 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImaging for All-Day Wearable Smart Glasses
Apr 17, 2025In recent years smart glasses technology has rapidly advanced, opening up entirely new areas for mobile computing. We expect future smart glasses will need to be all-day wearable, adopting a small form factor to meet the requirements of volume, weight, fashionability and social acceptability, which puts significant constraints on the space of possible solutions. Additional challenges arise due to the fact that smart glasses are worn in arbitrary environments while their wearer moves and performs everyday activities. In this paper, we systematically analyze the space of imaging from smart glasses and derive several fundamental limits that govern this imaging domain. We discuss the impact of these limits on achievable image quality and camera module size -- comparing in particular to related devices such as mobile phones. We then propose a novel distributed imaging approach that allows to minimize the size of the individual camera modules when compared to a standard monolithic camera design. Finally, we demonstrate the properties of this novel approach in a series of experiments using synthetic data as well as images captured with two different prototype implementations.
HoloChrome: Polychromatic Illumination for Speckle Reduction in Holographic Near-Eye Displays
Oct 31, 2024Holographic displays hold the promise of providing authentic depth cues, resulting in enhanced immersive visual experiences for near-eye applications. However, current holographic displays are hindered by speckle noise, which limits accurate reproduction of color and texture in displayed images. We present HoloChrome, a polychromatic holographic display framework designed to mitigate these limitations. HoloChrome utilizes an ultrafast, wavelength-adjustable laser and a dual-Spatial Light Modulator (SLM) architecture, enabling the multiplexing of a large set of discrete wavelengths across the visible spectrum. By leveraging spatial separation in our dual-SLM setup, we independently manipulate speckle patterns across multiple wavelengths. This novel approach effectively reduces speckle noise through incoherent averaging achieved by wavelength multiplexing. Our method is complementary to existing speckle reduction techniques, offering a new pathway to address this challenge. Furthermore, the use of polychromatic illumination broadens the achievable color gamut compared to traditional three-color primary holographic displays. Our simulations and tabletop experiments validate that HoloChrome significantly reduces speckle noise and expands the color gamut. These advancements enhance the performance of holographic near-eye displays, moving us closer to practical, immersive next-generation visual experiences.
Practical High-Contrast Holography
Oct 25, 2024Holographic displays are a promising technology for immersive visual experiences, and their potential for compact form factor makes them a strong candidate for head-mounted displays. However, at the short propagation distances needed for a compact, head-mounted architecture, image contrast is low when using a traditional phase-only spatial light modulator (SLM). Although a complex SLM could restore contrast, these modulators require bulky lenses to optically co-locate the amplitude and phase components, making them poorly suited for a compact head-mounted design. In this work, we introduce a novel architecture to improve contrast: by adding a low resolution amplitude SLM a short distance away from the phase modulator, we demonstrate peak signal-to-noise ratio improvement up to 31 dB in simulation compared to phase-only, even when the amplitude modulator is 60$\times$ lower resolution than its phase counterpart. We analyze the relationship between diffraction angle and amplitude modulator pixel size, and validate the concept with a benchtop experimental prototype. By showing that low resolution modulation is sufficient to improve contrast, we pave the way towards practical high-contrast holography in a compact form factor.
Multisource Holography
Sep 19, 2023
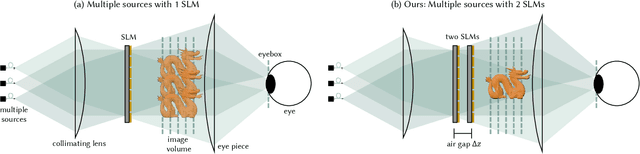
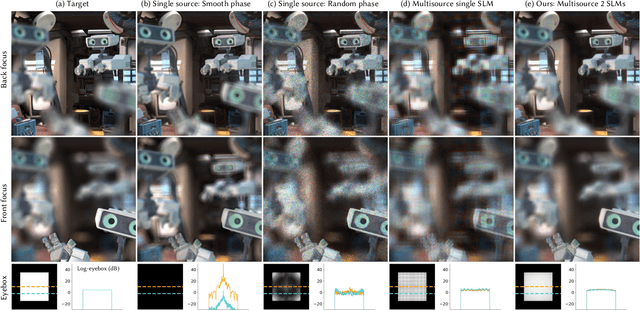
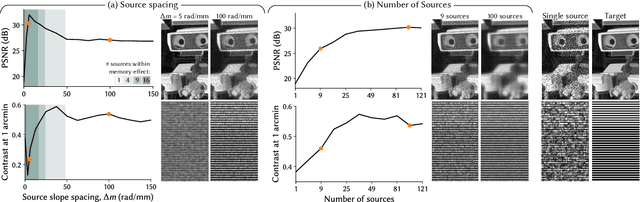
Holographic displays promise several benefits including high quality 3D imagery, accurate accommodation cues, and compact form-factors. However, holography relies on coherent illumination which can create undesirable speckle noise in the final image. Although smooth phase holograms can be speckle-free, their non-uniform eyebox makes them impractical, and speckle mitigation with partially coherent sources also reduces resolution. Averaging sequential frames for speckle reduction requires high speed modulators and consumes temporal bandwidth that may be needed elsewhere in the system. In this work, we propose multisource holography, a novel architecture that uses an array of sources to suppress speckle in a single frame without sacrificing resolution. By using two spatial light modulators, arranged sequentially, each source in the array can be controlled almost independently to create a version of the target content with different speckle. Speckle is then suppressed when the contributions from the multiple sources are averaged at the image plane. We introduce an algorithm to calculate multisource holograms, analyze the design space, and demonstrate up to a 10 dB increase in peak signal-to-noise ratio compared to an equivalent single source system. Finally, we validate the concept with a benchtop experimental prototype by producing both 2D images and focal stacks with natural defocus cues.
Stochastic Light Field Holography
Jul 12, 2023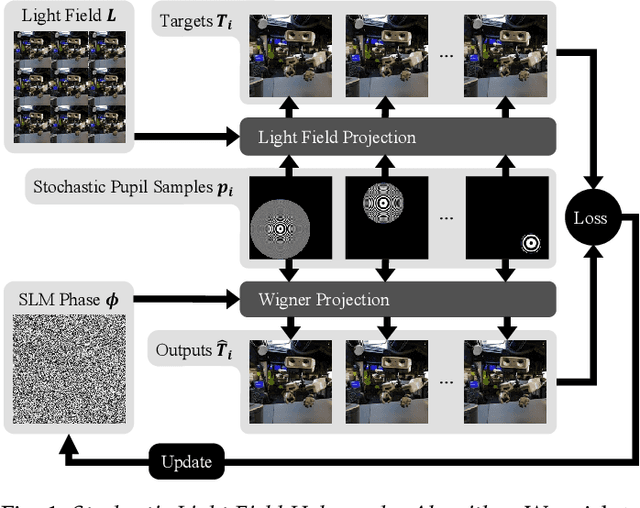


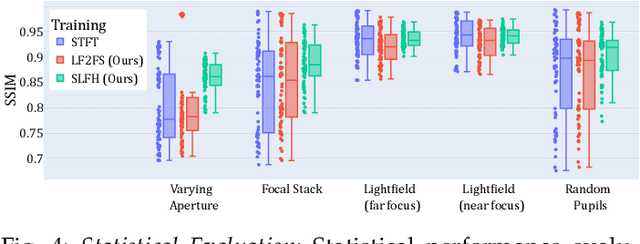
The Visual Turing Test is the ultimate goal to evaluate the realism of holographic displays. Previous studies have focused on addressing challenges such as limited \'etendue and image quality over a large focal volume, but they have not investigated the effect of pupil sampling on the viewing experience in full 3D holograms. In this work, we tackle this problem with a novel hologram generation algorithm motivated by matching the projection operators of incoherent Light Field and coherent Wigner Function light transport. To this end, we supervise hologram computation using synthesized photographs, which are rendered on-the-fly using Light Field refocusing from stochastically sampled pupil states during optimization. The proposed method produces holograms with correct parallax and focus cues, which are important for passing the Visual Turing Test. We validate that our approach compares favorably to state-of-the-art CGH algorithms that use Light Field and Focal Stack supervision. Our experiments demonstrate that our algorithm significantly improves the realism of the viewing experience for a variety of different pupil states.
Neural Étendue Expander for Ultra-Wide-Angle High-Fidelity Holographic Display
Sep 16, 2021
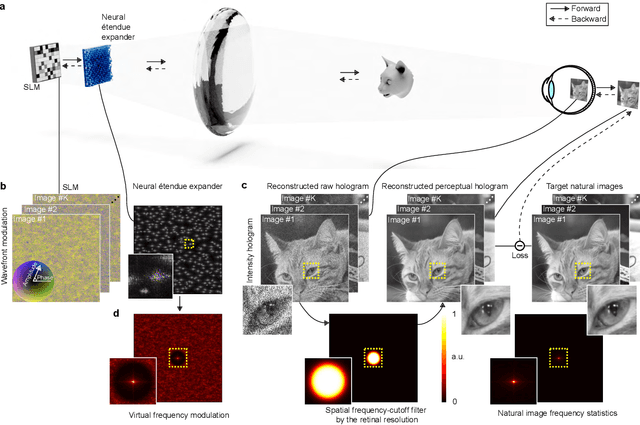


Holographic displays can generate light fields by dynamically modulating the wavefront of a coherent beam of light using a spatial light modulator, promising rich virtual and augmented reality applications. However, the limited spatial resolution of existing dynamic spatial light modulators imposes a tight bound on the diffraction angle. As a result, today's holographic displays possess low \'{e}tendue, which is the product of the display area and the maximum solid angle of diffracted light. The low \'{e}tendue forces a sacrifice of either the field of view (FOV) or the display size. In this work, we lift this limitation by presenting neural \'{e}tendue expanders. This new breed of optical elements, which is learned from a natural image dataset, enables higher diffraction angles for ultra-wide FOV while maintaining both a compact form factor and the fidelity of displayed contents to human viewers. With neural \'{e}tendue expanders, we achieve 64$\times$ \'{e}tendue expansion of natural images with reconstruction quality (measured in PSNR) over 29dB on simulated retinal-resolution images. As a result, the proposed approach with expansion factor 64$\times$ enables high-fidelity ultra-wide-angle holographic projection of natural images using an 8K-pixel SLM, resulting in a 18.5 mm eyebox size and 2.18 steradians FOV, covering 85\% of the human stereo FOV.
Untrained networks for compressive lensless photography
Mar 13, 2021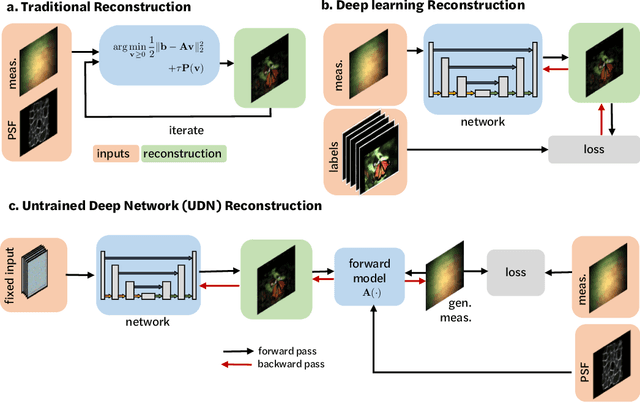
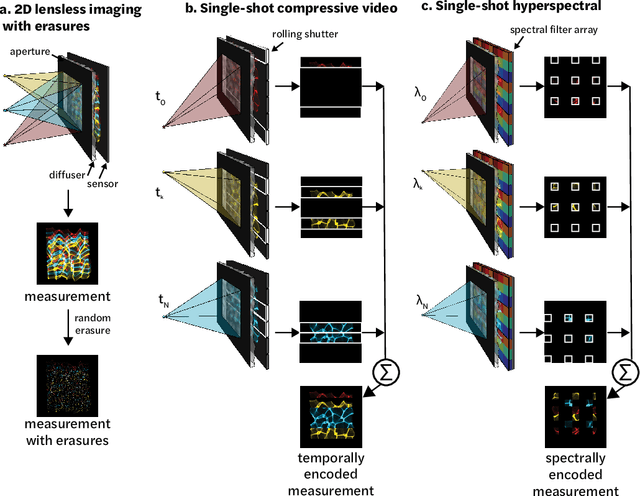
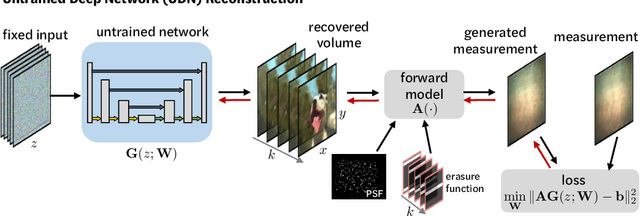
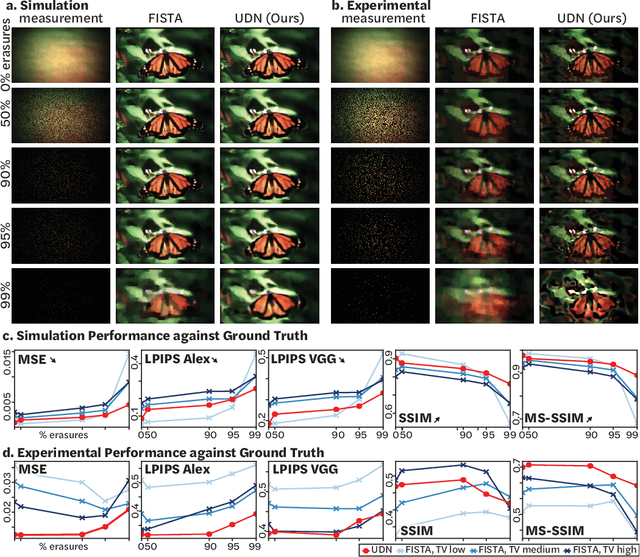
Compressive lensless imagers enable novel applications in an extremely compact device, requiring only a phase or amplitude mask placed close to the sensor. They have been demonstrated for 2D and 3D microscopy, single-shot video, and single-shot hyperspectral imaging; in each of these cases, a compressive-sensing-based inverse problem is solved in order to recover a 3D data-cube from a 2D measurement. Typically, this is accomplished using convex optimization and hand-picked priors. Alternatively, deep learning-based reconstruction methods offer the promise of better priors, but require many thousands of ground truth training pairs, which can be difficult or impossible to acquire. In this work, we propose the use of untrained networks for compressive image recovery. Our approach does not require any labeled training data, but instead uses the measurement itself to update the network weights. We demonstrate our untrained approach on lensless compressive 2D imaging as well as single-shot high-speed video recovery using the camera's rolling shutter, and single-shot hyperspectral imaging. We provide simulation and experimental verification, showing that our method results in improved image quality over existing methods.
Learned reconstructions for practical mask-based lensless imaging
Aug 30, 2019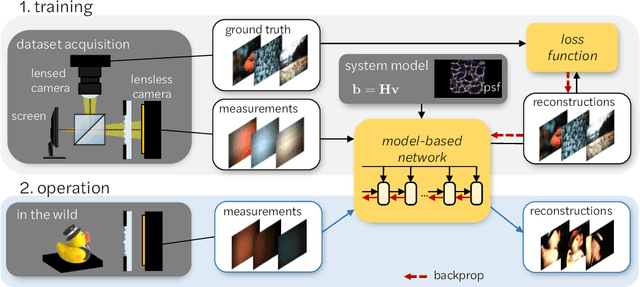
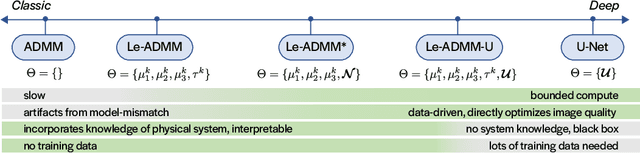
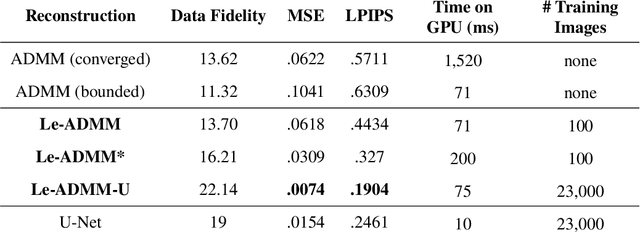
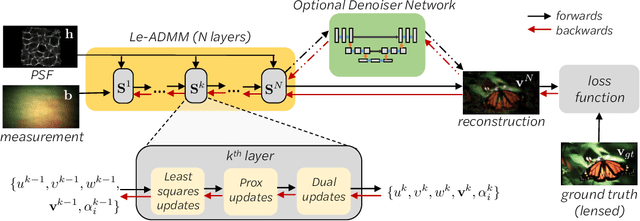
Mask-based lensless imagers are smaller and lighter than traditional lensed cameras. In these imagers, the sensor does not directly record an image of the scene; rather, a computational algorithm reconstructs it. Typically, mask-based lensless imagers use a model-based reconstruction approach that suffers from long compute times and a heavy reliance on both system calibration and heuristically chosen denoisers. In this work, we address these limitations using a bounded-compute, trainable neural network to reconstruct the image. We leverage our knowledge of the physical system by unrolling a traditional model-based optimization algorithm, whose parameters we optimize using experimentally gathered ground-truth data. Optionally, images produced by the unrolled network are then fed into a jointly-trained denoiser. As compared to traditional methods, our architecture achieves better perceptual image quality and runs 20x faster, enabling interactive previewing of the scene. We explore a spectrum between model-based and deep learning methods, showing the benefits of using an intermediate approach. Finally, we test our network on images taken in the wild with a prototype mask-based camera, demonstrating that our network generalizes to natural images.
DiffuserCam: Lensless Single-exposure 3D Imaging
Oct 05, 2017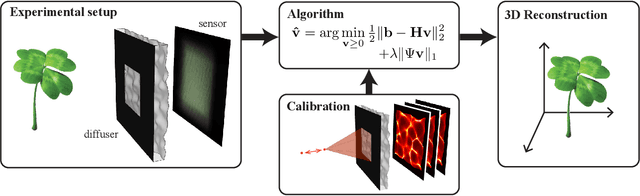
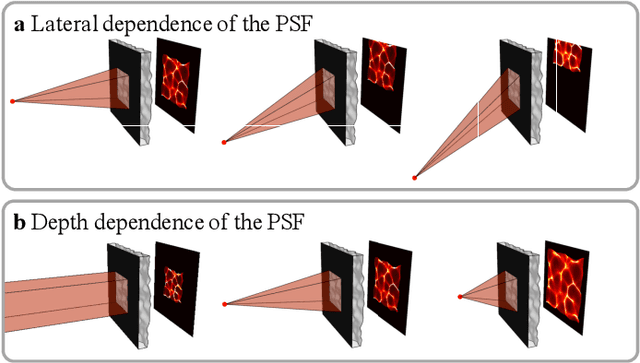
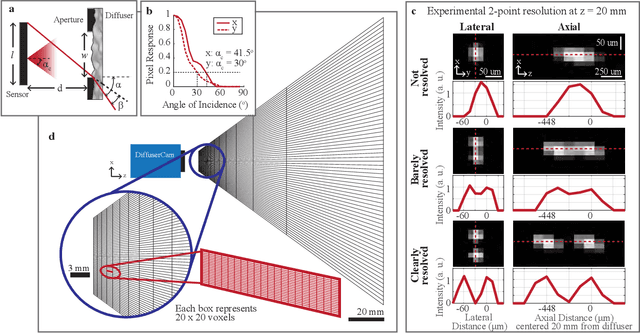
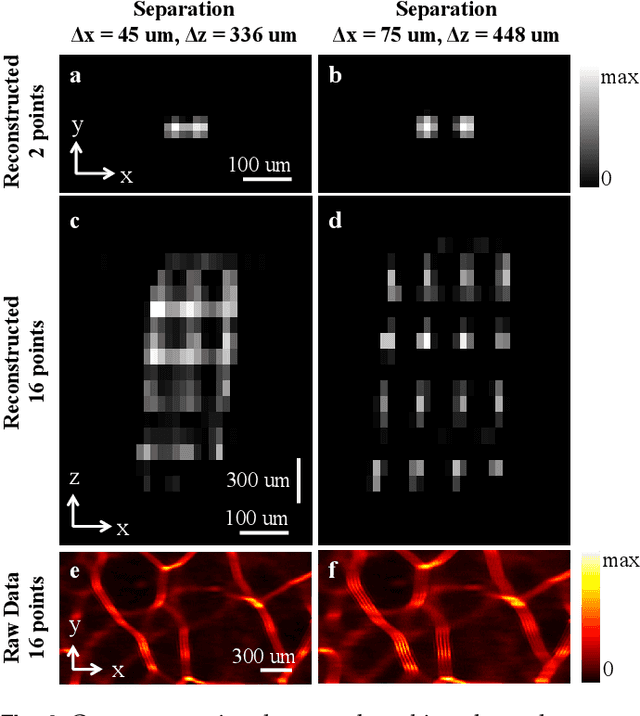
We demonstrate a compact and easy-to-build computational camera for single-shot 3D imaging. Our lensless system consists solely of a diffuser placed in front of a standard image sensor. Every point within the volumetric field-of-view projects a unique pseudorandom pattern of caustics on the sensor. By using a physical approximation and simple calibration scheme, we solve the large-scale inverse problem in a computationally efficient way. The caustic patterns enable compressed sensing, which exploits sparsity in the sample to solve for more 3D voxels than pixels on the 2D sensor. Our 3D voxel grid is chosen to match the experimentally measured two-point optical resolution across the field-of-view, resulting in 100 million voxels being reconstructed from a single 1.3 megapixel image. However, the effective resolution varies significantly with scene content. Because this effect is common to a wide range of computational cameras, we provide new theory for analyzing resolution in such systems.