 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Training Methods Influence the Utilization of Vision Models?
Paper and Code
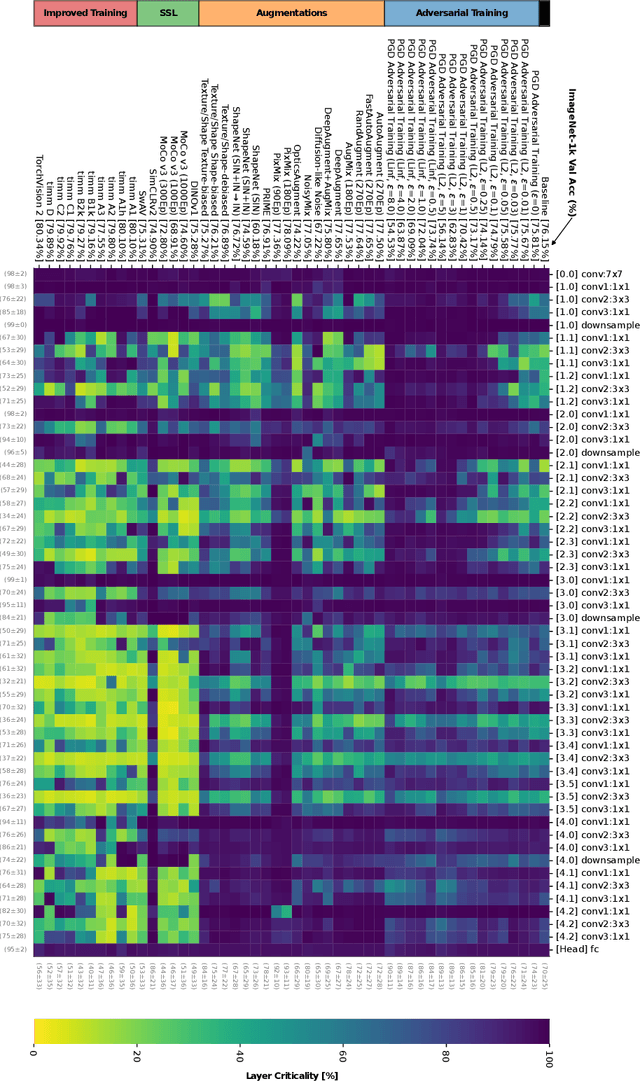

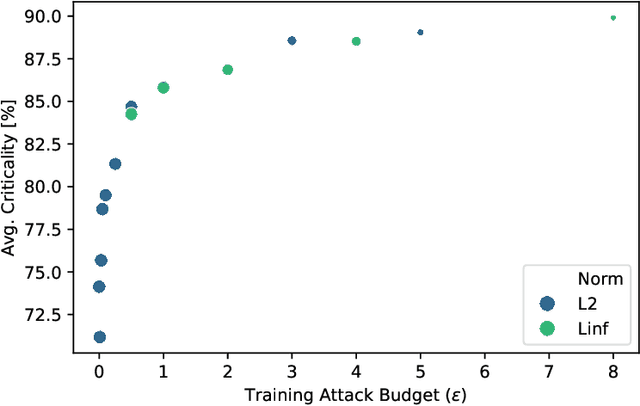

Not all learnable parameters (e.g., weights) contribute equally to a neural network's decision function. In fact, entire layers' parameters can sometimes be reset to random values with little to no impact on the model's decisions. We revisit earlier studies that examined how architecture and task complexity influence this phenomenon and ask: is this phenomenon also affected by how we train the model? We conducted experimental evaluations on a diverse set of ImageNet-1k classification models to explore this, keeping the architecture and training data constant but varying the training pipeline. Our findings reveal that the training method strongly influences which layers become critical to the decision function for a given task. For example, improved training regimes and self-supervised training increase the importance of early layers while significantly under-utilizing deeper layers. In contrast, methods such as adversarial training display an opposite trend. Our preliminary results extend previous findings, offering a more nuanced understanding of the inner mechanics of neural networks. Code: https://github.com/paulgavrikov/layer_criticality