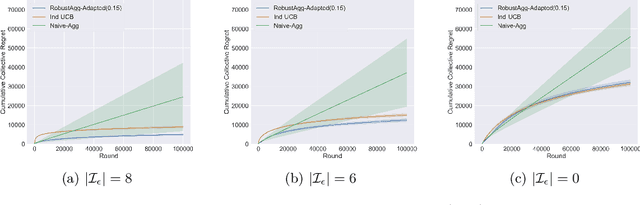
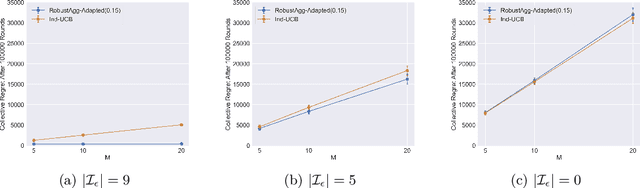
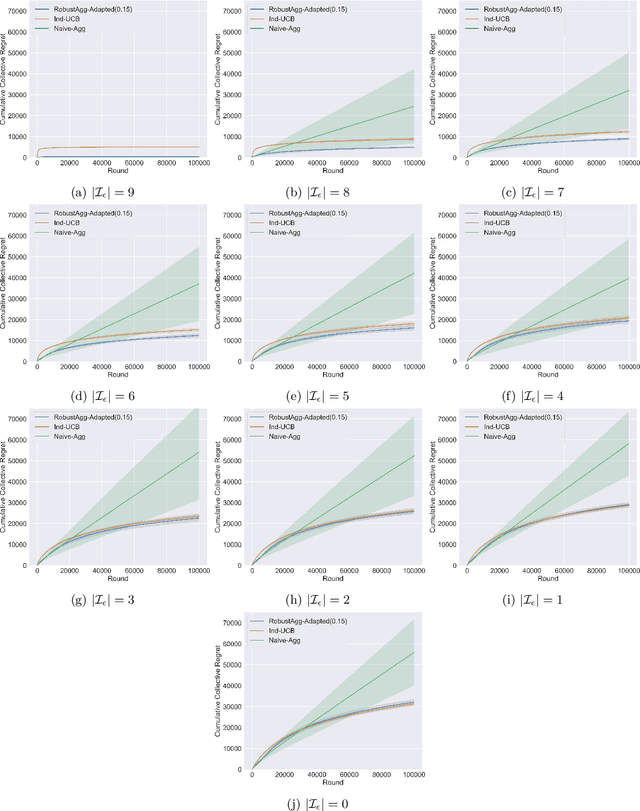
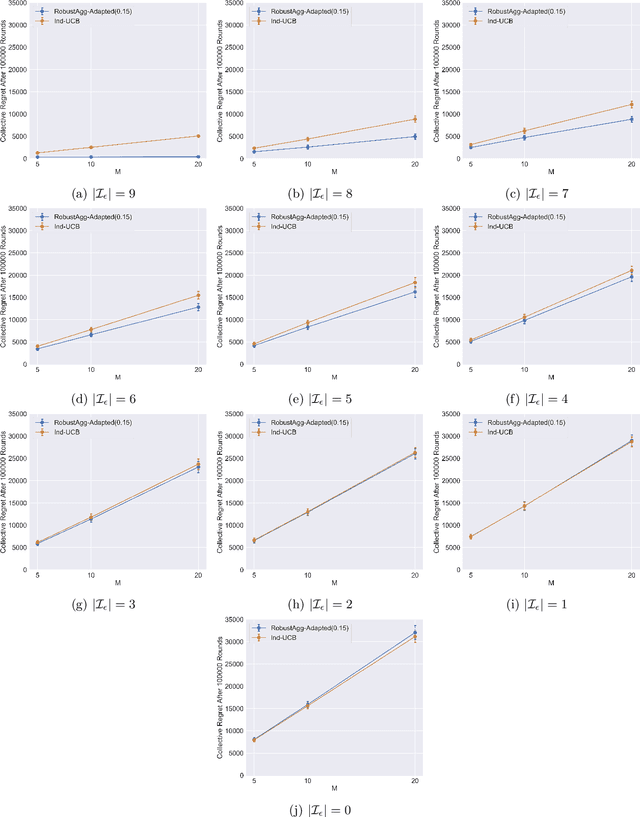
In many real-world applications, multiple agents seek to learn how to perform highly related yet slightly different tasks in an online bandit learning protocol. We formulate this problem as the $\epsilon$-multi-player multi-armed bandit problem, in which a set of players concurrently interact with a set of arms, and for each arm, the reward distributions for all players are similar but not necessarily identical. We develop an upper confidence bound-based algorithm, RobustAgg$(\epsilon)$, that adaptively aggregates rewards collected by different players. In the setting where an upper bound on the pairwise similarities of reward distributions between players is known, we achieve instance-dependent regret guarantees that depend on the amenability of information sharing across players. We complement these upper bounds with nearly matching lower bounds. In the setting where pairwise similarities are unknown, we provide a lower bound, as well as an algorithm that trades off minimax regret guarantees for adaptivity to unknown similarity structure.
Basic Linguistic Resources and Baselines for Bhojpuri, Magahi and Maithili for Natural Language Processing
Apr 29, 2020
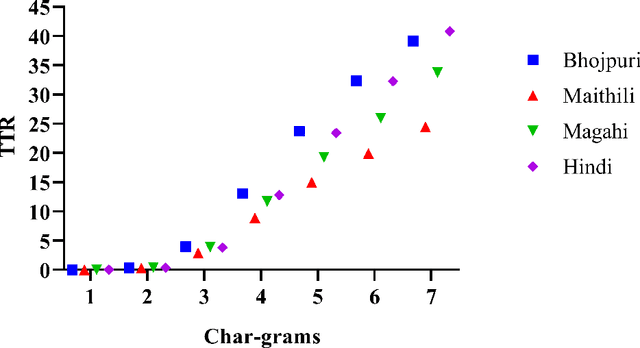

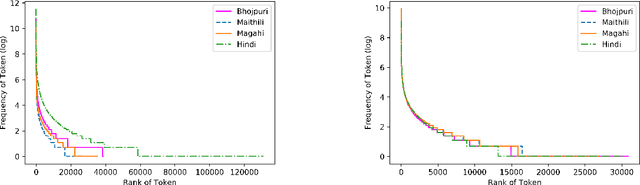
Corpus preparation for low-resource languages and for development of human language technology to analyze or computationally process them is a laborious task, primarily due to the unavailability of expert linguists who are native speakers of these languages and also due to the time and resources required. Bhojpuri, Magahi, and Maithili, languages of the Purvanchal region of India (in the north-eastern parts), are low-resource languages belonging to the Indo-Aryan (or Indic) family. They are closely related to Hindi, which is a relatively high-resource language, which is why we make our comparisons with Hindi. We collected corpora for these three languages from various sources and cleaned them to the extent possible, without changing the data in them. The text belongs to different domains and genres. We calculated some basic statistical measures for these corpora at character, word, syllable, and morpheme levels. These corpora were also annotated with parts-of-speech (POS) and chunk tags. The basic statistical measures were both absolute and relative and were meant to give an indication of linguistic properties such as morphological, lexical, phonological, and syntactic complexities (or richness). The results were compared with a standard Hindi corpus. For most of the measures, we tried to keep the size of the corpus the same across the languages so as to avoid the effect of corpus size, but in some cases it turned out that using the full corpus was better, even if sizes were very different. Although the results are not very clear, we try to draw some conclusions about the languages and the corpora. For POS tagging and chunking, the BIS tagset was used to manually annotate the data. The sizes of the POS tagged data are 16067, 14669 and 12310 sentences, respectively for Bhojpuri, Magahi and Maithili. The sizes for chunking are 9695 and 1954 sentences for Bhojpuri and Maithili, respect