 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation based Word Transduction Mechanisms for Low-Resource Languages
Paper and Code
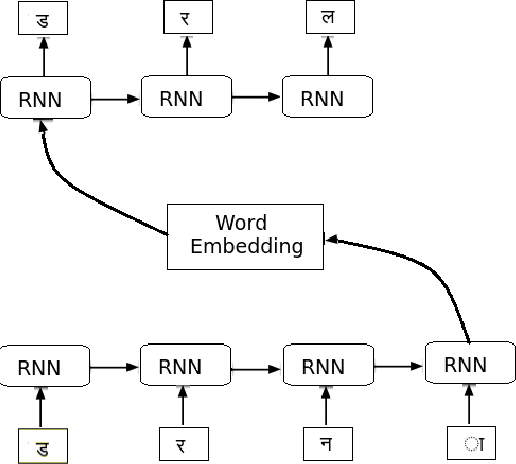


Out-Of-Vocabulary (OOV) words can pose serious challenges for machine translation (MT) tasks, and in particular, for Low-Resource Languages (LRLs). This paper adapts variants of seq2seq models to perform transduction of such words from Hindi to Bhojpuri (an LRL instance), learning from a set of cognate pairs built upon a bilingual dictionary of Hindi-Bhojpuri words. We demonstrate that our models can effectively be used for languages that have a limited amount of parallel corpora, by working at the character-level to grasp phonetic and orthographic similarities across multiple types of word adaptions, whether synchronic or diachronic, loan words or cognates. We provide a comprehensive overview over the training aspects of character-level NMT systems adapted to this task, combined with a detailed analysis of their respective error cases. Using our method, we achieve an improvement by over 6 BLEU on the Hindi-to-Bhojpuri translation task. Further, we show that such transductions generalize well to other languages by applying it successfully to Hindi-Bangla cognate pairs. Our work can be seen as an important step in the process of: (i) resolving the OOV words problem arising in MT tasks, (ii) creating effective parallel corpora for resource-constrained languages, and (iii) leveraging the enhanced semantic knowledge captured by word-level embeddings onto character-level tasks.