 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGravitationally Lensed Black Hole Emission Tomography
Apr 07, 2022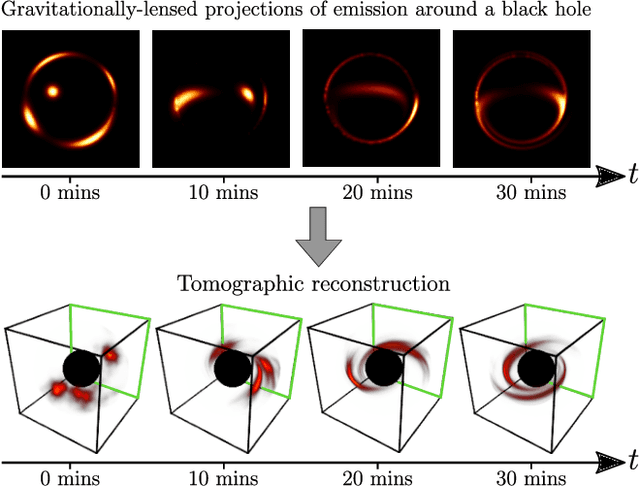

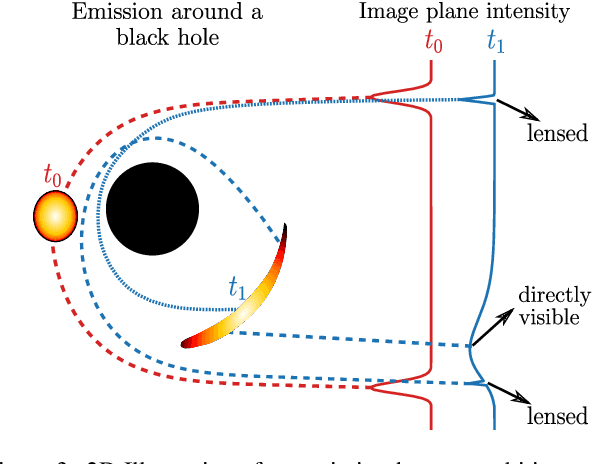
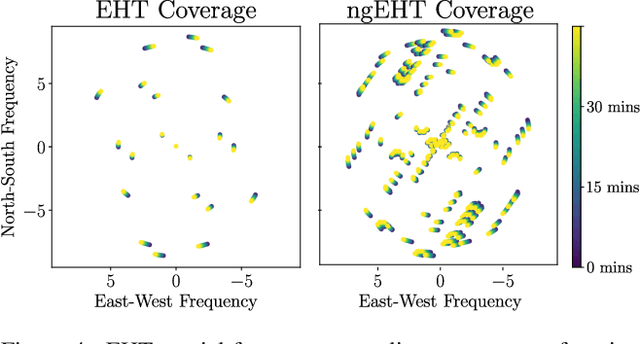
Measurements from the Event Horizon Telescope enabled the visualization of light emission around a black hole for the first time. So far, these measurements have been used to recover a 2D image under the assumption that the emission field is static over the period of acquisition. In this work, we propose BH-NeRF, a novel tomography approach that leverages gravitational lensing to recover the continuous 3D emission field near a black hole. Compared to other 3D reconstruction or tomography settings, this task poses two significant challenges: first, rays near black holes follow curved paths dictated by general relativity, and second, we only observe measurements from a single viewpoint. Our method captures the unknown emission field using a continuous volumetric function parameterized by a coordinate-based neural network, and uses knowledge of Keplerian orbital dynamics to establish correspondence between 3D points over time. Together, these enable BH-NeRF to recover accurate 3D emission fields, even in challenging situations with sparse measurements and uncertain orbital dynamics. This work takes the first steps in showing how future measurements from the Event Horizon Telescope could be used to recover evolving 3D emission around the supermassive black hole in our Galactic center.
PlenOctrees for Real-time Rendering of Neural Radiance Fields
Mar 25, 2021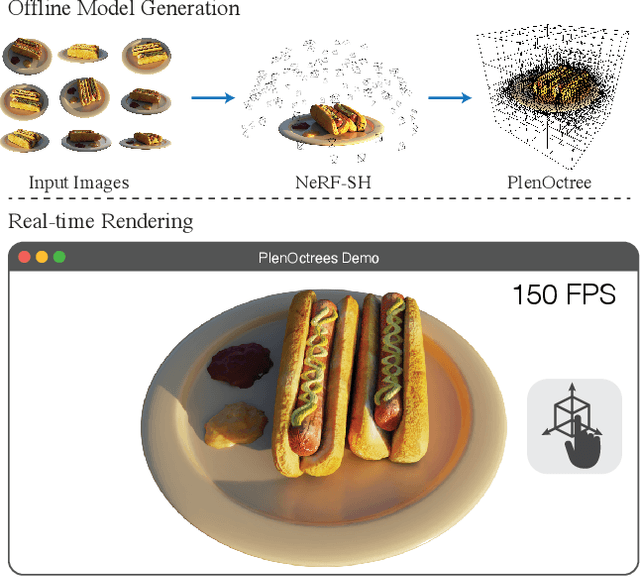
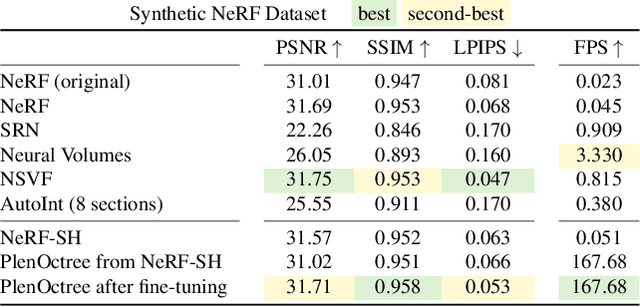
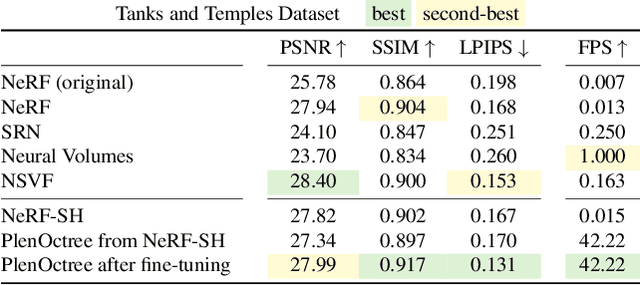
We introduce a method to render Neural Radiance Fields (NeRFs) in real time using PlenOctrees, an octree-based 3D representation which supports view-dependent effects. Our method can render 800x800 images at more than 150 FPS, which is over 3000 times faster than conventional NeRFs. We do so without sacrificing quality while preserving the ability of NeRFs to perform free-viewpoint rendering of scenes with arbitrary geometry and view-dependent effects. Real-time performance is achieved by pre-tabulating the NeRF into a PlenOctree. In order to preserve view-dependent effects such as specularities, we factorize the appearance via closed-form spherical basis functions. Specifically, we show that it is possible to train NeRFs to predict a spherical harmonic representation of radiance, removing the viewing direction as an input to the neural network. Furthermore, we show that PlenOctrees can be directly optimized to further minimize the reconstruction loss, which leads to equal or better quality compared to competing methods. Moreover, this octree optimization step can be used to reduce the training time, as we no longer need to wait for the NeRF training to converge fully. Our real-time neural rendering approach may potentially enable new applications such as 6-DOF industrial and product visualizations, as well as next generation AR/VR systems. PlenOctrees are amenable to in-browser rendering as well; please visit the project page for the interactive online demo, as well as video and code: https://alexyu.net/plenoctrees
Learned Initializations for Optimizing Coordinate-Based Neural Representations
Dec 03, 2020


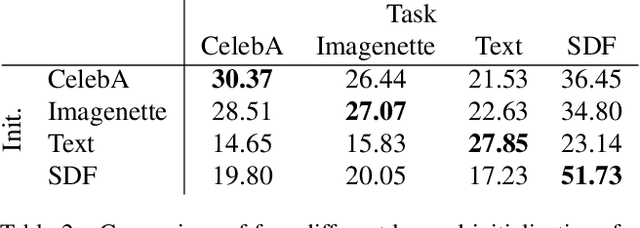
Coordinate-based neural representations have shown significant promise as an alternative to discrete, array-based representations for complex low dimensional signals. However, optimizing a coordinate-based network from randomly initialized weights for each new signal is inefficient. We propose applying standard meta-learning algorithms to learn the initial weight parameters for these fully-connected networks based on the underlying class of signals being represented (e.g., images of faces or 3D models of chairs). Despite requiring only a minor change in implementation, using these learned initial weights enables faster convergence during optimization and can serve as a strong prior over the signal class being modeled, resulting in better generalization when only partial observations of a given signal are available. We explore these benefits across a variety of tasks, including representing 2D images, reconstructing CT scans, and recovering 3D shapes and scenes from 2D image observations.
Miniscope3D: optimized single-shot miniature 3D fluorescence microscopy
Oct 12, 2020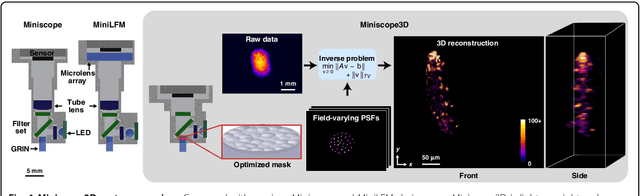
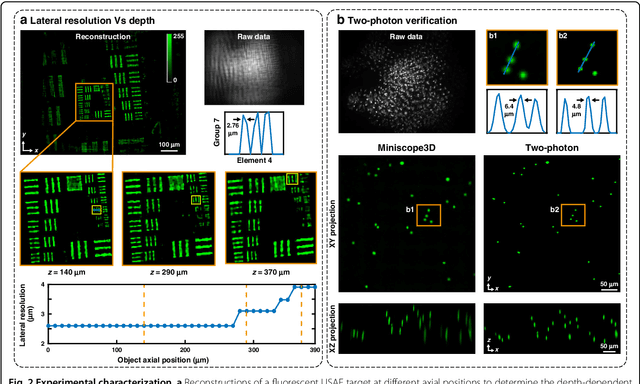
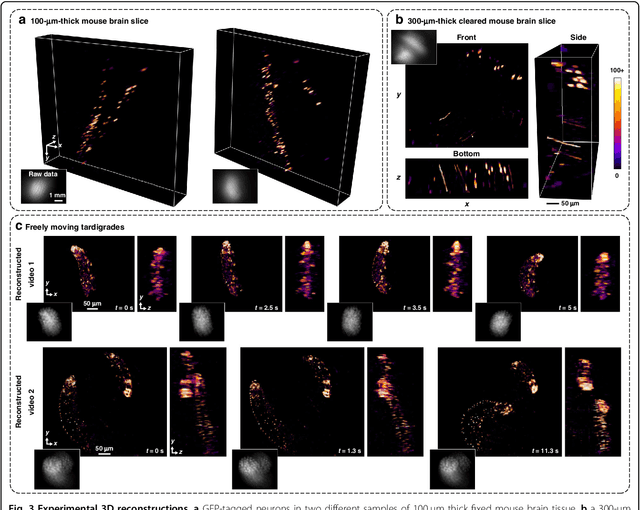

Miniature fluorescence microscopes are a standard tool in systems biology. However, widefield miniature microscopes capture only 2D information, and modifications that enable 3D capabilities increase the size and weight and have poor resolution outside a narrow depth range. Here, we achieve the 3D capability by replacing the tube lens of a conventional 2D Miniscope with an optimized multifocal phase mask at the objective's aperture stop. Placing the phase mask at the aperture stop significantly reduces the size of the device, and varying the focal lengths enables a uniform resolution across a wide depth range. The phase mask encodes the 3D fluorescence intensity into a single 2D measurement, and the 3D volume is recovered by solving a sparsity-constrained inverse problem. We provide methods for designing and fabricating the phase mask and an efficient forward model that accounts for the field-varying aberrations in miniature objectives. We demonstrate a prototype that is 17 mm tall and weighs 2.5 grams, achieving 2.76 $\mu$m lateral, and 15 $\mu$m axial resolution across most of the 900x700x390 $\mu m^3$ volume at 40 volumes per second. The performance is validated experimentally on resolution targets, dynamic biological samples, and mouse brain tissue. Compared with existing miniature single-shot volume-capture implementations, our system is smaller and lighter and achieves a more than 2x better lateral and axial resolution throughout a 10x larger usable depth range. Our microscope design provides single-shot 3D imaging for applications where a compact platform matters, such as volumetric neural imaging in freely moving animals and 3D motion studies of dynamic samples in incubators and lab-on-a-chip devices.
* Published with Nature Springer in Light: Science and Applications
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
Jun 18, 2020
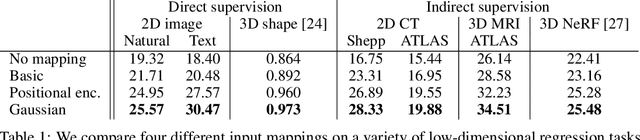
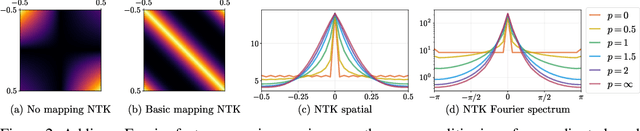
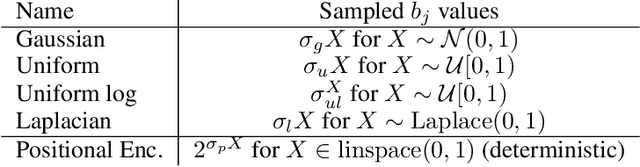
We show that passing input points through a simple Fourier feature mapping enables a multilayer perceptron (MLP) to learn high-frequency functions in low-dimensional problem domains. These results shed light on recent advances in computer vision and graphics that achieve state-of-the-art results by using MLPs to represent complex 3D objects and scenes. Using tools from the neural tangent kernel (NTK) literature, we show that a standard MLP fails to learn high frequencies both in theory and in practice. To overcome this spectral bias, we use a Fourier feature mapping to transform the effective NTK into a stationary kernel with a tunable bandwidth. We suggest an approach for selecting problem-specific Fourier features that greatly improves the performance of MLPs for low-dimensional regression tasks relevant to the computer vision and graphics communities.
Portrait Shadow Manipulation
May 20, 2020
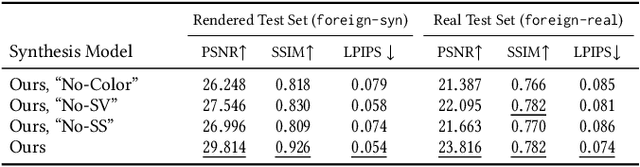
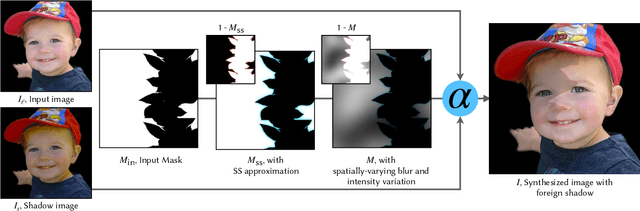
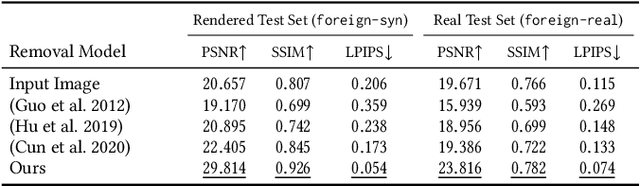
Casually-taken portrait photographs often suffer from unflattering lighting and shadowing because of suboptimal conditions in the environment. Aesthetic qualities such as the position and softness of shadows and the lighting ratio between the bright and dark parts of the face are frequently determined by the constraints of the environment rather than by the photographer. Professionals address this issue by adding light shaping tools such as scrims, bounce cards, and flashes. In this paper, we present a computational approach that gives casual photographers some of this control, thereby allowing poorly-lit portraits to be relit post-capture in a realistic and easily-controllable way. Our approach relies on a pair of neural networks---one to remove foreign shadows cast by external objects, and another to soften facial shadows cast by the features of the subject and to add a synthetic fill light to improve the lighting ratio. To train our first network we construct a dataset of real-world portraits wherein synthetic foreign shadows are rendered onto the face, and we show that our network learns to remove those unwanted shadows. To train our second network we use a dataset of Light Stage scans of human subjects to construct input/output pairs of input images harshly lit by a small light source, and variably softened and fill-lit output images of each face. We propose a way to explicitly encode facial symmetry and show that our dataset and training procedure enable the model to generalize to images taken in the wild. Together, these networks enable the realistic and aesthetically pleasing enhancement of shadows and lights in real-world portrait images
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Mar 19, 2020
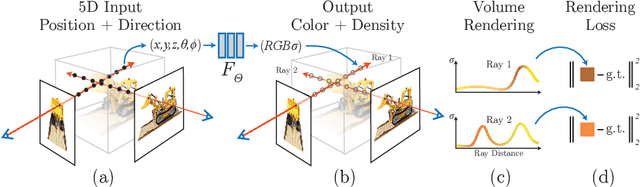


We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-connected (non-convolutional) deep network, whose input is a single continuous 5D coordinate (spatial location $(x,y,z)$ and viewing direction $(\theta, \phi)$) and whose output is the volume density and view-dependent emitted radiance at that spatial location. We synthesize views by querying 5D coordinates along camera rays and use classic volume rendering techniques to project the output colors and densities into an image. Because volume rendering is naturally differentiable, the only input required to optimize our representation is a set of images with known camera poses. We describe how to effectively optimize neural radiance fields to render photorealistic novel views of scenes with complicated geometry and appearance, and demonstrate results that outperform prior work on neural rendering and view synthesis. View synthesis results are best viewed as videos, so we urge readers to view our supplementary video for convincing comparisons.
Video from Stills: Lensless Imaging with Rolling Shutter
May 30, 2019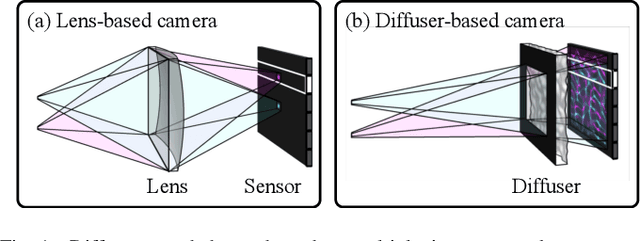

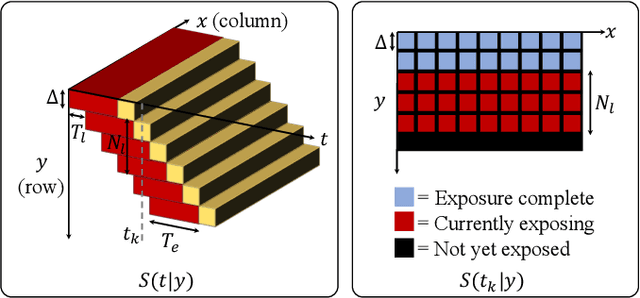
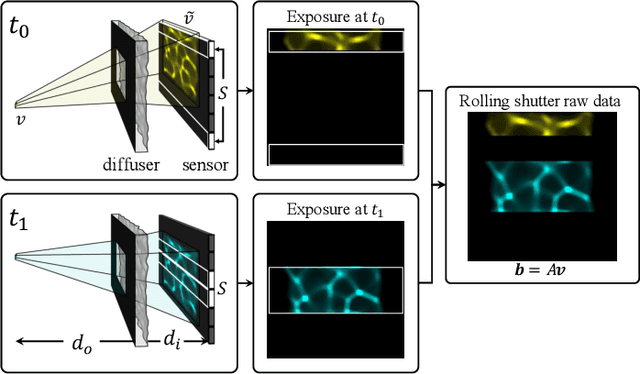
Because image sensor chips have a finite bandwidth with which to read out pixels, recording video typically requires a trade-off between frame rate and pixel count. Compressed sensing techniques can circumvent this trade-off by assuming that the image is compressible. Here, we propose using multiplexing optics to spatially compress the scene, enabling information about the whole scene to be sampled from a row of sensor pixels, which can be read off quickly via a rolling shutter CMOS sensor. Conveniently, such multiplexing can be achieved with a simple lensless, diffuser-based imaging system. Using sparse recovery methods, we are able to recover 140 video frames at over 4,500 frames per second, all from a single captured image with a rolling shutter sensor. Our proof-of-concept system uses easily-fabricated diffusers paired with an off-the-shelf sensor. The resulting prototype enables compressive encoding of high frame rate video into a single rolling shutter exposure, and exceeds the sampling-limited performance of an equivalent global shutter system for sufficiently sparse objects.
Synthetic Defocus and Look-Ahead Autofocus for Casual Videography
May 21, 2019


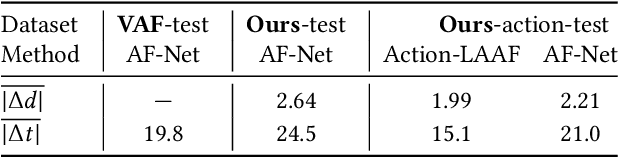
In cinema, large camera lenses create beautiful shallow depth of field (DOF), but make focusing difficult and expensive. Accurate cinema focus usually relies on a script and a person to control focus in realtime. Casual videographers often crave cinematic focus, but fail to achieve it. We either sacrifice shallow DOF, as in smartphone videos; or we struggle to deliver accurate focus, as in videos from larger cameras. This paper is about a new approach in the pursuit of cinematic focus for casual videography. We present a system that synthetically renders refocusable video from a deep DOF video shot with a smartphone, and analyzes future video frames to deliver context-aware autofocus for the current frame. To create refocusable video, we extend recent machine learning methods designed for still photography, contributing a new dataset for machine training, a rendering model better suited to cinema focus, and a filtering solution for temporal coherence. To choose focus accurately for each frame, we demonstrate autofocus that looks at upcoming video frames and applies AI-assist modules such as motion, face, audio and saliency detection. We also show that autofocus benefits from machine learning and a large-scale video dataset with focus annotation, where we use our RVR-LAAF GUI to create this sizable dataset efficiently. We deliver, for example, a shallow DOF video where the autofocus transitions onto each person before she begins to speak. This is impossible for conventional camera autofocus because it would require seeing into the future.
Zoom To Learn, Learn To Zoom
May 13, 2019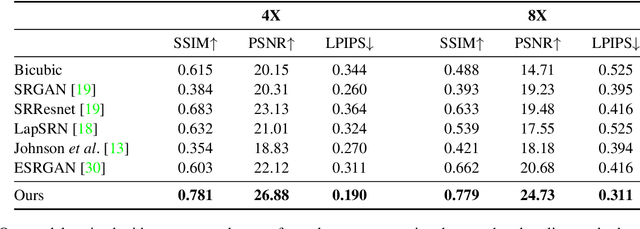
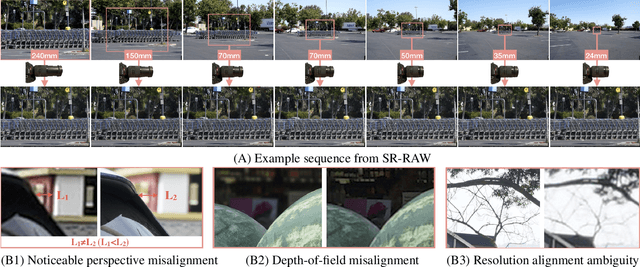


This paper shows that when applying machine learning to digital zoom for photography, it is beneficial to use real, RAW sensor data for training. Existing learning-based super-resolution methods do not use real sensor data, instead operating on RGB images. In practice, these approaches result in loss of detail and accuracy in their digitally zoomed output when zooming in on distant image regions. We also show that synthesizing sensor data by resampling high-resolution RGB images is an oversimplified approximation of real sensor data and noise, resulting in worse image quality. The key barrier to using real sensor data for training is that ground truth high-resolution imagery is missing. We show how to obtain the ground-truth data with optically zoomed images and contribute a dataset, SR-RAW, for real-world computational zoom. We use SR-RAW to train a deep network with a novel contextual bilateral loss (CoBi) that delivers critical robustness to mild misalignment in input-output image pairs. The trained network achieves state-of-the-art performance in 4X and 8X computational zoom.