 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance Marching for Generative Modeling
Feb 03, 2026Time-unconditional generative models learn time-independent denoising vector fields. But without time conditioning, the same noisy input may correspond to multiple noise levels and different denoising directions, which interferes with the supervision signal. Inspired by distance field modeling, we propose Distance Marching, a new time-unconditional approach with two principled inference methods. Crucially, we design losses that focus on closer targets. This yields denoising directions better directed toward the data manifold. Across architectures, Distance Marching consistently improves FID by 13.5% on CIFAR-10 and ImageNet over recent time-unconditional baselines. For class-conditional ImageNet generation, despite removing time input, Distance Marching surpasses flow matching using our losses and inference methods. It achieves lower FID than flow matching's final performance using 60% of the sampling steps and 13.6% lower FID on average across backbone sizes. Moreover, our distance prediction is also helpful for early stopping during sampling and for OOD detection. We hope distance field modeling can serve as a principled lens for generative modeling.
A Differentiable Wave Optics Model for End-to-End Computational Imaging System Optimization
Dec 13, 2024



End-to-end optimization, which simultaneously optimizes optics and algorithms, has emerged as a powerful data-driven method for computational imaging system design. This method achieves joint optimization through backpropagation by incorporating differentiable optics simulators to generate measurements and algorithms to extract information from measurements. However, due to high computational costs, it is challenging to model both aberration and diffraction in light transport for end-to-end optimization of compound optics. Therefore, most existing methods compromise physical accuracy by neglecting wave optics effects or off-axis aberrations, which raises concerns about the robustness of the resulting designs. In this paper, we propose a differentiable optics simulator that efficiently models both aberration and diffraction for compound optics. Using the simulator, we conduct end-to-end optimization on scene reconstruction and classification. Experimental results demonstrate that both lenses and algorithms adopt different configurations depending on whether wave optics is modeled. We also show that systems optimized without wave optics suffer from performance degradation when wave optics effects are introduced during testing. These findings underscore the importance of accurate wave optics modeling in optimizing imaging systems for robust, high-performance applications.
HotSpot: Screened Poisson Equation for Signed Distance Function Optimization
Nov 21, 2024



We propose a method, HotSpot, for optimizing neural signed distance functions, based on a relation between the solution of a screened Poisson equation and the distance function. Existing losses such as the eikonal loss cannot guarantee the recovered implicit function to be a distance function, even when the implicit function satisfies the eikonal equation almost everywhere. Furthermore, the eikonal loss suffers from stability issues in optimization and the remedies that introduce area or divergence minimization can lead to oversmoothing. We address these challenges by designing a loss function that when minimized can converge to the true distance function, is stable, and naturally penalize large surface area. We provide theoretical analysis and experiments on both challenging 2D and 3D datasets and show that our method provide better surface reconstruction and more accurate distance approximation.
WatChat: Explaining perplexing programs by debugging mental models
Mar 08, 2024Often, a good explanation for a program's unexpected behavior is a bug in the programmer's code. But sometimes, an even better explanation is a bug in the programmer's mental model of the language they are using. Instead of merely debugging our current code ("giving the programmer a fish"), what if our tools could directly debug our mental models ("teaching the programmer to fish")? In this paper, we apply ideas from computational cognitive science to do exactly that. Given a perplexing program, we use program synthesis techniques to automatically infer potential misconceptions that might cause the user to be surprised by the program's behavior. By analyzing these misconceptions, we provide succinct, useful explanations of the program's behavior. Our methods can even be inverted to synthesize pedagogical example programs for diagnosing and correcting misconceptions in students.
Differentiable Visual Computing for Inverse Problems and Machine Learning
Nov 21, 2023Originally designed for applications in computer graphics, visual computing (VC) methods synthesize information about physical and virtual worlds, using prescribed algorithms optimized for spatial computing. VC is used to analyze geometry, physically simulate solids, fluids, and other media, and render the world via optical techniques. These fine-tuned computations that operate explicitly on a given input solve so-called forward problems, VC excels at. By contrast, deep learning (DL) allows for the construction of general algorithmic models, side stepping the need for a purely first principles-based approach to problem solving. DL is powered by highly parameterized neural network architectures -- universal function approximators -- and gradient-based search algorithms which can efficiently search that large parameter space for optimal models. This approach is predicated by neural network differentiability, the requirement that analytic derivatives of a given problem's task metric can be computed with respect to neural network's parameters. Neural networks excel when an explicit model is not known, and neural network training solves an inverse problem in which a model is computed from data.
Neural Free-Viewpoint Relighting for Glossy Indirect Illumination
Jul 12, 2023Precomputed Radiance Transfer (PRT) remains an attractive solution for real-time rendering of complex light transport effects such as glossy global illumination. After precomputation, we can relight the scene with new environment maps while changing viewpoint in real-time. However, practical PRT methods are usually limited to low-frequency spherical harmonic lighting. All-frequency techniques using wavelets are promising but have so far had little practical impact. The curse of dimensionality and much higher data requirements have typically limited them to relighting with fixed view or only direct lighting with triple product integrals. In this paper, we demonstrate a hybrid neural-wavelet PRT solution to high-frequency indirect illumination, including glossy reflection, for relighting with changing view. Specifically, we seek to represent the light transport function in the Haar wavelet basis. For global illumination, we learn the wavelet transport using a small multi-layer perceptron (MLP) applied to a feature field as a function of spatial location and wavelet index, with reflected direction and material parameters being other MLP inputs. We optimize/learn the feature field (compactly represented by a tensor decomposition) and MLP parameters from multiple images of the scene under different lighting and viewing conditions. We demonstrate real-time (512 x 512 at 24 FPS, 800 x 600 at 13 FPS) precomputed rendering of challenging scenes involving view-dependent reflections and even caustics.
Acting as Inverse Inverse Planning
May 26, 2023Great storytellers know how to take us on a journey. They direct characters to act -- not necessarily in the most rational way -- but rather in a way that leads to interesting situations, and ultimately creates an impactful experience for audience members looking on. If audience experience is what matters most, then can we help artists and animators *directly* craft such experiences, independent of the concrete character actions needed to evoke those experiences? In this paper, we offer a novel computational framework for such tools. Our key idea is to optimize animations with respect to *simulated* audience members' experiences. To simulate the audience, we borrow an established principle from cognitive science: that human social intuition can be modeled as "inverse planning," the task of inferring an agent's (hidden) goals from its (observed) actions. Building on this model, we treat storytelling as "*inverse* inverse planning," the task of choosing actions to manipulate an inverse planner's inferences. Our framework is grounded in literary theory, naturally capturing many storytelling elements from first principles. We give a series of examples to demonstrate this, with supporting evidence from human subject studies.
Inferring the Future by Imagining the Past
May 26, 2023A single panel of a comic book can say a lot: it shows not only where characters currently are, but also where they came from, what their motivations are, and what might happen next. More generally, humans can often infer a complex sequence of past and future events from a *single snapshot image* of an intelligent agent. Building on recent work in cognitive science, we offer a Monte Carlo algorithm for making such inferences. Drawing a connection to Monte Carlo path tracing in computer graphics, we borrow ideas that help us dramatically improve upon prior work in sample efficiency. This allows us to scale to a wide variety of challenging inference problems with only a handful of samples. It also suggests some degree of cognitive plausibility, and indeed we present human subject studies showing that our algorithm matches human intuitions in a variety of domains that previous methods could not scale to.
Factorized Inverse Path Tracing for Efficient and Accurate Material-Lighting Estimation
Apr 12, 2023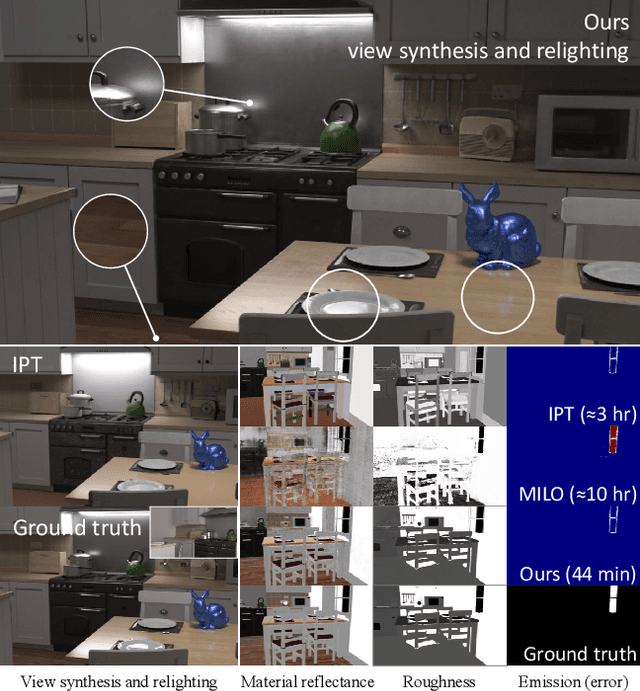

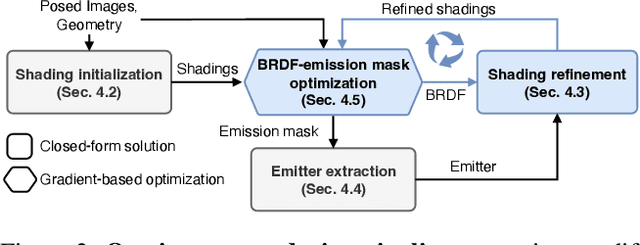

Inverse path tracing has recently been applied to joint material and lighting estimation, given geometry and multi-view HDR observations of an indoor scene. However, it has two major limitations: path tracing is expensive to compute, and ambiguities exist between reflection and emission. We propose a novel Factorized Inverse Path Tracing (FIPT) method which utilizes a factored light transport formulation and finds emitters driven by rendering errors. Our algorithm enables accurate material and lighting optimization faster than previous work, and is more effective at resolving ambiguities. The exhaustive experiments on synthetic scenes show that our method (1) outperforms state-of-the-art indoor inverse rendering and relighting methods particularly in the presence of complex illumination effects; (2) speeds up inverse path tracing optimization to less than an hour. We further demonstrate robustness to noisy inputs through material and lighting estimates that allow plausible relighting in a real scene. The source code is available at: https://github.com/lwwu2/fipt
Differentiable Rendering of Neural SDFs through Reparameterization
Jun 10, 2022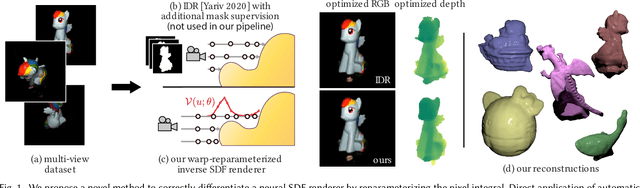

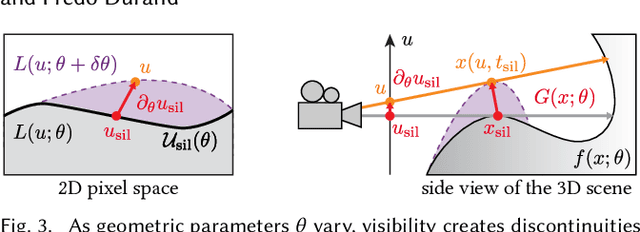
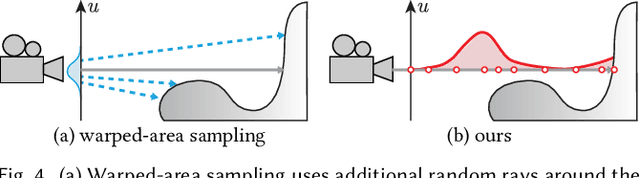
We present a method to automatically compute correct gradients with respect to geometric scene parameters in neural SDF renderers. Recent physically-based differentiable rendering techniques for meshes have used edge-sampling to handle discontinuities, particularly at object silhouettes, but SDFs do not have a simple parametric form amenable to sampling. Instead, our approach builds on area-sampling techniques and develops a continuous warping function for SDFs to account for these discontinuities. Our method leverages the distance to surface encoded in an SDF and uses quadrature on sphere tracer points to compute this warping function. We further show that this can be done by subsampling the points to make the method tractable for neural SDFs. Our differentiable renderer can be used to optimize neural shapes from multi-view images and produces comparable 3D reconstructions to recent SDF-based inverse rendering methods, without the need for 2D segmentation masks to guide the geometry optimization and no volumetric approximations to the geometry.