 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Negation Is a Geometry Problem in Vision-Language Models
Mar 20, 2026Joint Vision-Language Embedding models such as CLIP typically fail at understanding negation in text queries - for example, failing to distinguish "no" in the query: "a plain blue shirt with no logos". Prior work has largely addressed this limitation through data-centric approaches, fine-tuning CLIP on large-scale synthetic negation datasets. However, these efforts are commonly evaluated using retrieval-based metrics that cannot reliably reflect whether negation is actually understood. In this paper, we identify two key limitations of such evaluation metrics and investigate an alternative evaluation framework based on Multimodal LLMs-as-a-judge, which typically excel at understanding simple yes/no questions about image content, providing a fair evaluation of negation understanding in CLIP models. We then ask whether there already exists a direction in the CLIP embedding space associated with negation. We find evidence that such a direction exists, and show that it can be manipulated through test-time intervention via representation engineering to steer CLIP toward negation-aware behavior without any fine-tuning. Finally, we test negation understanding on non-common image-text samples to evaluate generalization under distribution shifts.
How Do Training Methods Influence the Utilization of Vision Models?
Oct 18, 2024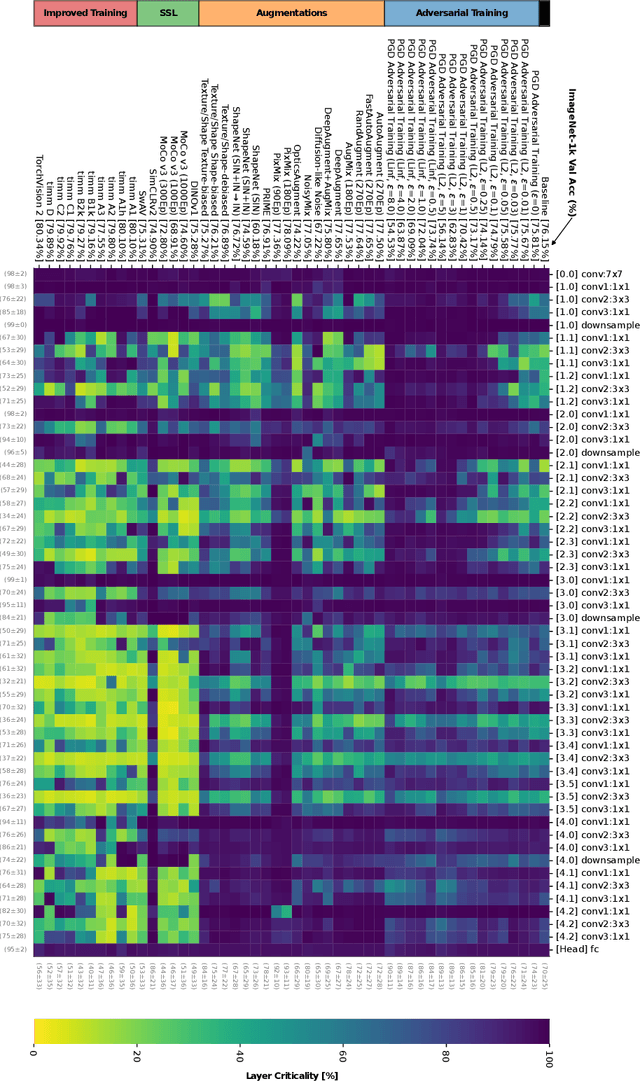

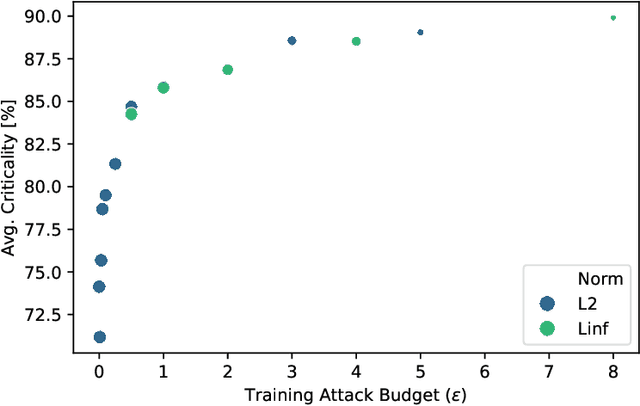

Not all learnable parameters (e.g., weights) contribute equally to a neural network's decision function. In fact, entire layers' parameters can sometimes be reset to random values with little to no impact on the model's decisions. We revisit earlier studies that examined how architecture and task complexity influence this phenomenon and ask: is this phenomenon also affected by how we train the model? We conducted experimental evaluations on a diverse set of ImageNet-1k classification models to explore this, keeping the architecture and training data constant but varying the training pipeline. Our findings reveal that the training method strongly influences which layers become critical to the decision function for a given task. For example, improved training regimes and self-supervised training increase the importance of early layers while significantly under-utilizing deeper layers. In contrast, methods such as adversarial training display an opposite trend. Our preliminary results extend previous findings, offering a more nuanced understanding of the inner mechanics of neural networks. Code: https://github.com/paulgavrikov/layer_criticality
GLOV: Guided Large Language Models as Implicit Optimizers for Vision Language Models
Oct 08, 2024



In this work, we propose a novel method (GLOV) enabling Large Language Models (LLMs) to act as implicit Optimizers for Vision-Langugage Models (VLMs) to enhance downstream vision tasks. Our GLOV meta-prompts an LLM with the downstream task description, querying it for suitable VLM prompts (e.g., for zero-shot classification with CLIP). These prompts are ranked according to a purity measure obtained through a fitness function. In each respective optimization step, the ranked prompts are fed as in-context examples (with their accuracies) to equip the LLM with the knowledge of the type of text prompts preferred by the downstream VLM. Furthermore, we also explicitly steer the LLM generation process in each optimization step by specifically adding an offset difference vector of the embeddings from the positive and negative solutions found by the LLM, in previous optimization steps, to the intermediate layer of the network for the next generation step. This offset vector steers the LLM generation toward the type of language preferred by the downstream VLM, resulting in enhanced performance on the downstream vision tasks. We comprehensively evaluate our GLOV on 16 diverse datasets using two families of VLMs, i.e., dual-encoder (e.g., CLIP) and encoder-decoder (e.g., LLaVa) models -- showing that the discovered solutions can enhance the recognition performance by up to 15.0% and 57.5% (3.8% and 21.6% on average) for these models.
Can Biases in ImageNet Models Explain Generalization?
Apr 01, 2024The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
Mar 14, 2024



Vision language models (VLMs) have drastically changed the computer vision model landscape in only a few years, opening an exciting array of new applications from zero-shot image classification, over to image captioning, and visual question answering. Unlike pure vision models, they offer an intuitive way to access visual content through language prompting. The wide applicability of such models encourages us to ask whether they also align with human vision - specifically, how far they adopt human-induced visual biases through multimodal fusion, or whether they simply inherit biases from pure vision models. One important visual bias is the texture vs. shape bias, or the dominance of local over global information. In this paper, we study this bias in a wide range of popular VLMs. Interestingly, we find that VLMs are often more shape-biased than their vision encoders, indicating that visual biases are modulated to some extent through text in multimodal models. If text does indeed influence visual biases, this suggests that we may be able to steer visual biases not just through visual input but also through language: a hypothesis that we confirm through extensive experiments. For instance, we are able to steer shape bias from as low as 49% to as high as 72% through prompting alone. For now, the strong human bias towards shape (96%) remains out of reach for all tested VLMs.
Don't Look into the Sun: Adversarial Solarization Attacks on Image Classifiers
Aug 24, 2023



Assessing the robustness of deep neural networks against out-of-distribution inputs is crucial, especially in safety-critical domains like autonomous driving, but also in safety systems where malicious actors can digitally alter inputs to circumvent safety guards. However, designing effective out-of-distribution tests that encompass all possible scenarios while preserving accurate label information is a challenging task. Existing methodologies often entail a compromise between variety and constraint levels for attacks and sometimes even both. In a first step towards a more holistic robustness evaluation of image classification models, we introduce an attack method based on image solarization that is conceptually straightforward yet avoids jeopardizing the global structure of natural images independent of the intensity. Through comprehensive evaluations of multiple ImageNet models, we demonstrate the attack's capacity to degrade accuracy significantly, provided it is not integrated into the training augmentations. Interestingly, even then, no full immunity to accuracy deterioration is achieved. In other settings, the attack can often be simplified into a black-box attack with model-independent parameters. Defenses against other corruptions do not consistently extend to be effective against our specific attack. Project website: https://github.com/paulgavrikov/adversarial_solarization
On the Interplay of Convolutional Padding and Adversarial Robustness
Aug 12, 2023



It is common practice to apply padding prior to convolution operations to preserve the resolution of feature-maps in Convolutional Neural Networks (CNN). While many alternatives exist, this is often achieved by adding a border of zeros around the inputs. In this work, we show that adversarial attacks often result in perturbation anomalies at the image boundaries, which are the areas where padding is used. Consequently, we aim to provide an analysis of the interplay between padding and adversarial attacks and seek an answer to the question of how different padding modes (or their absence) affect adversarial robustness in various scenarios.
An Extended Study of Human-like Behavior under Adversarial Training
Mar 22, 2023Neural networks have a number of shortcomings. Amongst the severest ones is the sensitivity to distribution shifts which allows models to be easily fooled into wrong predictions by small perturbations to inputs that are often imperceivable to humans and do not have to carry semantic meaning. Adversarial training poses a partial solution to address this issue by training models on worst-case perturbations. Yet, recent work has also pointed out that the reasoning in neural networks is different from humans. Humans identify objects by shape, while neural nets mainly employ texture cues. Exemplarily, a model trained on photographs will likely fail to generalize to datasets containing sketches. Interestingly, it was also shown that adversarial training seems to favorably increase the shift toward shape bias. In this work, we revisit this observation and provide an extensive analysis of this effect on various architectures, the common $\ell_2$- and $\ell_\infty$-training, and Transformer-based models. Further, we provide a possible explanation for this phenomenon from a frequency perspective.
Rethinking 1x1 Convolutions: Can we train CNNs with Frozen Random Filters?
Jan 26, 2023Modern CNNs are learning the weights of vast numbers of convolutional operators. In this paper, we raise the fundamental question if this is actually necessary. We show that even in the extreme case of only randomly initializing and never updating spatial filters, certain CNN architectures can be trained to surpass the accuracy of standard training. By reinterpreting the notion of pointwise ($1\times 1$) convolutions as an operator to learn linear combinations (LC) of frozen (random) spatial filters, we are able to analyze these effects and propose a generic LC convolution block that allows tuning of the linear combination rate. Empirically, we show that this approach not only allows us to reach high test accuracies on CIFAR and ImageNet but also has favorable properties regarding model robustness, generalization, sparsity, and the total number of necessary weights. Additionally, we propose a novel weight sharing mechanism, which allows sharing of a single weight tensor between all spatial convolution layers to massively reduce the number of weights.
Does Medical Imaging learn different Convolution Filters?
Oct 25, 2022


Recent work has investigated the distributions of learned convolution filters through a large-scale study containing hundreds of heterogeneous image models. Surprisingly, on average, the distributions only show minor drifts in comparisons of various studied dimensions including the learned task, image domain, or dataset. However, among the studied image domains, medical imaging models appeared to show significant outliers through "spikey" distributions, and, therefore, learn clusters of highly specific filters different from other domains. Following this observation, we study the collected medical imaging models in more detail. We show that instead of fundamental differences, the outliers are due to specific processing in some architectures. Quite the contrary, for standardized architectures, we find that models trained on medical data do not significantly differ in their filter distributions from similar architectures trained on data from other domains. Our conclusions reinforce previous hypotheses stating that pre-training of imaging models can be done with any kind of diverse image data.