 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Kind of Network? Review and Reference Implementation of Neural Cellular Automata
Apr 27, 2026Stephen Wolfram proclaimed in his 2003 seminal work "A New Kind Of Science" that simple recursive programs in the form of Cellular Automata (CA) are a promising approach to replace currently used mathematical formalizations, e.g. differential equations, to improve the modeling of complex systems. Over two decades later, while Cellular Automata have still been waiting for a substantial breakthrough in scientific applications, recent research showed new and promising approaches which combine Wolfram's ideas with learnable Artificial Neural Networks: So-called Neural Cellular Automata (NCA) are able to learn the complex update rules of CA from data samples, allowing them to model complex, self-organizing generative systems. The aim of this paper is to review the existing work on NCA and provide a unified modular framework and notation, as well as a reference implementation in the open-source library NCAtorch.
Benchmarking PDF Parsers on Table Extraction with LLM-based Semantic Evaluation
Mar 19, 2026Reliably extracting tables from PDFs is essential for large-scale scientific data mining and knowledge base construction, yet existing evaluation approaches rely on rule-based metrics that fail to capture semantic equivalence of table content. We present a benchmarking framework based on synthetically generated PDFs with precise LaTeX ground truth, using tables sourced from arXiv to ensure realistic complexity and diversity. As our central methodological contribution, we apply LLM-as-a-judge for semantic table evaluation, integrated into a matching pipeline that accommodates inconsistencies in parser outputs. Through a human validation study comprising over 1,500 quality judgments on extracted table pairs, we show that LLM-based evaluation achieves substantially higher correlation with human judgment (Pearson r=0.93) compared to Tree Edit Distance-based Similarity (TEDS, r=0.68) and Grid Table Similarity (GriTS, r=0.70). Evaluating 21 contemporary PDF parsers across 100 synthetic documents containing 451 tables reveals significant performance disparities. Our results offer practical guidance for selecting parsers for tabular data extraction and establish a reproducible, scalable evaluation methodology for this critical task. Code and data: https://github.com/phorn1/pdf-parse-bench Metric study and human evaluation: https://github.com/phorn1/table-metric-study
In-Context Learning for Seismic Data Processing
Dec 19, 2025Seismic processing transforms raw data into subsurface images essential for geophysical applications. Traditional methods face challenges, such as noisy data, and manual parameter tuning, among others. Recently deep learning approaches have proposed alternative solutions to some of these problems. However, important challenges of existing deep learning approaches are spatially inconsistent results across neighboring seismic gathers and lack of user-control. We address these limitations by introducing ContextSeisNet, an in-context learning model, to seismic demultiple processing. Our approach conditions predictions on a support set of spatially related example pairs: neighboring common-depth point gathers from the same seismic line and their corresponding labels. This allows the model to learn task-specific processing behavior at inference time by observing how similar gathers should be processed, without any retraining. This method provides both flexibility through user-defined examples and improved lateral consistency across seismic lines. On synthetic data, ContextSeisNet outperforms a U-Net baseline quantitatively and demonstrates enhanced spatial coherence between neighboring gathers. On field data, our model achieves superior lateral consistency compared to both traditional Radon demultiple and the U-Net baseline. Relative to the U-Net, ContextSeisNet also delivers improved near-offset performance and more complete multiple removal. Notably, ContextSeisNet achieves comparable field data performance despite being trained on 90% less data, demonstrating substantial data efficiency. These results establish ContextSeisNet as a practical approach for spatially consistent seismic demultiple with potential applicability to other seismic processing tasks.
Benchmarking Document Parsers on Mathematical Formula Extraction from PDFs
Dec 10, 2025


Correctly parsing mathematical formulas from PDFs is critical for training large language models and building scientific knowledge bases from academic literature, yet existing benchmarks either exclude formulas entirely or lack semantically-aware evaluation metrics. We introduce a novel benchmarking framework centered on synthetically generated PDFs with precise LaTeX ground truth, enabling systematic control over layout, formulas, and content characteristics. A key methodological contribution is pioneering LLM-as-a-judge for semantic formula assessment, combined with a robust two-stage matching pipeline that handles parser output inconsistencies. Through human validation on 250 formula pairs (750 ratings from 30 evaluators), we demonstrate that LLM-based evaluation achieves substantially higher correlation with human judgment (Pearson r=0.78) compared to CDM (r=0.34) and text similarity (r~0). Evaluating 20+ contemporary PDF parsers (including specialized OCR models, vision-language models, and rule-based approaches) across 100 synthetic documents with 2,000+ formulas reveals significant performance disparities. Our findings provide crucial insights for practitioners selecting parsers for downstream applications and establish a robust, scalable methodology that enables reproducible evaluation of PDF formula extraction quality. Code and benchmark data: https://github.com/phorn1/pdf-parse-bench
Real-time Prediction of Urban Sound Propagation with Conditioned Normalizing Flows
Oct 06, 2025Accurate and fast urban noise prediction is pivotal for public health and for regulatory workflows in cities, where the Environmental Noise Directive mandates regular strategic noise maps and action plans, often needed in permission workflows, right-of-way allocation, and construction scheduling. Physics-based solvers are too slow for such time-critical, iterative "what-if" studies. We evaluate conditional Normalizing Flows (Full-Glow) for generating for generating standards-compliant urban sound-pressure maps from 2D urban layouts in real time per 256x256 map on a single RTX 4090), enabling interactive exploration directly on commodity hardware. On datasets covering Baseline, Diffraction, and Reflection regimes, our model accelerates map generation by >2000 times over a reference solver while improving NLoS accuracy by up to 24% versus prior deep models; in Baseline NLoS we reach 0.65 dB MAE with high structural fidelity. The model reproduces diffraction and interference patterns and supports instant recomputation under source or geometry changes, making it a practical engine for urban planning, compliance mapping, and operations (e.g., temporary road closures, night-work variance assessments).
Assessing Foundation Models for Mold Colony Detection with Limited Training Data
Oct 01, 2025The process of quantifying mold colonies on Petri dish samples is of critical importance for the assessment of indoor air quality, as high colony counts can indicate potential health risks and deficiencies in ventilation systems. Conventionally the automation of such a labor-intensive process, as well as other tasks in microbiology, relies on the manual annotation of large datasets and the subsequent extensive training of models like YoloV9. To demonstrate that exhaustive annotation is not a prerequisite anymore when tackling a new vision task, we compile a representative dataset of 5000 Petri dish images annotated with bounding boxes, simulating both a traditional data collection approach as well as few-shot and low-shot scenarios with well curated subsets with instance level masks. We benchmark three vision foundation models against traditional baselines on task specific metrics, reflecting realistic real-world requirements. Notably, MaskDINO attains near-parity with an extensively trained YoloV9 model while finetuned only on 150 images, retaining competitive performance with as few as 25 images, still being reliable on $\approx$ 70% of the samples. Our results show that data-efficient foundation models can match traditional approaches with only a fraction of the required data, enabling earlier development and faster iterative improvement of automated microbiological systems with a superior upper-bound performance than traditional models would achieve.
A Visual RAG Pipeline for Few-Shot Fine-Grained Product Classification
Apr 16, 2025Despite the rapid evolution of learning and computer vision algorithms, Fine-Grained Classification (FGC) still poses an open problem in many practically relevant applications. In the retail domain, for example, the identification of fast changing and visually highly similar products and their properties are key to automated price-monitoring and product recommendation. This paper presents a novel Visual RAG pipeline that combines the Retrieval Augmented Generation (RAG) approach and Vision Language Models (VLMs) for few-shot FGC. This Visual RAG pipeline extracts product and promotion data in advertisement leaflets from various retailers and simultaneously predicts fine-grained product ids along with price and discount information. Compared to previous approaches, the key characteristic of the Visual RAG pipeline is that it allows the prediction of novel products without re-training, simply by adding a few class samples to the RAG database. Comparing several VLM back-ends like GPT-4o [23], GPT-4o-mini [24], and Gemini 2.0 Flash [10], our approach achieves 86.8% accuracy on a diverse dataset.
Foundation Models For Seismic Data Processing: An Extensive Review
Mar 31, 2025
Seismic processing plays a crucial role in transforming raw data into high-quality subsurface images, pivotal for various geoscience applications. Despite its importance, traditional seismic processing techniques face challenges such as noisy and damaged data and the reliance on manual, time-consuming workflows. The emergence of deep learning approaches has introduced effective and user-friendly alternatives, yet many of these deep learning approaches rely on synthetic datasets and specialized neural networks. Recently, foundation models have gained traction in the seismic domain, due to their success in natural imaging. This paper investigates the application of foundation models in seismic processing on the tasks: demultiple, interpolation, and denoising. It evaluates the impact of different model characteristics, such as pre-training technique and neural network architecture, on performance and efficiency. Rather than proposing a single seismic foundation model, this paper critically examines various natural image foundation models and suggest some promising candidates for future exploration.
PhysicsGen: Can Generative Models Learn from Images to Predict Complex Physical Relations?
Mar 07, 2025
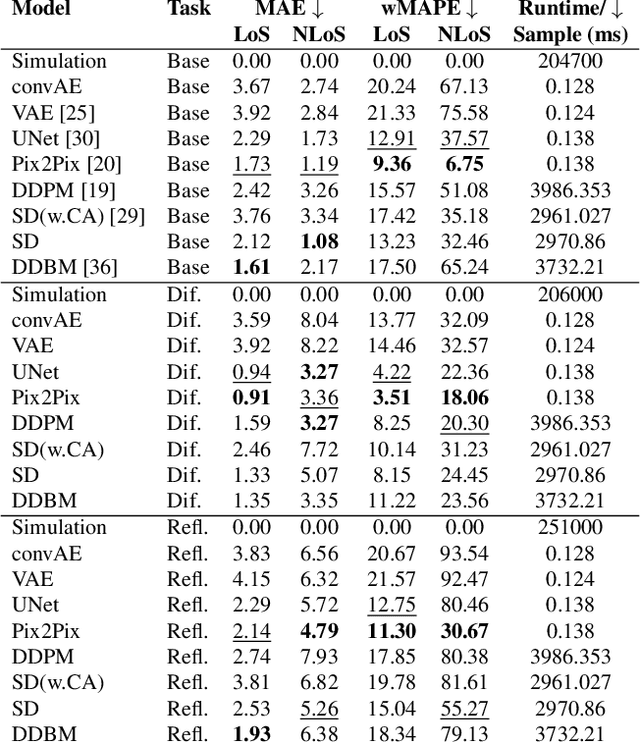
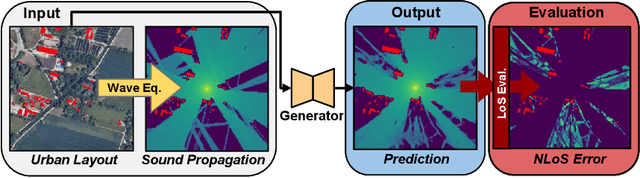

The image-to-image translation abilities of generative learning models have recently made significant progress in the estimation of complex (steered) mappings between image distributions. While appearance based tasks like image in-painting or style transfer have been studied at length, we propose to investigate the potential of generative models in the context of physical simulations. Providing a dataset of 300k image-pairs and baseline evaluations for three different physical simulation tasks, we propose a benchmark to investigate the following research questions: i) are generative models able to learn complex physical relations from input-output image pairs? ii) what speedups can be achieved by replacing differential equation based simulations? While baseline evaluations of different current models show the potential for high speedups (ii), these results also show strong limitations toward the physical correctness (i). This underlines the need for new methods to enforce physical correctness. Data, baseline models and evaluation code http://www.physics-gen.org.
Reliable Evaluation of Attribution Maps in CNNs: A Perturbation-Based Approach
Nov 22, 2024In this paper, we present an approach for evaluating attribution maps, which play a central role in interpreting the predictions of convolutional neural networks (CNNs). We show that the widely used insertion/deletion metrics are susceptible to distribution shifts that affect the reliability of the ranking. Our method proposes to replace pixel modifications with adversarial perturbations, which provides a more robust evaluation framework. By using smoothness and monotonicity measures, we illustrate the effectiveness of our approach in correcting distribution shifts. In addition, we conduct the most comprehensive quantitative and qualitative assessment of attribution maps to date. Introducing baseline attribution maps as sanity checks, we find that our metric is the only contender to pass all checks. Using Kendall's $\tau$ rank correlation coefficient, we show the increased consistency of our metric across 15 dataset-architecture combinations. Of the 16 attribution maps tested, our results clearly show SmoothGrad to be the best map currently available. This research makes an important contribution to the development of attribution maps by providing a reliable and consistent evaluation framework. To ensure reproducibility, we will provide the code along with our results.