 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP is All You Need for Human-like Semantic Representations in Stable Diffusion
Nov 11, 2025Latent diffusion models such as Stable Diffusion achieve state-of-the-art results on text-to-image generation tasks. However, the extent to which these models have a semantic understanding of the images they generate is not well understood. In this work, we investigate whether the internal representations used by these models during text-to-image generation contain semantic information that is meaningful to humans. To do so, we perform probing on Stable Diffusion with simple regression layers that predict semantic attributes for objects and evaluate these predictions against human annotations. Surprisingly, we find that this success can actually be attributed to the text encoding occurring in CLIP rather than the reverse diffusion process. We demonstrate that groups of specific semantic attributes have markedly different decoding accuracy than the average, and are thus represented to different degrees. Finally, we show that attributes become more difficult to disambiguate from one another during the inverse diffusion process, further demonstrating the strongest semantic representation of object attributes in CLIP. We conclude that the separately trained CLIP vision-language model is what determines the human-like semantic representation, and that the diffusion process instead takes the role of a visual decoder.
3DFroMLLM: 3D Prototype Generation only from Pretrained Multimodal LLMs
Aug 12, 2025Recent Multi-Modal Large Language Models (MLLMs) have demonstrated strong capabilities in learning joint representations from text and images. However, their spatial reasoning remains limited. We introduce 3DFroMLLM, a novel framework that enables the generation of 3D object prototypes directly from MLLMs, including geometry and part labels. Our pipeline is agentic, comprising a designer, coder, and visual inspector operating in a refinement loop. Notably, our approach requires no additional training data or detailed user instructions. Building on prior work in 2D generation, we demonstrate that rendered images produced by our framework can be effectively used for image classification pretraining tasks and outperforms previous methods by 15%. As a compelling real-world use case, we show that the generated prototypes can be leveraged to improve fine-grained vision-language models by using the rendered, part-labeled prototypes to fine-tune CLIP for part segmentation and achieving a 55% accuracy improvement without relying on any additional human-labeled data.
Imaging for All-Day Wearable Smart Glasses
Apr 17, 2025In recent years smart glasses technology has rapidly advanced, opening up entirely new areas for mobile computing. We expect future smart glasses will need to be all-day wearable, adopting a small form factor to meet the requirements of volume, weight, fashionability and social acceptability, which puts significant constraints on the space of possible solutions. Additional challenges arise due to the fact that smart glasses are worn in arbitrary environments while their wearer moves and performs everyday activities. In this paper, we systematically analyze the space of imaging from smart glasses and derive several fundamental limits that govern this imaging domain. We discuss the impact of these limits on achievable image quality and camera module size -- comparing in particular to related devices such as mobile phones. We then propose a novel distributed imaging approach that allows to minimize the size of the individual camera modules when compared to a standard monolithic camera design. Finally, we demonstrate the properties of this novel approach in a series of experiments using synthetic data as well as images captured with two different prototype implementations.
TikZero: Zero-Shot Text-Guided Graphics Program Synthesis
Mar 14, 2025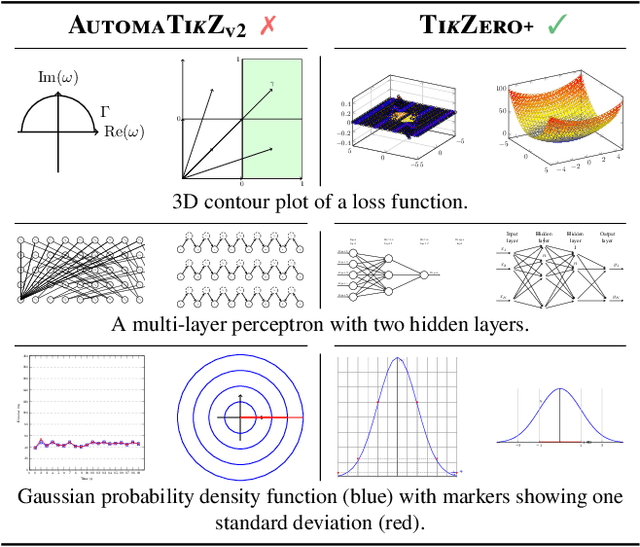
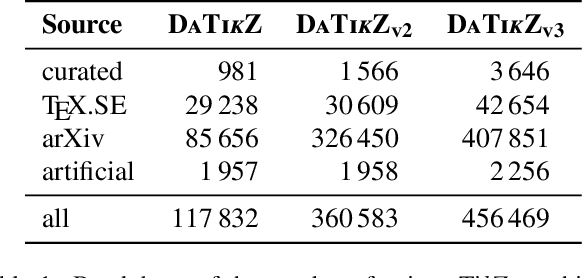
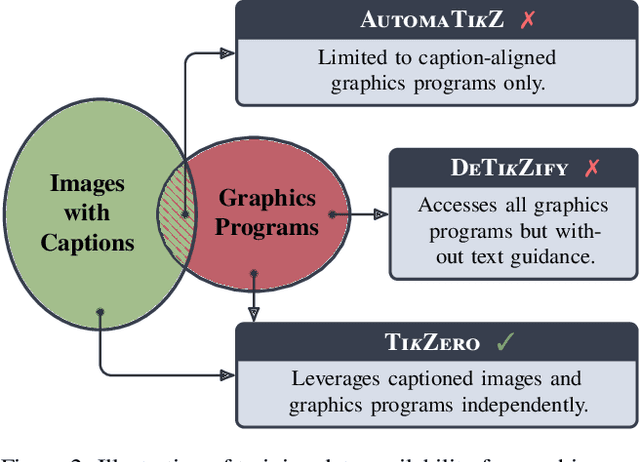

With the rise of generative AI, synthesizing figures from text captions becomes a compelling application. However, achieving high geometric precision and editability requires representing figures as graphics programs in languages like TikZ, and aligned training data (i.e., graphics programs with captions) remains scarce. Meanwhile, large amounts of unaligned graphics programs and captioned raster images are more readily available. We reconcile these disparate data sources by presenting TikZero, which decouples graphics program generation from text understanding by using image representations as an intermediary bridge. It enables independent training on graphics programs and captioned images and allows for zero-shot text-guided graphics program synthesis during inference. We show that our method substantially outperforms baselines that can only operate with caption-aligned graphics programs. Furthermore, when leveraging caption-aligned graphics programs as a complementary training signal, TikZero matches or exceeds the performance of much larger models, including commercial systems like GPT-4o. Our code, datasets, and select models are publicly available.
SLayR: Scene Layout Generation with Rectified Flow
Dec 06, 2024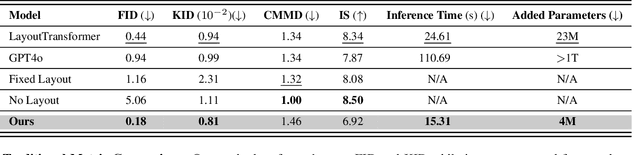
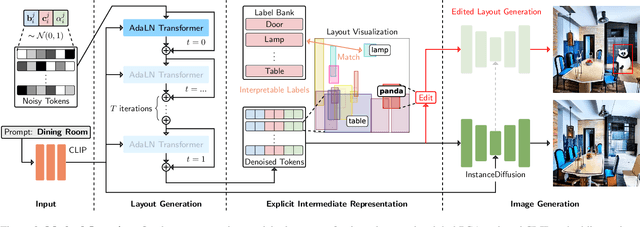
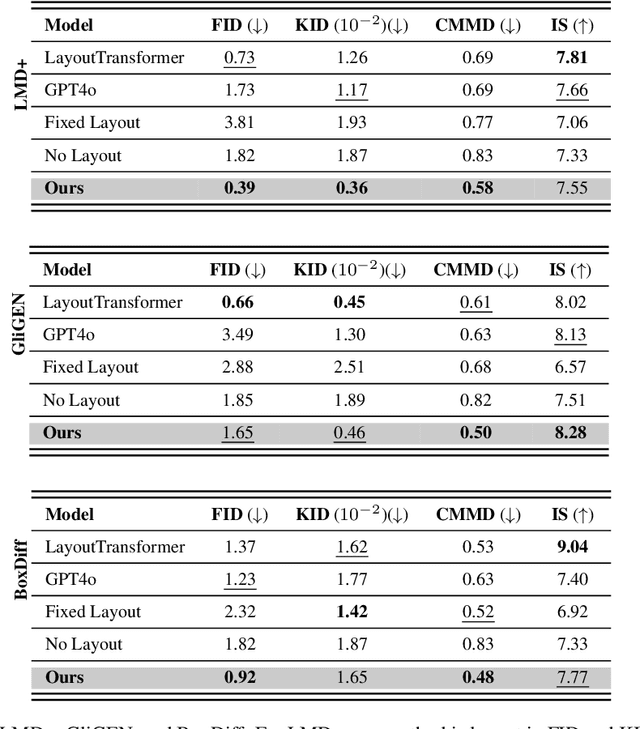
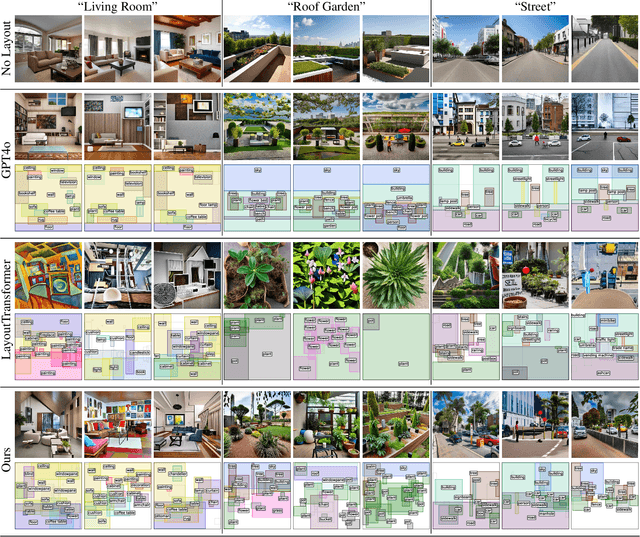
We introduce SLayR, Scene Layout Generation with Rectified flow. State-of-the-art text-to-image models achieve impressive results. However, they generate images end-to-end, exposing no fine-grained control over the process. SLayR presents a novel transformer-based rectified flow model for layout generation over a token space that can be decoded into bounding boxes and corresponding labels, which can then be transformed into images using existing models. We show that established metrics for generated images are inconclusive for evaluating their underlying scene layout, and introduce a new benchmark suite, including a carefully designed repeatable human-evaluation procedure that assesses the plausibility and variety of generated layouts. In contrast to previous works, which perform well in either high variety or plausibility, we show that our approach performs well on both of these axes at the same time. It is also at least 5x times smaller in the number of parameters and 37% faster than the baselines. Our complete text-to-image pipeline demonstrates the added benefits of an interpretable and editable intermediate representation.
Spurfies: Sparse Surface Reconstruction using Local Geometry Priors
Aug 29, 2024



We introduce Spurfies, a novel method for sparse-view surface reconstruction that disentangles appearance and geometry information to utilize local geometry priors trained on synthetic data. Recent research heavily focuses on 3D reconstruction using dense multi-view setups, typically requiring hundreds of images. However, these methods often struggle with few-view scenarios. Existing sparse-view reconstruction techniques often rely on multi-view stereo networks that need to learn joint priors for geometry and appearance from a large amount of data. In contrast, we introduce a neural point representation that disentangles geometry and appearance to train a local geometry prior using a subset of the synthetic ShapeNet dataset only. During inference, we utilize this surface prior as additional constraint for surface and appearance reconstruction from sparse input views via differentiable volume rendering, restricting the space of possible solutions. We validate the effectiveness of our method on the DTU dataset and demonstrate that it outperforms previous state of the art by 35% in surface quality while achieving competitive novel view synthesis quality. Moreover, in contrast to previous works, our method can be applied to larger, unbounded scenes, such as Mip-NeRF 360.
iNeMo: Incremental Neural Mesh Models for Robust Class-Incremental Learning
Jul 12, 2024Different from human nature, it is still common practice today for vision tasks to train deep learning models only initially and on fixed datasets. A variety of approaches have recently addressed handling continual data streams. However, extending these methods to manage out-of-distribution (OOD) scenarios has not effectively been investigated. On the other hand, it has recently been shown that non-continual neural mesh models exhibit strong performance in generalizing to such OOD scenarios. To leverage this decisive property in a continual learning setting, we propose incremental neural mesh models that can be extended with new meshes over time. In addition, we present a latent space initialization strategy that enables us to allocate feature space for future unseen classes in advance and a positional regularization term that forces the features of the different classes to consistently stay in respective latent space regions. We demonstrate the effectiveness of our method through extensive experiments on the Pascal3D and ObjectNet3D datasets and show that our approach outperforms the baselines for classification by $2-6\%$ in the in-domain and by $6-50\%$ in the OOD setting. Our work also presents the first incremental learning approach for pose estimation. Our code and model can be found at https://github.com/Fischer-Tom/iNeMo.
Unsupervised Learning of Category-Level 3D Pose from Object-Centric Videos
Jul 05, 2024



Category-level 3D pose estimation is a fundamentally important problem in computer vision and robotics, e.g. for embodied agents or to train 3D generative models. However, so far methods that estimate the category-level object pose require either large amounts of human annotations, CAD models or input from RGB-D sensors. In contrast, we tackle the problem of learning to estimate the category-level 3D pose only from casually taken object-centric videos without human supervision. We propose a two-step pipeline: First, we introduce a multi-view alignment procedure that determines canonical camera poses across videos with a novel and robust cyclic distance formulation for geometric and appearance matching using reconstructed coarse meshes and DINOv2 features. In a second step, the canonical poses and reconstructed meshes enable us to train a model for 3D pose estimation from a single image. In particular, our model learns to estimate dense correspondences between images and a prototypical 3D template by predicting, for each pixel in a 2D image, a feature vector of the corresponding vertex in the template mesh. We demonstrate that our method outperforms all baselines at the unsupervised alignment of object-centric videos by a large margin and provides faithful and robust predictions in-the-wild. Our code and data is available at https://github.com/GenIntel/uns-obj-pose3d.
Neuroexplicit Diffusion Models for Inpainting of Optical Flow Fields
May 23, 2024Deep learning has revolutionized the field of computer vision by introducing large scale neural networks with millions of parameters. Training these networks requires massive datasets and leads to intransparent models that can fail to generalize. At the other extreme, models designed from partial differential equations (PDEs) embed specialized domain knowledge into mathematical equations and usually rely on few manually chosen hyperparameters. This makes them transparent by construction and if designed and calibrated carefully, they can generalize well to unseen scenarios. In this paper, we show how to bring model- and data-driven approaches together by combining the explicit PDE-based approaches with convolutional neural networks to obtain the best of both worlds. We illustrate a joint architecture for the task of inpainting optical flow fields and show that the combination of model- and data-driven modeling leads to an effective architecture. Our model outperforms both fully explicit and fully data-driven baselines in terms of reconstruction quality, robustness and amount of required training data. Averaging the endpoint error across different mask densities, our method outperforms the explicit baselines by 11-27%, the GAN baseline by 47% and the Probabilisitic Diffusion baseline by 42%. With that, our method sets a new state of the art for inpainting of optical flow fields from random masks.
Accurate Training Data for Occupancy Map Prediction in Automated Driving Using Evidence Theory
May 17, 2024Automated driving fundamentally requires knowledge about the surrounding geometry of the scene. Modern approaches use only captured images to predict occupancy maps that represent the geometry. Training these approaches requires accurate data that may be acquired with the help of LiDAR scanners. We show that the techniques used for current benchmarks and training datasets to convert LiDAR scans into occupancy grid maps yield very low quality, and subsequently present a novel approach using evidence theory that yields more accurate reconstructions. We demonstrate that these are superior by a large margin, both qualitatively and quantitatively, and that we additionally obtain meaningful uncertainty estimates. When converting the occupancy maps back to depth estimates and comparing them with the raw LiDAR measurements, our method yields a MAE improvement of 30% to 52% on nuScenes and 53% on Waymo over other occupancy ground-truth data. Finally, we use the improved occupancy maps to train a state-of-the-art occupancy prediction method and demonstrate that it improves the MAE by 25% on nuScenes.