 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation by Projecting Text into the Same Phonetic-Orthographic Space Using a Common Encoding
May 21, 2023The use of subword embedding has proved to be a major innovation in Neural Machine Translation (NMT). It helps NMT to learn better context vectors for Low Resource Languages (LRLs) so as to predict the target words by better modelling the morphologies of the two languages and also the morphosyntax transfer. Even so, their performance for translation in Indian language to Indian language scenario is still not as good as for resource-rich languages. One reason for this is the relative morphological richness of Indian languages, while another is that most of them fall into the extremely low resource or zero-shot categories. Since most major Indian languages use Indic or Brahmi origin scripts, the text written in them is highly phonetic in nature and phonetically similar in terms of abstract letters and their arrangements. We use these characteristics of Indian languages and their scripts to propose an approach based on common multilingual Latin-based encodings (WX notation) that take advantage of language similarity while addressing the morphological complexity issue in NMT. These multilingual Latin-based encodings in NMT, together with Byte Pair Embedding (BPE) allow us to better exploit their phonetic and orthographic as well as lexical similarities to improve the translation quality by projecting different but similar languages on the same orthographic-phonetic character space. We verify the proposed approach by demonstrating experiments on similar language pairs (Gujarati-Hindi, Marathi-Hindi, Nepali-Hindi, Maithili-Hindi, Punjabi-Hindi, and Urdu-Hindi) under low resource conditions. The proposed approach shows an improvement in a majority of cases, in one case as much as ~10 BLEU points compared to baseline techniques for similar language pairs. We also get up to ~1 BLEU points improvement on distant and zero-shot language pairs.
Exploiting Multilingualism in Low-resource Neural Machine Translation via Adversarial Learning
Mar 31, 2023



Generative Adversarial Networks (GAN) offer a promising approach for Neural Machine Translation (NMT). However, feeding multiple morphologically languages into a single model during training reduces the NMT's performance. In GAN, similar to bilingual models, multilingual NMT only considers one reference translation for each sentence during model training. This single reference translation limits the GAN model from learning sufficient information about the source sentence representation. Thus, in this article, we propose Denoising Adversarial Auto-encoder-based Sentence Interpolation (DAASI) approach to perform sentence interpolation by learning the intermediate latent representation of the source and target sentences of multilingual language pairs. Apart from latent representation, we also use the Wasserstein-GAN approach for the multilingual NMT model by incorporating the model generated sentences of multiple languages for reward computation. This computed reward optimizes the performance of the GAN-based multilingual model in an effective manner. We demonstrate the experiments on low-resource language pairs and find that our approach outperforms the existing state-of-the-art approaches for multilingual NMT with a performance gain of up to 4 BLEU points. Moreover, we use our trained model on zero-shot language pairs under an unsupervised scenario and show the robustness of the proposed approach.
Exploiting Language Relatedness in Machine Translation Through Domain Adaptation Techniques
Mar 03, 2023



One of the significant challenges of Machine Translation (MT) is the scarcity of large amounts of data, mainly parallel sentence aligned corpora. If the evaluation is as rigorous as resource-rich languages, both Neural Machine Translation (NMT) and Statistical Machine Translation (SMT) can produce good results with such large amounts of data. However, it is challenging to improve the quality of MT output for low resource languages, especially in NMT and SMT. In order to tackle the challenges faced by MT, we present a novel approach of using a scaled similarity score of sentences, especially for related languages based on a 5-gram KenLM language model with Kneser-ney smoothing technique for filtering in-domain data from out-of-domain corpora that boost the translation quality of MT. Furthermore, we employ other domain adaptation techniques such as multi-domain, fine-tuning and iterative back-translation approach to compare our novel approach on the Hindi-Nepali language pair for NMT and SMT. Our approach succeeds in increasing ~2 BLEU point on multi-domain approach, ~3 BLEU point on fine-tuning for NMT and ~2 BLEU point on iterative back-translation approach.
Development of a Dataset and a Deep Learning Baseline Named Entity Recognizer for Three Low Resource Languages: Bhojpuri, Maithili and Magahi
Sep 14, 2020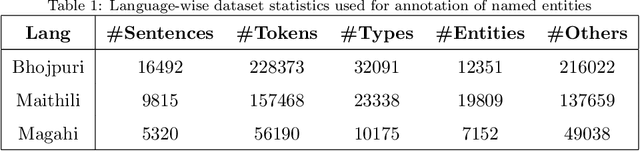
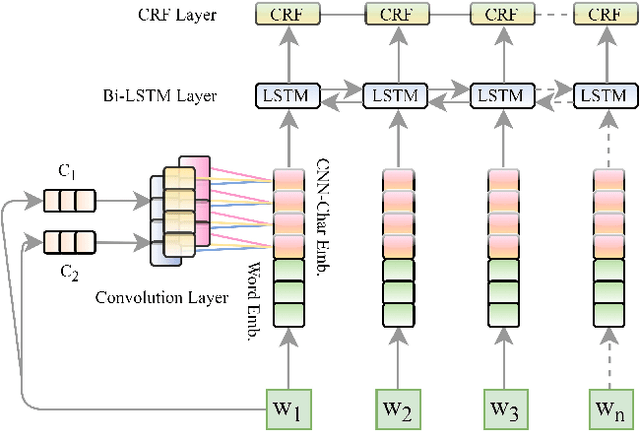
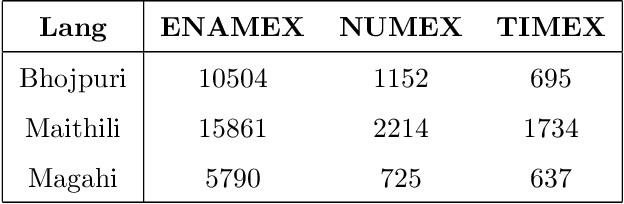
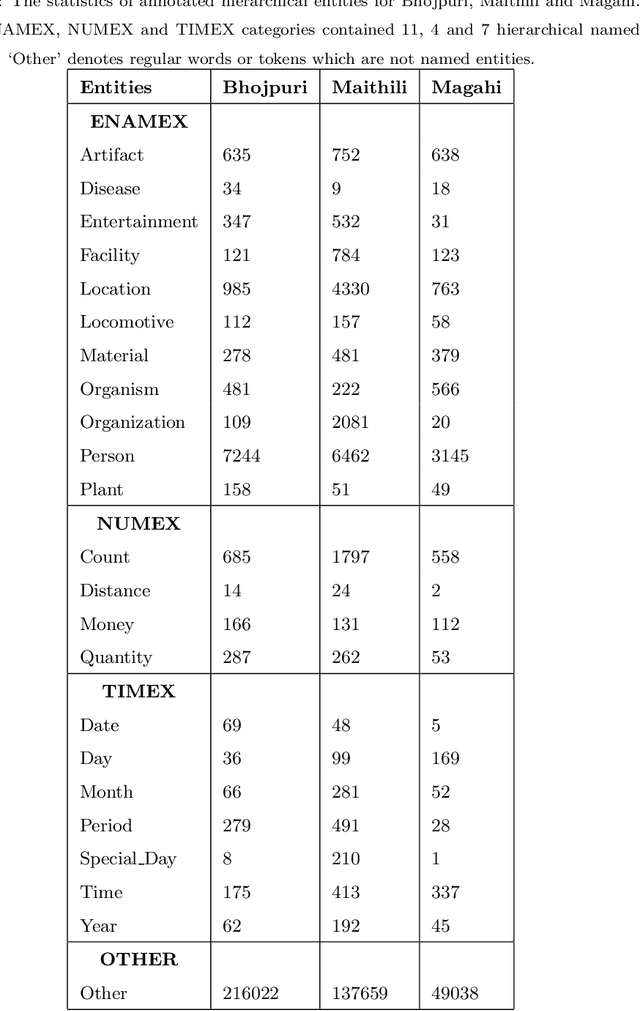
In Natural Language Processing (NLP) pipelines, Named Entity Recognition (NER) is one of the preliminary problems, which marks proper nouns and other named entities such as Location, Person, Organization, Disease etc. Such entities, without a NER module, adversely affect the performance of a machine translation system. NER helps in overcoming this problem by recognising and handling such entities separately, although it can be useful in Information Extraction systems also. Bhojpuri, Maithili and Magahi are low resource languages, usually known as Purvanchal languages. This paper focuses on the development of a NER benchmark dataset for the Machine Translation systems developed to translate from these languages to Hindi by annotating parts of their available corpora. Bhojpuri, Maithili and Magahi corpora of sizes 228373, 157468 and 56190 tokens, respectively, were annotated using 22 entity labels. The annotation considers coarse-grained annotation labels followed by the tagset used in one of the Hindi NER datasets. We also report a Deep Learning based baseline that uses an LSTM-CNNs-CRF model. The lower baseline F1-scores from the NER tool obtained by using Conditional Random Fields models are 96.73 for Bhojpuri, 93.33 for Maithili and 95.04 for Magahi. The Deep Learning-based technique (LSTM-CNNs-CRF) achieved 96.25 for Bhojpuri, 93.33 for Maithili and 95.44 for Magahi.
Basic Linguistic Resources and Baselines for Bhojpuri, Magahi and Maithili for Natural Language Processing
Apr 29, 2020
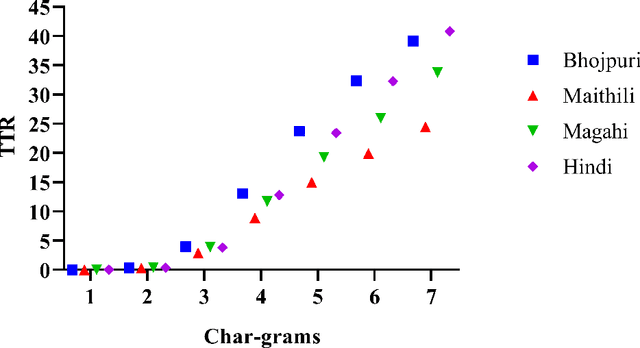

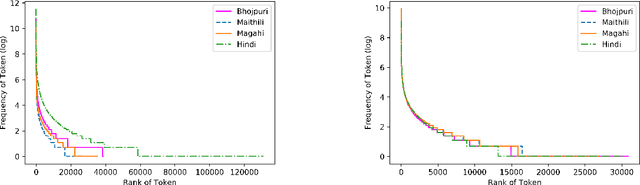
Corpus preparation for low-resource languages and for development of human language technology to analyze or computationally process them is a laborious task, primarily due to the unavailability of expert linguists who are native speakers of these languages and also due to the time and resources required. Bhojpuri, Magahi, and Maithili, languages of the Purvanchal region of India (in the north-eastern parts), are low-resource languages belonging to the Indo-Aryan (or Indic) family. They are closely related to Hindi, which is a relatively high-resource language, which is why we make our comparisons with Hindi. We collected corpora for these three languages from various sources and cleaned them to the extent possible, without changing the data in them. The text belongs to different domains and genres. We calculated some basic statistical measures for these corpora at character, word, syllable, and morpheme levels. These corpora were also annotated with parts-of-speech (POS) and chunk tags. The basic statistical measures were both absolute and relative and were meant to give an indication of linguistic properties such as morphological, lexical, phonological, and syntactic complexities (or richness). The results were compared with a standard Hindi corpus. For most of the measures, we tried to keep the size of the corpus the same across the languages so as to avoid the effect of corpus size, but in some cases it turned out that using the full corpus was better, even if sizes were very different. Although the results are not very clear, we try to draw some conclusions about the languages and the corpora. For POS tagging and chunking, the BIS tagset was used to manually annotate the data. The sizes of the POS tagged data are 16067, 14669 and 12310 sentences, respectively for Bhojpuri, Magahi and Maithili. The sizes for chunking are 9695 and 1954 sentences for Bhojpuri and Maithili, respect
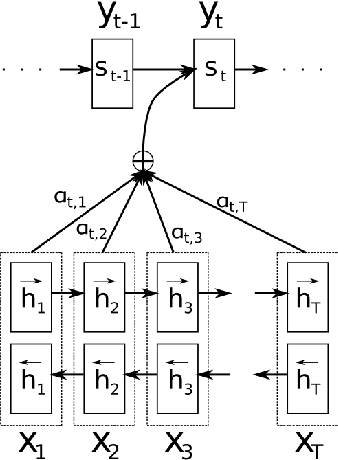
IIT Varanasi at MSR-SRST 2018: A Language Model Based Approach for Natural Language Generation
Apr 12, 2019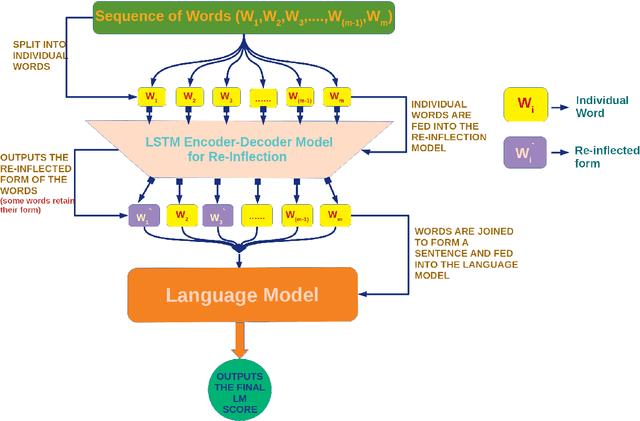
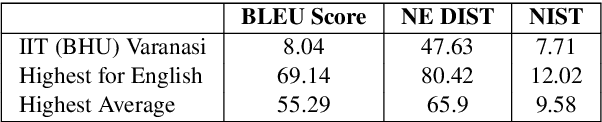
This paper describes our submission system for the Shallow Track of Surface Realization Shared Task 2018 (SRST'18). The task was to convert genuine UD structures, from which word order information had been removed and the tokens had been lemmatized, into their correct sentential form. We divide the problem statement into two parts, word reinflection and correct word order prediction. For the first sub-problem, we use a Long Short Term Memory based Encoder-Decoder approach. For the second sub-problem, we present a Language Model (LM) based approach. We apply two different sub-approaches in the LM Based approach and the combined result of these two approaches is considered as the final output of the system.
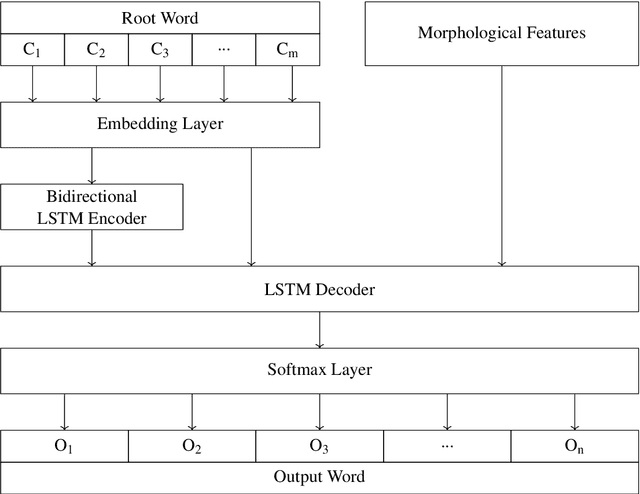
Neural Machine Translation based Word Transduction Mechanisms for Low-Resource Languages
Nov 21, 2018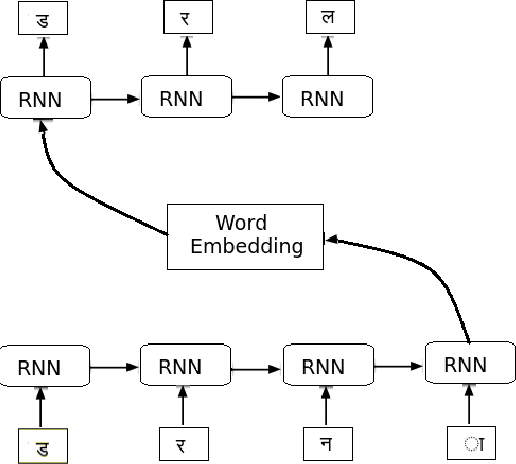


Out-Of-Vocabulary (OOV) words can pose serious challenges for machine translation (MT) tasks, and in particular, for Low-Resource Languages (LRLs). This paper adapts variants of seq2seq models to perform transduction of such words from Hindi to Bhojpuri (an LRL instance), learning from a set of cognate pairs built upon a bilingual dictionary of Hindi-Bhojpuri words. We demonstrate that our models can effectively be used for languages that have a limited amount of parallel corpora, by working at the character-level to grasp phonetic and orthographic similarities across multiple types of word adaptions, whether synchronic or diachronic, loan words or cognates. We provide a comprehensive overview over the training aspects of character-level NMT systems adapted to this task, combined with a detailed analysis of their respective error cases. Using our method, we achieve an improvement by over 6 BLEU on the Hindi-to-Bhojpuri translation task. Further, we show that such transductions generalize well to other languages by applying it successfully to Hindi-Bangla cognate pairs. Our work can be seen as an important step in the process of: (i) resolving the OOV words problem arising in MT tasks, (ii) creating effective parallel corpora for resource-constrained languages, and (iii) leveraging the enhanced semantic knowledge captured by word-level embeddings onto character-level tasks.
Multi Task Deep Morphological Analyzer: Context Aware Joint Morphological Tagging and Lemma Prediction
Nov 21, 2018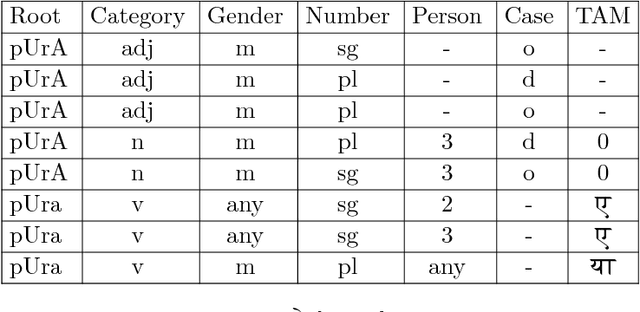
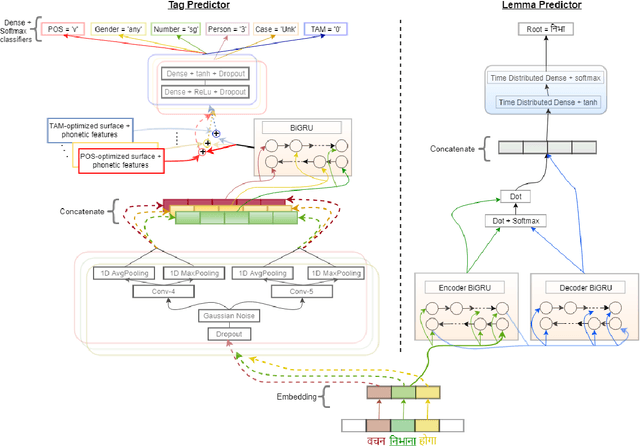
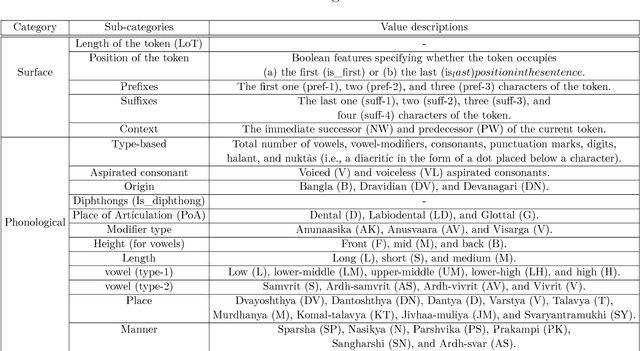
Morphological analysis is an important first step in downstream tasks like machine translation and dependency parsing of morphologically rich languages (MRLs) such as those belonging to Indo-Aryan and Dravidian families. However, the ambiguities introduced by the recombination of morphemes constructing several possible inflections for a word makes the prediction of syntactic traits a notoriously complicated task for MRLs. We propose a character-level neural morphological analyzer, the Multi Task Deep Morphological analyzer (MT-DMA), based on multitask learning of word-level tag markers for Hindi. In order to show the portability of our system to other related languages, we present results on Urdu too. MT-DMA predicts the complete set of morphological tags for words of Indo-Aryan languages: Parts-of-speech (POS), Gender (G), Number (N), Person (P), Case (C), Tense-Aspect-Modality (TAM) marker as well as the Lemma (L) by jointly learning all these in a single end-to-end framework. We show the effectiveness of training of such deep neural networks by the simultaneous optimization of multiple loss functions and sharing of initial parameters for context-aware morphological analysis. Our model outperforms the state-of-art analyzers for Hindi and Urdu. Exploring the use of a set of character-level features in phonological space optimized for each tag through a multi-objective genetic algorithm, coupled with effective training strategies, our model establishes a new state-of-the-art accuracy score upon all seven of the tasks for both the languages. MT-DMA is publicly accessible to be used at http://35.154.251.44/.
Language Identification in Code-Mixed Data using Multichannel Neural Networks and Context Capture
Aug 21, 2018

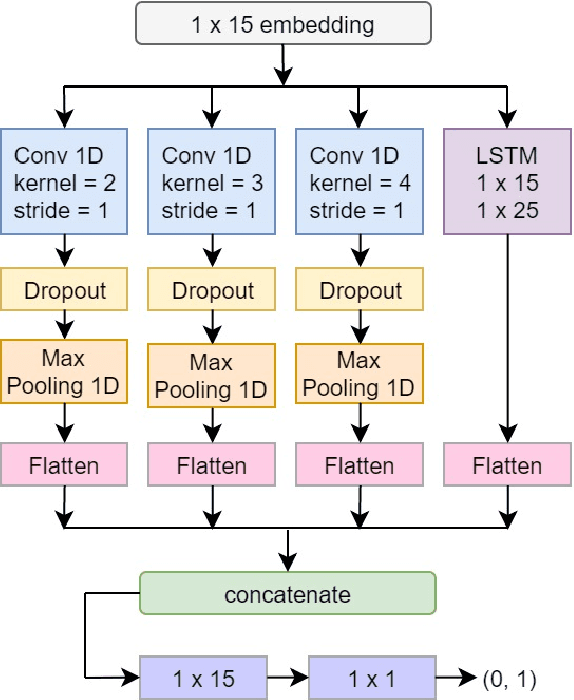
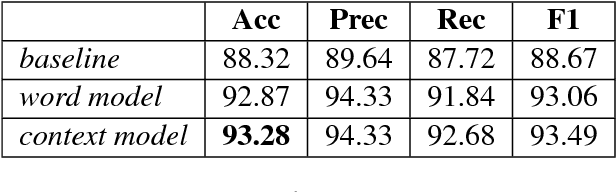
An accurate language identification tool is an absolute necessity for building complex NLP systems to be used on code-mixed data. Lot of work has been recently done on the same, but there's still room for improvement. Inspired from the recent advancements in neural network architectures for computer vision tasks, we have implemented multichannel neural networks combining CNN and LSTM for word level language identification of code-mixed data. Combining this with a Bi-LSTM-CRF context capture module, accuracies of 93.28% and 93.32% is achieved on our two testing sets.
Ethical Questions in NLP Research: The -Use of Forensic Linguistics
Dec 20, 2017Ideas from forensic linguistics are now being used frequently in Natural Language Processing (NLP), using machine learning techniques. While the role of forensic linguistics was more benign earlier, it is now being used for purposes which are questionable. Certain methods from forensic linguistics are employed, without considering their scientific limitations and ethical concerns. While we take the specific case of forensic linguistics as an example of such trends in NLP and machine learning, the issue is a larger one and present in many other scientific and data-driven domains. We suggest that such trends indicate that some of the applied sciences are exceeding their legal and scientific briefs. We highlight how carelessly implemented practices are serving to short-circuit the due processes of law as well breach ethical codes.