 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImages as Tables: In-Context Learning with TabPFN for Low-Data Detection of AI-Generated Images
May 30, 2026AI-generated image detection is a moving-target problem: detectors trained on one generator often fail when a new generator appears, and only a few labeled examples are available. We study a simple image-to-table formulation for this regime, where each image is encoded by a frozen DINOv3 backbone, its CLS feature is reduced to a 500-dimensional structured row with PCA, and TabPFN performs real/fake classification by in-context tabular inference rather than task-specific classifier training. This turns fake-image detection into low-data structured prediction over learned visual features, making detector adaptation depend on the labeled context set instead of gradient-based fine-tuning. On GenImage, LATTE, a recent state-of-the-art detector, remains stronger when many labeled samples from all generators are available, by 7.4% in the largest pooled setting, but DINOv3-PCA-TabPFN is stronger in the practically important low-data regime, outperforming LATTE by up to 8.2%, and in transfer settings where the detector must generalize from one generator to another. These results position tabular foundation models as a strong complementary adaptation mechanism for image forensics, shifting adaptation from detector retraining to lightweight in-context updates with a small labeled set of examples. Code URL: https://github.com/jpwalter30/Towards-Generalizable-Detection-of-AI-Generated-Images
From Codebooks to VLMs: Evaluating Automated Visual Discourse Analysis for Climate Change on Social Media
Apr 23, 2026Social media platforms have become primary arenas for climate communication, generating millions of images and posts that - if systematically analysed - can reveal which communication strategies mobilise public concern and which fall flat. We aim to facilitate such research by analysing how computer vision methods can be used for social media discourse analysis. This analysis includes application-based taxonomy design, model selection, prompt engineering, and validation. We benchmark six promptable vision-language models and 15 zero-shot CLIP-like models on two datasets from X (formerly Twitter) - a 1,038-image expert-annotated set and a larger corpus of over 1.2 million images, with 50,000 labels manually validated - spanning five annotation dimensions: animal content, climate change consequences, climate action, image setting, and image type. Among the models benchmarked, Gemini-3.1-flash-lite outperforms all others across all super-categories and both datasets, while the gap to open-weight models of moderate size remains relatively small. Beyond instance-level metrics, we advocate for distributional evaluation: VLM predictions can reliably recover population level trends even when per-image accuracy is moderate, making them a viable starting point for discourse analysis at scale. We find that chain-of-thought reasoning reduces rather than improves performance, and that annotation dimension specific prompt design improves performance. We release tweet IDs and labels along with our code at https://github.com/KathPra/Codebooks2VLMs.git.
GeoDiv: Framework For Measuring Geographical Diversity In Text-To-Image Models
Feb 25, 2026Text-to-image (T2I) models are rapidly gaining popularity, yet their outputs often lack geographical diversity, reinforce stereotypes, and misrepresent regions. Given their broad reach, it is critical to rigorously evaluate how these models portray the world. Existing diversity metrics either rely on curated datasets or focus on surface-level visual similarity, limiting interpretability. We introduce GeoDiv, a framework leveraging large language and vision-language models to assess geographical diversity along two complementary axes: the Socio-Economic Visual Index (SEVI), capturing economic and condition-related cues, and the Visual Diversity Index (VDI), measuring variation in primary entities and backgrounds. Applied to images generated by models such as Stable Diffusion and FLUX.1-dev across $10$ entities and $16$ countries, GeoDiv reveals a consistent lack of diversity and identifies fine-grained attributes where models default to biased portrayals. Strikingly, depictions of countries like India, Nigeria, and Colombia are disproportionately impoverished and worn, reflecting underlying socio-economic biases. These results highlight the need for greater geographical nuance in generative models. GeoDiv provides the first systematic, interpretable framework for measuring such biases, marking a step toward fairer and more inclusive generative systems. Project page: https://abhipsabasu.github.io/geodiv
RAWDet-7: A Multi-Scenario Benchmark for Object Detection and Description on Quantized RAW Images
Feb 03, 2026Most vision models are trained on RGB images processed through ISP pipelines optimized for human perception, which can discard sensor-level information useful for machine reasoning. RAW images preserve unprocessed scene data, enabling models to leverage richer cues for both object detection and object description, capturing fine-grained details, spatial relationships, and contextual information often lost in processed images. To support research in this domain, we introduce RAWDet-7, a large-scale dataset of ~25k training and 7.6k test RAW images collected across diverse cameras, lighting conditions, and environments, densely annotated for seven object categories following MS-COCO and LVIS conventions. In addition, we provide object-level descriptions derived from the corresponding high-resolution sRGB images, facilitating the study of object-level information preservation under RAW image processing and low-bit quantization. The dataset allows evaluation under simulated 4-bit, 6-bit, and 8-bit quantization, reflecting realistic sensor constraints, and provides a benchmark for studying detection performance, description quality & detail, and generalization in low-bit RAW image processing. Dataset & code upon acceptance.
$γ$-Quant: Towards Learnable Quantization for Low-bit Pattern Recognition
Sep 26, 2025Most pattern recognition models are developed on pre-proce\-ssed data. In computer vision, for instance, RGB images processed through image signal processing (ISP) pipelines designed to cater to human perception are the most frequent input to image analysis networks. However, many modern vision tasks operate without a human in the loop, raising the question of whether such pre-processing is optimal for automated analysis. Similarly, human activity recognition (HAR) on body-worn sensor data commonly takes normalized floating-point data arising from a high-bit analog-to-digital converter (ADC) as an input, despite such an approach being highly inefficient in terms of data transmission, significantly affecting the battery life of wearable devices. In this work, we target low-bandwidth and energy-constrained settings where sensors are limited to low-bit-depth capture. We propose $\gamma$-Quant, i.e.~the task-specific learning of a non-linear quantization for pattern recognition. We exemplify our approach on raw-image object detection as well as HAR of wearable data, and demonstrate that raw data with a learnable quantization using as few as 4-bits can perform on par with the use of raw 12-bit data. All code to reproduce our experiments is publicly available via https://github.com/Mishalfatima/Gamma-Quant
Faithful, Interpretable Chest X-ray Diagnosis with Anti-Aliased B-cos Networks
Jul 24, 2025Faithfulness and interpretability are essential for deploying deep neural networks (DNNs) in safety-critical domains such as medical imaging. B-cos networks offer a promising solution by replacing standard linear layers with a weight-input alignment mechanism, producing inherently interpretable, class-specific explanations without post-hoc methods. While maintaining diagnostic performance competitive with state-of-the-art DNNs, standard B-cos models suffer from severe aliasing artifacts in their explanation maps, making them unsuitable for clinical use where clarity is essential. In this work, we address these limitations by introducing anti-aliasing strategies using FLCPooling (FLC) and BlurPool (BP) to significantly improve explanation quality. Our experiments on chest X-ray datasets demonstrate that the modified $\text{B-cos}_\text{FLC}$ and $\text{B-cos}_\text{BP}$ preserve strong predictive performance while providing faithful and artifact-free explanations suitable for clinical application in multi-class and multi-label settings. Code available at: GitHub repository (url: https://github.com/mkleinma/B-cos-medical-paper).
TRIX- Trading Adversarial Fairness via Mixed Adversarial Training
Jul 10, 2025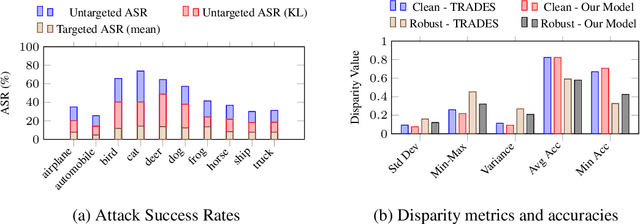
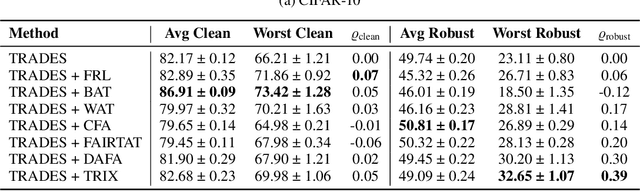
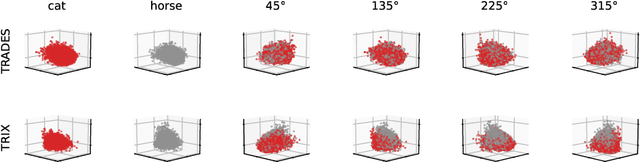
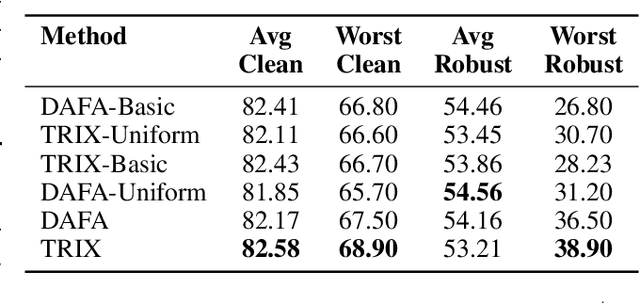
Adversarial Training (AT) is a widely adopted defense against adversarial examples. However, existing approaches typically apply a uniform training objective across all classes, overlooking disparities in class-wise vulnerability. This results in adversarial unfairness: classes with well distinguishable features (strong classes) tend to become more robust, while classes with overlapping or shared features(weak classes) remain disproportionately susceptible to adversarial attacks. We observe that strong classes do not require strong adversaries during training, as their non-robust features are quickly suppressed. In contrast, weak classes benefit from stronger adversaries to effectively reduce their vulnerabilities. Motivated by this, we introduce TRIX, a feature-aware adversarial training framework that adaptively assigns weaker targeted adversaries to strong classes, promoting feature diversity via uniformly sampled targets, and stronger untargeted adversaries to weak classes, enhancing their focused robustness. TRIX further incorporates per-class loss weighting and perturbation strength adjustments, building on prior work, to emphasize weak classes during the optimization. Comprehensive experiments on standard image classification benchmarks, including evaluations under strong attacks such as PGD and AutoAttack, demonstrate that TRIX significantly improves worst-case class accuracy on both clean and adversarial data, reducing inter-class robustness disparities, and preserves overall accuracy. Our results highlight TRIX as a practical step toward fair and effective adversarial defense.
SemSegBench & DetecBench: Benchmarking Reliability and Generalization Beyond Classification
May 23, 2025Reliability and generalization in deep learning are predominantly studied in the context of image classification. Yet, real-world applications in safety-critical domains involve a broader set of semantic tasks, such as semantic segmentation and object detection, which come with a diverse set of dedicated model architectures. To facilitate research towards robust model design in segmentation and detection, our primary objective is to provide benchmarking tools regarding robustness to distribution shifts and adversarial manipulations. We propose the benchmarking tools SEMSEGBENCH and DETECBENCH, along with the most extensive evaluation to date on the reliability and generalization of semantic segmentation and object detection models. In particular, we benchmark 76 segmentation models across four datasets and 61 object detectors across two datasets, evaluating their performance under diverse adversarial attacks and common corruptions. Our findings reveal systematic weaknesses in state-of-the-art models and uncover key trends based on architecture, backbone, and model capacity. SEMSEGBENCH and DETECBENCH are open-sourced in our GitHub repository (https://github.com/shashankskagnihotri/benchmarking_reliability_generalization) along with our complete set of total 6139 evaluations. We anticipate the collected data to foster and encourage future research towards improved model reliability beyond classification.
Informed Mixing -- Improving Open Set Recognition via Attribution-based Augmentation
May 19, 2025Open set recognition (OSR) is devised to address the problem of detecting novel classes during model inference. Even in recent vision models, this remains an open issue which is receiving increasing attention. Thereby, a crucial challenge is to learn features that are relevant for unseen categories from given data, for which these features might not be discriminative. To facilitate this process and "optimize to learn" more diverse features, we propose GradMix, a data augmentation method that dynamically leverages gradient-based attribution maps of the model during training to mask out already learned concepts. Thus GradMix encourages the model to learn a more complete set of representative features from the same data source. Extensive experiments on open set recognition, close set classification, and out-of-distribution detection reveal that our method can often outperform the state-of-the-art. GradMix can further increase model robustness to corruptions as well as downstream classification performance for self-supervised learning, indicating its benefit for model generalization.
CROC: Evaluating and Training T2I Metrics with Pseudo- and Human-Labeled Contrastive Robustness Checks
May 16, 2025The assessment of evaluation metrics (meta-evaluation) is crucial for determining the suitability of existing metrics in text-to-image (T2I) generation tasks. Human-based meta-evaluation is costly and time-intensive, and automated alternatives are scarce. We address this gap and propose CROC: a scalable framework for automated Contrastive Robustness Checks that systematically probes and quantifies metric robustness by synthesizing contrastive test cases across a comprehensive taxonomy of image properties. With CROC, we generate a pseudo-labeled dataset (CROC$^{syn}$) of over one million contrastive prompt-image pairs to enable a fine-grained comparison of evaluation metrics. We also use the dataset to train CROCScore, a new metric that achieves state-of-the-art performance among open-source methods, demonstrating an additional key application of our framework. To complement this dataset, we introduce a human-supervised benchmark (CROC$^{hum}$) targeting especially challenging categories. Our results highlight robustness issues in existing metrics: for example, many fail on prompts involving negation, and all tested open-source metrics fail on at least 25% of cases involving correct identification of body parts.