 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstant Expressive Gaussian Head Avatar via 3D-Aware Expression Distillation
Dec 18, 2025Portrait animation has witnessed tremendous quality improvements thanks to recent advances in video diffusion models. However, these 2D methods often compromise 3D consistency and speed, limiting their applicability in real-world scenarios, such as digital twins or telepresence. In contrast, 3D-aware facial animation feedforward methods -- built upon explicit 3D representations, such as neural radiance fields or Gaussian splatting -- ensure 3D consistency and achieve faster inference speed, but come with inferior expression details. In this paper, we aim to combine their strengths by distilling knowledge from a 2D diffusion-based method into a feed-forward encoder, which instantly converts an in-the-wild single image into a 3D-consistent, fast yet expressive animatable representation. Our animation representation is decoupled from the face's 3D representation and learns motion implicitly from data, eliminating the dependency on pre-defined parametric models that often constrain animation capabilities. Unlike previous computationally intensive global fusion mechanisms (e.g., multiple attention layers) for fusing 3D structural and animation information, our design employs an efficient lightweight local fusion strategy to achieve high animation expressivity. As a result, our method runs at 107.31 FPS for animation and pose control while achieving comparable animation quality to the state-of-the-art, surpassing alternative designs that trade speed for quality or vice versa. Project website is https://research.nvidia.com/labs/amri/projects/instant4d
MS-GS: Multi-Appearance Sparse-View 3D Gaussian Splatting in the Wild
Sep 19, 2025
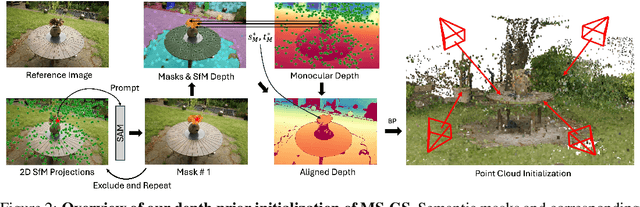
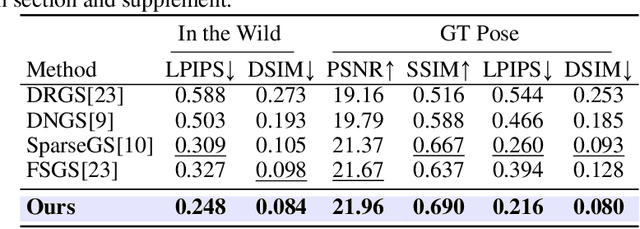
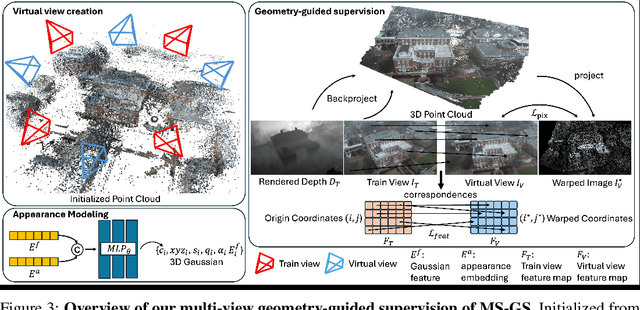
In-the-wild photo collections often contain limited volumes of imagery and exhibit multiple appearances, e.g., taken at different times of day or seasons, posing significant challenges to scene reconstruction and novel view synthesis. Although recent adaptations of Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) have improved in these areas, they tend to oversmooth and are prone to overfitting. In this paper, we present MS-GS, a novel framework designed with Multi-appearance capabilities in Sparse-view scenarios using 3DGS. To address the lack of support due to sparse initializations, our approach is built on the geometric priors elicited from monocular depth estimations. The key lies in extracting and utilizing local semantic regions with a Structure-from-Motion (SfM) points anchored algorithm for reliable alignment and geometry cues. Then, to introduce multi-view constraints, we propose a series of geometry-guided supervision at virtual views in a fine-grained and coarse scheme to encourage 3D consistency and reduce overfitting. We also introduce a dataset and an in-the-wild experiment setting to set up more realistic benchmarks. We demonstrate that MS-GS achieves photorealistic renderings under various challenging sparse-view and multi-appearance conditions and outperforms existing approaches significantly across different datasets.
Neural BRDF Importance Sampling by Reparameterization
May 13, 2025Neural bidirectional reflectance distribution functions (BRDFs) have emerged as popular material representations for enhancing realism in physically-based rendering. Yet their importance sampling remains a significant challenge. In this paper, we introduce a reparameterization-based formulation of neural BRDF importance sampling that seamlessly integrates into the standard rendering pipeline with precise generation of BRDF samples. The reparameterization-based formulation transfers the distribution learning task to a problem of identifying BRDF integral substitutions. In contrast to previous methods that rely on invertible networks and multi-step inference to reconstruct BRDF distributions, our model removes these constraints, which offers greater flexibility and efficiency. Our variance and performance analysis demonstrates that our reparameterization method achieves the best variance reduction in neural BRDF renderings while maintaining high inference speeds compared to existing baselines.
Locally Orderless Images for Optimization in Differentiable Rendering
Mar 27, 2025Problems in differentiable rendering often involve optimizing scene parameters that cause motion in image space. The gradients for such parameters tend to be sparse, leading to poor convergence. While existing methods address this sparsity through proxy gradients such as topological derivatives or lagrangian derivatives, they make simplifying assumptions about rendering. Multi-resolution image pyramids offer an alternative approach but prove unreliable in practice. We introduce a method that uses locally orderless images, where each pixel maps to a histogram of intensities that preserves local variations in appearance. Using an inverse rendering objective that minimizes histogram distance, our method extends support for sparsely defined image gradients and recovers optimal parameters. We validate our method on various inverse problems using both synthetic and real data.
A Differentiable Wave Optics Model for End-to-End Computational Imaging System Optimization
Dec 13, 2024



End-to-end optimization, which simultaneously optimizes optics and algorithms, has emerged as a powerful data-driven method for computational imaging system design. This method achieves joint optimization through backpropagation by incorporating differentiable optics simulators to generate measurements and algorithms to extract information from measurements. However, due to high computational costs, it is challenging to model both aberration and diffraction in light transport for end-to-end optimization of compound optics. Therefore, most existing methods compromise physical accuracy by neglecting wave optics effects or off-axis aberrations, which raises concerns about the robustness of the resulting designs. In this paper, we propose a differentiable optics simulator that efficiently models both aberration and diffraction for compound optics. Using the simulator, we conduct end-to-end optimization on scene reconstruction and classification. Experimental results demonstrate that both lenses and algorithms adopt different configurations depending on whether wave optics is modeled. We also show that systems optimized without wave optics suffer from performance degradation when wave optics effects are introduced during testing. These findings underscore the importance of accurate wave optics modeling in optimizing imaging systems for robust, high-performance applications.
SimVS: Simulating World Inconsistencies for Robust View Synthesis
Dec 10, 2024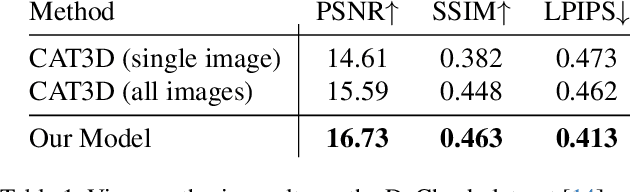



Novel-view synthesis techniques achieve impressive results for static scenes but struggle when faced with the inconsistencies inherent to casual capture settings: varying illumination, scene motion, and other unintended effects that are difficult to model explicitly. We present an approach for leveraging generative video models to simulate the inconsistencies in the world that can occur during capture. We use this process, along with existing multi-view datasets, to create synthetic data for training a multi-view harmonization network that is able to reconcile inconsistent observations into a consistent 3D scene. We demonstrate that our world-simulation strategy significantly outperforms traditional augmentation methods in handling real-world scene variations, thereby enabling highly accurate static 3D reconstructions in the presence of a variety of challenging inconsistencies. Project page: https://alextrevithick.github.io/simvs
Volumetrically Consistent 3D Gaussian Rasterization
Dec 04, 2024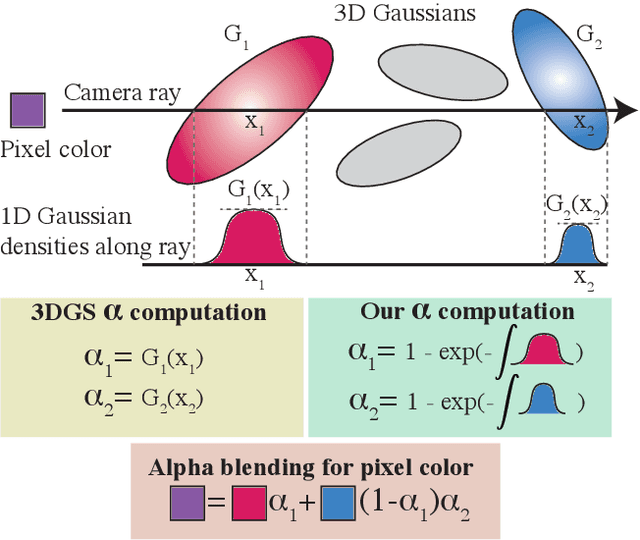
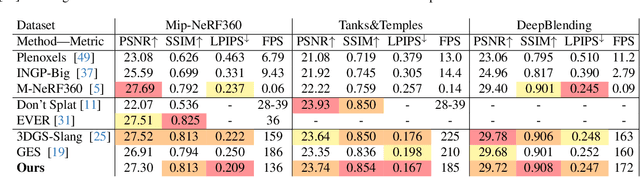
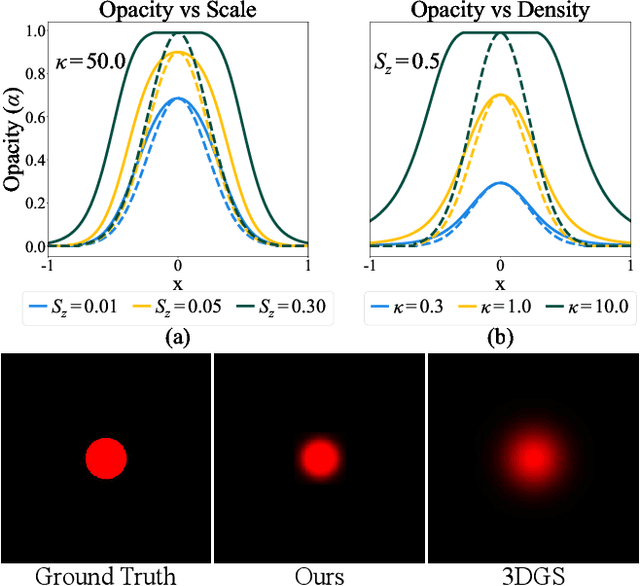
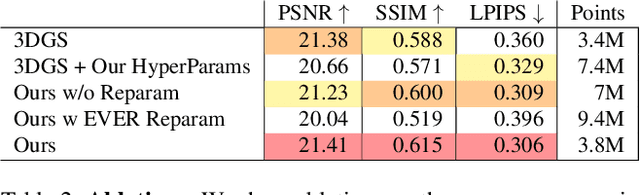
Recently, 3D Gaussian Splatting (3DGS) has enabled photorealistic view synthesis at high inference speeds. However, its splatting-based rendering model makes several approximations to the rendering equation, reducing physical accuracy. We show that splatting and its approximations are unnecessary, even within a rasterizer; we instead volumetrically integrate 3D Gaussians directly to compute the transmittance across them analytically. We use this analytic transmittance to derive more physically-accurate alpha values than 3DGS, which can directly be used within their framework. The result is a method that more closely follows the volume rendering equation (similar to ray-tracing) while enjoying the speed benefits of rasterization. Our method represents opaque surfaces with higher accuracy and fewer points than 3DGS. This enables it to outperform 3DGS for view synthesis (measured in SSIM and LPIPS). Being volumetrically consistent also enables our method to work out of the box for tomography. We match the state-of-the-art 3DGS-based tomography method with fewer points. Being volumetrically consistent also enables our method to work out of the box for tomography. We match the state-of-the-art 3DGS-based tomography method with fewer points.
Geometry Field Splatting with Gaussian Surfels
Nov 26, 2024Geometric reconstruction of opaque surfaces from images is a longstanding challenge in computer vision, with renewed interest from volumetric view synthesis algorithms using radiance fields. We leverage the geometry field proposed in recent work for stochastic opaque surfaces, which can then be converted to volume densities. We adapt Gaussian kernels or surfels to splat the geometry field rather than the volume, enabling precise reconstruction of opaque solids. Our first contribution is to derive an efficient and almost exact differentiable rendering algorithm for geometry fields parameterized by Gaussian surfels, while removing current approximations involving Taylor series and no self-attenuation. Next, we address the discontinuous loss landscape when surfels cluster near geometry, showing how to guarantee that the rendered color is a continuous function of the colors of the kernels, irrespective of ordering. Finally, we use latent representations with spherical harmonics encoded reflection vectors rather than spherical harmonics encoded colors to better address specular surfaces. We demonstrate significant improvement in the quality of reconstructed 3D surfaces on widely-used datasets.
Sampling for View Synthesis: From Local Light Field Fusion to Neural Radiance Fields and Beyond
Aug 08, 2024Capturing and rendering novel views of complex real-world scenes is a long-standing problem in computer graphics and vision, with applications in augmented and virtual reality, immersive experiences and 3D photography. The advent of deep learning has enabled revolutionary advances in this area, classically known as image-based rendering. However, previous approaches require intractably dense view sampling or provide little or no guidance for how users should sample views of a scene to reliably render high-quality novel views. Local light field fusion proposes an algorithm for practical view synthesis from an irregular grid of sampled views that first expands each sampled view into a local light field via a multiplane image scene representation, then renders novel views by blending adjacent local light fields. Crucially, we extend traditional plenoptic sampling theory to derive a bound that specifies precisely how densely users should sample views of a given scene when using our algorithm. We achieve the perceptual quality of Nyquist rate view sampling while using up to 4000x fewer views. Subsequent developments have led to new scene representations for deep learning with view synthesis, notably neural radiance fields, but the problem of sparse view synthesis from a small number of images has only grown in importance. We reprise some of the recent results on sparse and even single image view synthesis, while posing the question of whether prescriptive sampling guidelines are feasible for the new generation of image-based rendering algorithms.
Neural Directional Encoding for Efficient and Accurate View-Dependent Appearance Modeling
May 23, 2024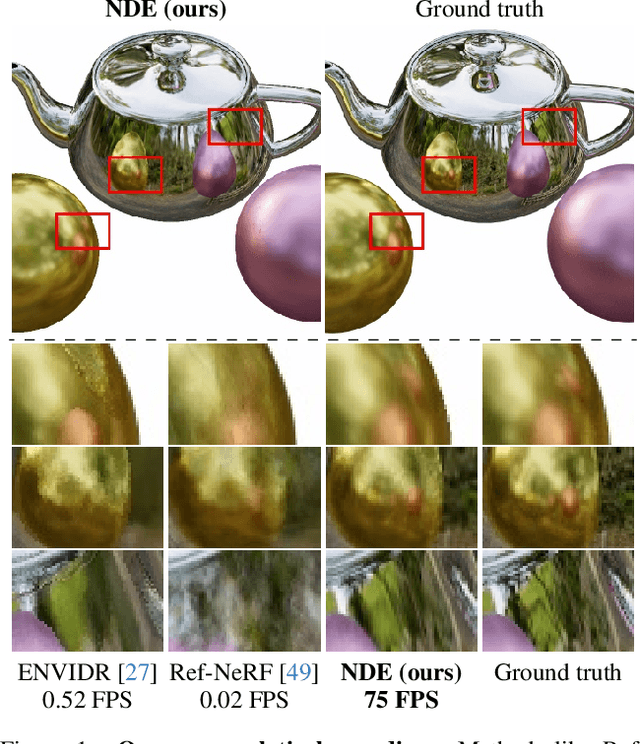
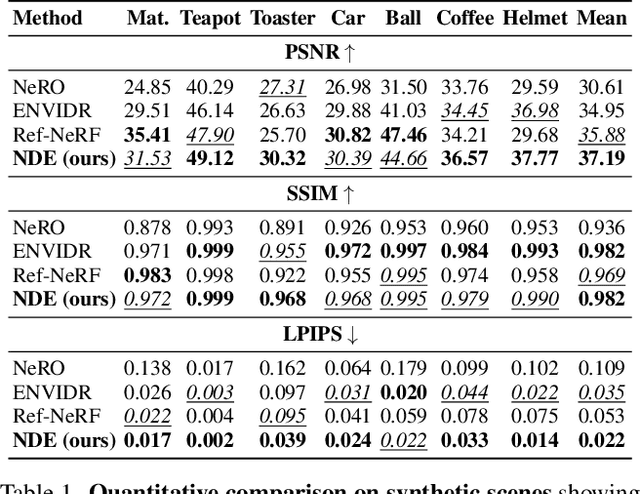
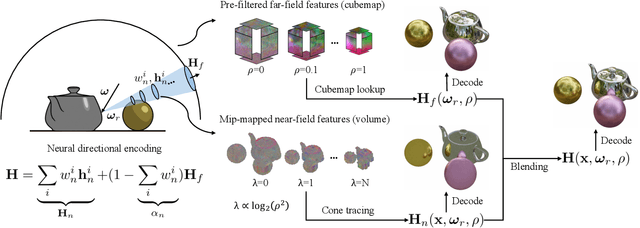
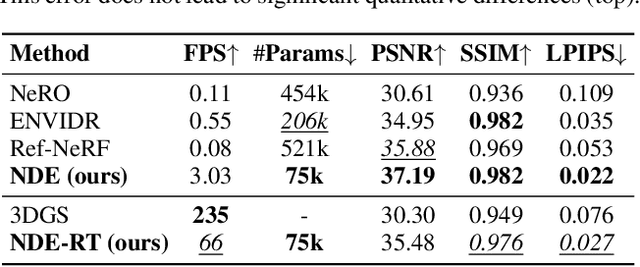
Novel-view synthesis of specular objects like shiny metals or glossy paints remains a significant challenge. Not only the glossy appearance but also global illumination effects, including reflections of other objects in the environment, are critical components to faithfully reproduce a scene. In this paper, we present Neural Directional Encoding (NDE), a view-dependent appearance encoding of neural radiance fields (NeRF) for rendering specular objects. NDE transfers the concept of feature-grid-based spatial encoding to the angular domain, significantly improving the ability to model high-frequency angular signals. In contrast to previous methods that use encoding functions with only angular input, we additionally cone-trace spatial features to obtain a spatially varying directional encoding, which addresses the challenging interreflection effects. Extensive experiments on both synthetic and real datasets show that a NeRF model with NDE (1) outperforms the state of the art on view synthesis of specular objects, and (2) works with small networks to allow fast (real-time) inference. The project webpage and source code are available at: \url{https://lwwu2.github.io/nde/}.