 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models
May 07, 2026World model-based policy evaluation is a practical proxy for testing real-world robot control by rolling out candidate actions in action-conditioned video diffusion models. As these models increasingly adopt latent diffusion modeling (LDM), choosing the right latent space becomes critical. While the status quo uses autoencoding latent spaces like VAEs that are primarily trained for pixel reconstruction, recent work suggests benefits from pretrained encoders with representation-aligned semantic latent spaces. We systematically evaluate these latent spaces for action-conditioned LDM by comparing six reconstruction and semantic encoders to train world model variants under a fixed protocol on BridgeV2 dataset, and show effective world model training in high-dimensional representation spaces with and without dimension compression. We then propose three axes to assess robotic world model performance: visual fidelity, planning and downstream policy performance, and latent representation quality. Our results show visual fidelity alone is insufficient for world model selection. While reconstruction encoders like VAE and Cosmos achieve strong pixel-level scores, semantic encoders such as V-JEPA 2.1 (strongest overall on policy), Web-DINO, and SigLIP 2 generally excel across the other two axes at all model scales. Our study advocates semantic latent space as stronger foundation for policy-relevant robotics diffusion world models.
REAM: Merging Improves Pruning of Experts in LLMs
Apr 06, 2026Mixture-of-Experts (MoE) large language models (LLMs) are among the top-performing architectures. The largest models, often with hundreds of billions of parameters, pose significant memory challenges for deployment. Traditional approaches to reduce memory requirements include weight pruning and quantization. Motivated by the Router-weighted Expert Activation Pruning (REAP) that prunes experts, we propose a novel method, Router-weighted Expert Activation Merging (REAM). Instead of removing experts, REAM groups them and merges their weights, better preserving original performance. We evaluate REAM against REAP and other baselines across multiple MoE LLMs on diverse multiple-choice (MC) question answering and generative (GEN) benchmarks. Our results reveal a trade-off between MC and GEN performance that depends on the mix of calibration data. By controlling the mix of general, math and coding data, we examine the Pareto frontier of this trade-off and show that REAM often outperforms the baselines and in many cases is comparable to the original uncompressed models.
Lightweight Structured Multimodal Reasoning for Clinical Scene Understanding in Robotics
Sep 26, 2025



Healthcare robotics requires robust multimodal perception and reasoning to ensure safety in dynamic clinical environments. Current Vision-Language Models (VLMs) demonstrate strong general-purpose capabilities but remain limited in temporal reasoning, uncertainty estimation, and structured outputs needed for robotic planning. We present a lightweight agentic multimodal framework for video-based scene understanding. Combining the Qwen2.5-VL-3B-Instruct model with a SmolAgent-based orchestration layer, it supports chain-of-thought reasoning, speech-vision fusion, and dynamic tool invocation. The framework generates structured scene graphs and leverages a hybrid retrieval module for interpretable and adaptive reasoning. Evaluations on the Video-MME benchmark and a custom clinical dataset show competitive accuracy and improved robustness compared to state-of-the-art VLMs, demonstrating its potential for applications in robot-assisted surgery, patient monitoring, and decision support.
GLOV: Guided Large Language Models as Implicit Optimizers for Vision Language Models
Oct 08, 2024



In this work, we propose a novel method (GLOV) enabling Large Language Models (LLMs) to act as implicit Optimizers for Vision-Langugage Models (VLMs) to enhance downstream vision tasks. Our GLOV meta-prompts an LLM with the downstream task description, querying it for suitable VLM prompts (e.g., for zero-shot classification with CLIP). These prompts are ranked according to a purity measure obtained through a fitness function. In each respective optimization step, the ranked prompts are fed as in-context examples (with their accuracies) to equip the LLM with the knowledge of the type of text prompts preferred by the downstream VLM. Furthermore, we also explicitly steer the LLM generation process in each optimization step by specifically adding an offset difference vector of the embeddings from the positive and negative solutions found by the LLM, in previous optimization steps, to the intermediate layer of the network for the next generation step. This offset vector steers the LLM generation toward the type of language preferred by the downstream VLM, resulting in enhanced performance on the downstream vision tasks. We comprehensively evaluate our GLOV on 16 diverse datasets using two families of VLMs, i.e., dual-encoder (e.g., CLIP) and encoder-decoder (e.g., LLaVa) models -- showing that the discovered solutions can enhance the recognition performance by up to 15.0% and 57.5% (3.8% and 21.6% on average) for these models.
Mining Your Own Secrets: Diffusion Classifier Scores for Continual Personalization of Text-to-Image Diffusion Models
Oct 02, 2024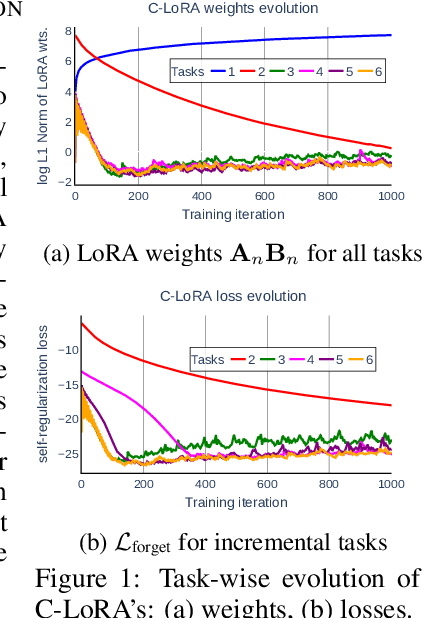
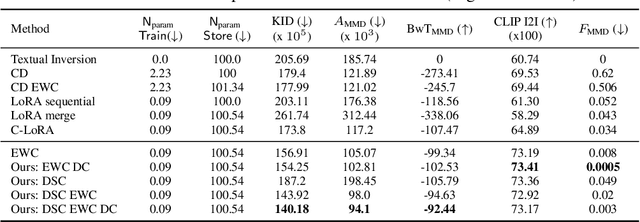
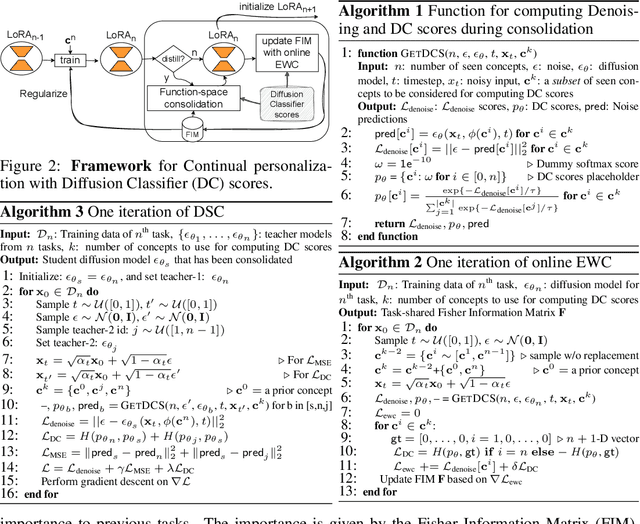
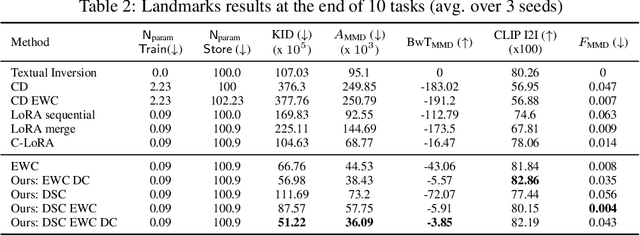
Personalized text-to-image diffusion models have grown popular for their ability to efficiently acquire a new concept from user-defined text descriptions and a few images. However, in the real world, a user may wish to personalize a model on multiple concepts but one at a time, with no access to the data from previous concepts due to storage/privacy concerns. When faced with this continual learning (CL) setup, most personalization methods fail to find a balance between acquiring new concepts and retaining previous ones -- a challenge that continual personalization (CP) aims to solve. Inspired by the successful CL methods that rely on class-specific information for regularization, we resort to the inherent class-conditioned density estimates, also known as diffusion classifier (DC) scores, for continual personalization of text-to-image diffusion models. Namely, we propose using DC scores for regularizing the parameter-space and function-space of text-to-image diffusion models, to achieve continual personalization. Using several diverse evaluation setups, datasets, and metrics, we show that our proposed regularization-based CP methods outperform the state-of-the-art C-LoRA, and other baselines. Finally, by operating in the replay-free CL setup and on low-rank adapters, our method incurs zero storage and parameter overhead, respectively, over the state-of-the-art.
On the relevance of pre-neural approaches in natural language processing pedagogy
May 16, 2024

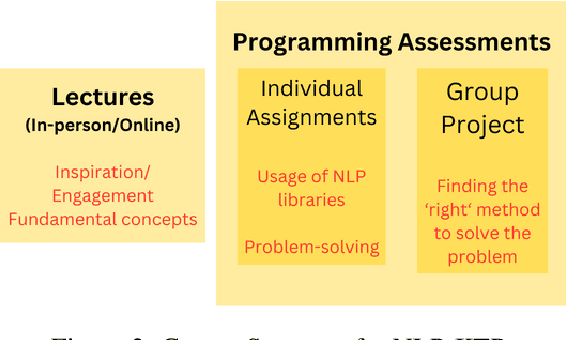

While neural approaches using deep learning are the state-of-the-art for natural language processing (NLP) today, pre-neural algorithms and approaches still find a place in NLP textbooks and courses of recent years. In this paper, we compare two introductory NLP courses taught in Australia and India, and examine how Transformer and pre-neural approaches are balanced within the lecture plan and assessments of the courses. We also draw parallels with the objects-first and objects-later debate in CS1 education. We observe that pre-neural approaches add value to student learning by building an intuitive understanding of NLP problems, potential solutions and even Transformer-based models themselves. Despite pre-neural approaches not being state-of-the-art, the paper makes a case for their inclusion in NLP courses today.
CLAP4CLIP: Continual Learning with Probabilistic Finetuning for Vision-Language Models
Mar 28, 2024



Continual learning (CL) aims to help deep neural networks to learn new knowledge while retaining what has been learned. Recently, pre-trained vision-language models such as CLIP, with powerful generalization ability, have been gaining traction as practical CL candidates. However, the domain mismatch between the pre-training and the downstream CL tasks calls for finetuning of the CLIP on the latter. The deterministic nature of the existing finetuning methods makes them overlook the many possible interactions across the modalities and deems them unsafe for high-risk CL tasks requiring reliable uncertainty estimation. To address these, our work proposes Continual LeArning with Probabilistic finetuning (CLAP). CLAP develops probabilistic modeling over task-specific modules with visual-guided text features, providing more reliable fine-tuning in CL. It further alleviates forgetting by exploiting the rich pre-trained knowledge of CLIP for weight initialization and distribution regularization of task-specific modules. Cooperating with the diverse range of existing prompting methods, CLAP can surpass the predominant deterministic finetuning approaches for CL with CLIP. Lastly, we study the superior uncertainty estimation abilities of CLAP for novel data detection and exemplar selection within CL setups. Our code is available at \url{https://github.com/srvCodes/clap4clip}.
NPCL: Neural Processes for Uncertainty-Aware Continual Learning
Oct 30, 2023


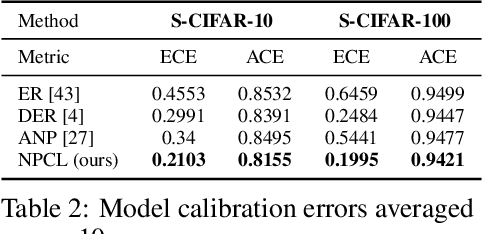
Continual learning (CL) aims to train deep neural networks efficiently on streaming data while limiting the forgetting caused by new tasks. However, learning transferable knowledge with less interference between tasks is difficult, and real-world deployment of CL models is limited by their inability to measure predictive uncertainties. To address these issues, we propose handling CL tasks with neural processes (NPs), a class of meta-learners that encode different tasks into probabilistic distributions over functions all while providing reliable uncertainty estimates. Specifically, we propose an NP-based CL approach (NPCL) with task-specific modules arranged in a hierarchical latent variable model. We tailor regularizers on the learned latent distributions to alleviate forgetting. The uncertainty estimation capabilities of the NPCL can also be used to handle the task head/module inference challenge in CL. Our experiments show that the NPCL outperforms previous CL approaches. We validate the effectiveness of uncertainty estimation in the NPCL for identifying novel data and evaluating instance-level model confidence. Code is available at \url{https://github.com/srvCodes/NPCL}.
Distilled Reverse Attention Network for Open-world Compositional Zero-Shot Learning
Mar 01, 2023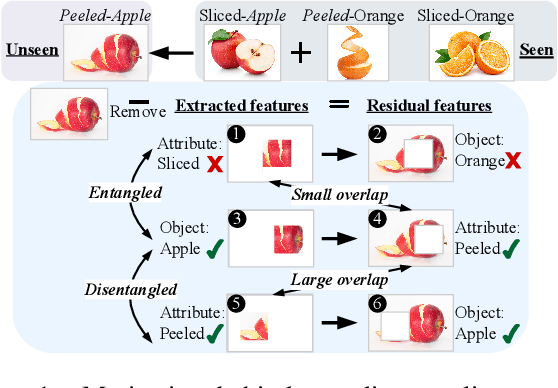
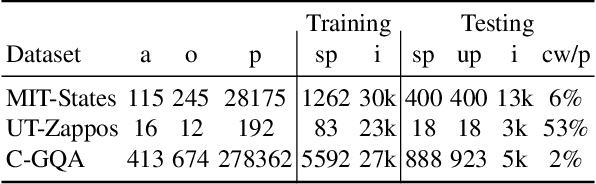


Open-World Compositional Zero-Shot Learning (OW-CZSL) aims to recognize new compositions of seen attributes and objects. In OW-CZSL, methods built on the conventional closed-world setting degrade severely due to the unconstrained OW test space. While previous works alleviate the issue by pruning compositions according to external knowledge or correlations in seen pairs, they introduce biases that harm the generalization. Some methods thus predict state and object with independently constructed and trained classifiers, ignoring that attributes are highly context-dependent and visually entangled with objects. In this paper, we propose a novel Distilled Reverse Attention Network to address the challenges. We also model attributes and objects separately but with different motivations, capturing contextuality and locality, respectively. We further design a reverse-and-distill strategy that learns disentangled representations of elementary components in training data supervised by reverse attention and knowledge distillation. We conduct experiments on three datasets and consistently achieve state-of-the-art (SOTA) performance.
Towards Exemplar-Free Continual Learning in Vision Transformers: an Account of Attention, Functional and Weight Regularization
Mar 28, 2022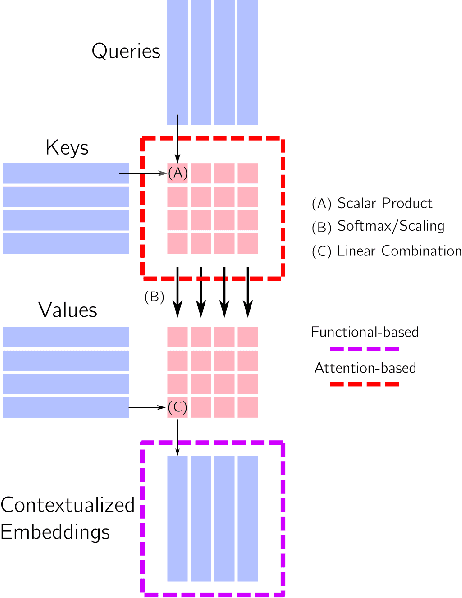
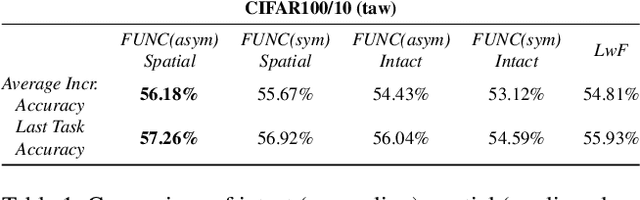
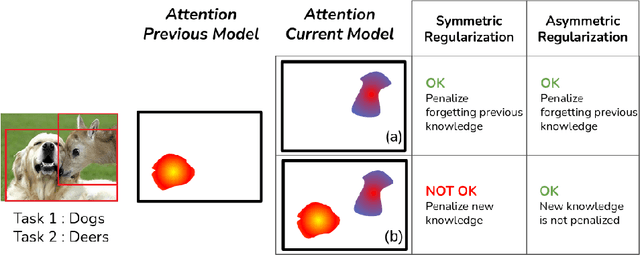
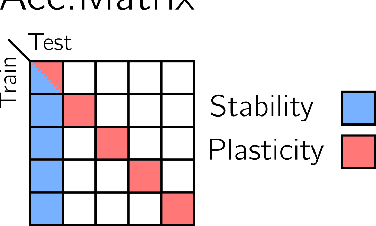
In this paper, we investigate the continual learning of Vision Transformers (ViT) for the challenging exemplar-free scenario, with special focus on how to efficiently distill the knowledge of its crucial self-attention mechanism (SAM). Our work takes an initial step towards a surgical investigation of SAM for designing coherent continual learning methods in ViTs. We first carry out an evaluation of established continual learning regularization techniques. We then examine the effect of regularization when applied to two key enablers of SAM: (a) the contextualized embedding layers, for their ability to capture well-scaled representations with respect to the values, and (b) the prescaled attention maps, for carrying value-independent global contextual information. We depict the perks of each distilling strategy on two image recognition benchmarks (CIFAR100 and ImageNet-32) -- while (a) leads to a better overall accuracy, (b) helps enhance the rigidity by maintaining competitive performances. Furthermore, we identify the limitation imposed by the symmetric nature of regularization losses. To alleviate this, we propose an asymmetric variant and apply it to the pooled output distillation (POD) loss adapted for ViTs. Our experiments confirm that introducing asymmetry to POD boosts its plasticity while retaining stability across (a) and (b). Moreover, we acknowledge low forgetting measures for all the compared methods, indicating that ViTs might be naturally inclined continual learner