 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-GAP: Integrating Size Priors in CNNs for more Interpretability, Robustness, and Bias Mitigation
Paper and Code
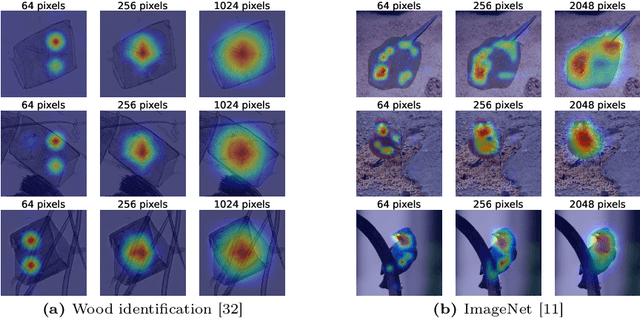



This paper introduces Top-GAP, a novel regularization technique that enhances the explainability and robustness of convolutional neural networks. By constraining the spatial size of the learned feature representation, our method forces the network to focus on the most salient image regions, effectively reducing background influence. Using adversarial attacks and the Effective Receptive Field, we show that Top-GAP directs more attention towards object pixels rather than the background. This leads to enhanced interpretability and robustness. We achieve over 50% robust accuracy on CIFAR-10 with PGD $\epsilon=\frac{8}{255}$ and $20$ iterations while maintaining the original clean accuracy. Furthermore, we see increases of up to 5% accuracy against distribution shifts. Our approach also yields more precise object localization, as evidenced by up to 25% improvement in Intersection over Union (IOU) compared to methods like GradCAM and Recipro-CAM.