 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfi: Self Improving Reconstruction Engine via 3D Geometric Feature Alignment
Dec 21, 2025Novel View Synthesis (NVS) has traditionally relied on models with explicit 3D inductive biases combined with known camera parameters from Structure-from-Motion (SfM) beforehand. Recent vision foundation models like VGGT take an orthogonal approach -- 3D knowledge is gained implicitly through training data and loss objectives, enabling feed-forward prediction of both camera parameters and 3D representations directly from a set of uncalibrated images. While flexible, VGGT features lack explicit multi-view geometric consistency, and we find that improving such 3D feature consistency benefits both NVS and pose estimation tasks. We introduce Selfi, a self-improving 3D reconstruction pipeline via feature alignment, transforming a VGGT backbone into a high-fidelity 3D reconstruction engine by leveraging its own outputs as pseudo-ground-truth. Specifically, we train a lightweight feature adapter using a reprojection-based consistency loss, which distills VGGT outputs into a new geometrically-aligned feature space that captures spatial proximity in 3D. This enables state-of-the-art performance in both NVS and camera pose estimation, demonstrating that feature alignment is a highly beneficial step for downstream 3D reasoning.
SplatVoxel: History-Aware Novel View Streaming without Temporal Training
Mar 18, 2025We study the problem of novel view streaming from sparse-view videos, which aims to generate a continuous sequence of high-quality, temporally consistent novel views as new input frames arrive. However, existing novel view synthesis methods struggle with temporal coherence and visual fidelity, leading to flickering and inconsistency. To address these challenges, we introduce history-awareness, leveraging previous frames to reconstruct the scene and improve quality and stability. We propose a hybrid splat-voxel feed-forward scene reconstruction approach that combines Gaussian Splatting to propagate information over time, with a hierarchical voxel grid for temporal fusion. Gaussian primitives are efficiently warped over time using a motion graph that extends 2D tracking models to 3D motion, while a sparse voxel transformer integrates new temporal observations in an error-aware manner. Crucially, our method does not require training on multi-view video datasets, which are currently limited in size and diversity, and can be directly applied to sparse-view video streams in a history-aware manner at inference time. Our approach achieves state-of-the-art performance in both static and streaming scene reconstruction, effectively reducing temporal artifacts and visual artifacts while running at interactive rates (15 fps with 350ms delay) on a single H100 GPU. Project Page: https://19reborn.github.io/SplatVoxel/
Quark: Real-time, High-resolution, and General Neural View Synthesis
Nov 25, 2024We present a novel neural algorithm for performing high-quality, high-resolution, real-time novel view synthesis. From a sparse set of input RGB images or videos streams, our network both reconstructs the 3D scene and renders novel views at 1080p resolution at 30fps on an NVIDIA A100. Our feed-forward network generalizes across a wide variety of datasets and scenes and produces state-of-the-art quality for a real-time method. Our quality approaches, and in some cases surpasses, the quality of some of the top offline methods. In order to achieve these results we use a novel combination of several key concepts, and tie them together into a cohesive and effective algorithm. We build on previous works that represent the scene using semi-transparent layers and use an iterative learned render-and-refine approach to improve those layers. Instead of flat layers, our method reconstructs layered depth maps (LDMs) that efficiently represent scenes with complex depth and occlusions. The iterative update steps are embedded in a multi-scale, UNet-style architecture to perform as much compute as possible at reduced resolution. Within each update step, to better aggregate the information from multiple input views, we use a specialized Transformer-based network component. This allows the majority of the per-input image processing to be performed in the input image space, as opposed to layer space, further increasing efficiency. Finally, due to the real-time nature of our reconstruction and rendering, we dynamically create and discard the internal 3D geometry for each frame, generating the LDM for each view. Taken together, this produces a novel and effective algorithm for view synthesis. Through extensive evaluation, we demonstrate that we achieve state-of-the-art quality at real-time rates. Project page: https://quark-3d.github.io/
Text2Immersion: Generative Immersive Scene with 3D Gaussians
Dec 14, 2023We introduce Text2Immersion, an elegant method for producing high-quality 3D immersive scenes from text prompts. Our proposed pipeline initiates by progressively generating a Gaussian cloud using pre-trained 2D diffusion and depth estimation models. This is followed by a refining stage on the Gaussian cloud, interpolating and refining it to enhance the details of the generated scene. Distinct from prevalent methods that focus on single object or indoor scenes, or employ zoom-out trajectories, our approach generates diverse scenes with various objects, even extending to the creation of imaginary scenes. Consequently, Text2Immersion can have wide-ranging implications for various applications such as virtual reality, game development, and automated content creation. Extensive evaluations demonstrate that our system surpasses other methods in rendering quality and diversity, further progressing towards text-driven 3D scene generation. We will make the source code publicly accessible at the project page.
Neural Free-Viewpoint Relighting for Glossy Indirect Illumination
Jul 12, 2023Precomputed Radiance Transfer (PRT) remains an attractive solution for real-time rendering of complex light transport effects such as glossy global illumination. After precomputation, we can relight the scene with new environment maps while changing viewpoint in real-time. However, practical PRT methods are usually limited to low-frequency spherical harmonic lighting. All-frequency techniques using wavelets are promising but have so far had little practical impact. The curse of dimensionality and much higher data requirements have typically limited them to relighting with fixed view or only direct lighting with triple product integrals. In this paper, we demonstrate a hybrid neural-wavelet PRT solution to high-frequency indirect illumination, including glossy reflection, for relighting with changing view. Specifically, we seek to represent the light transport function in the Haar wavelet basis. For global illumination, we learn the wavelet transport using a small multi-layer perceptron (MLP) applied to a feature field as a function of spatial location and wavelet index, with reflected direction and material parameters being other MLP inputs. We optimize/learn the feature field (compactly represented by a tensor decomposition) and MLP parameters from multiple images of the scene under different lighting and viewing conditions. We demonstrate real-time (512 x 512 at 24 FPS, 800 x 600 at 13 FPS) precomputed rendering of challenging scenes involving view-dependent reflections and even caustics.
NeLF: Neural Light-transport Field for Portrait View Synthesis and Relighting
Jul 26, 2021
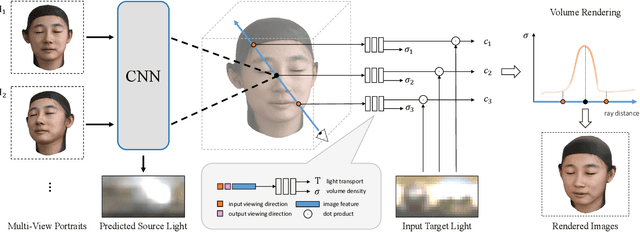
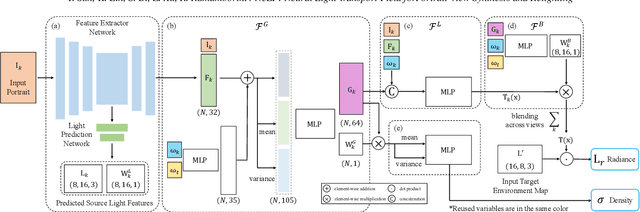
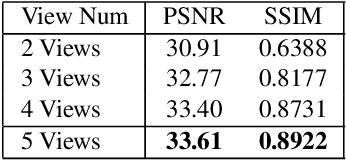
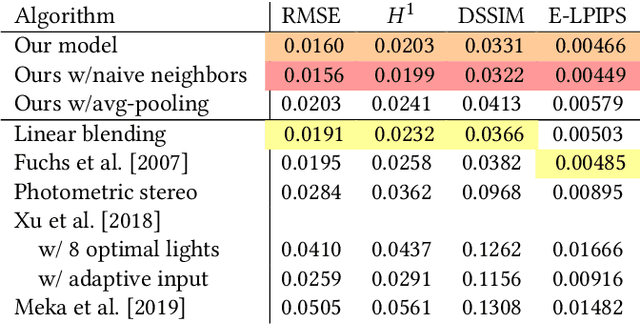
Human portraits exhibit various appearances when observed from different views under different lighting conditions. We can easily imagine how the face will look like in another setup, but computer algorithms still fail on this problem given limited observations. To this end, we present a system for portrait view synthesis and relighting: given multiple portraits, we use a neural network to predict the light-transport field in 3D space, and from the predicted Neural Light-transport Field (NeLF) produce a portrait from a new camera view under a new environmental lighting. Our system is trained on a large number of synthetic models, and can generalize to different synthetic and real portraits under various lighting conditions. Our method achieves simultaneous view synthesis and relighting given multi-view portraits as the input, and achieves state-of-the-art results.
Light Stage Super-Resolution: Continuous High-Frequency Relighting
Oct 17, 2020
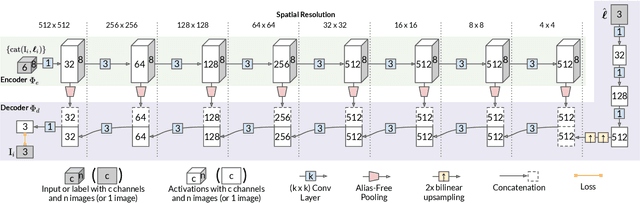
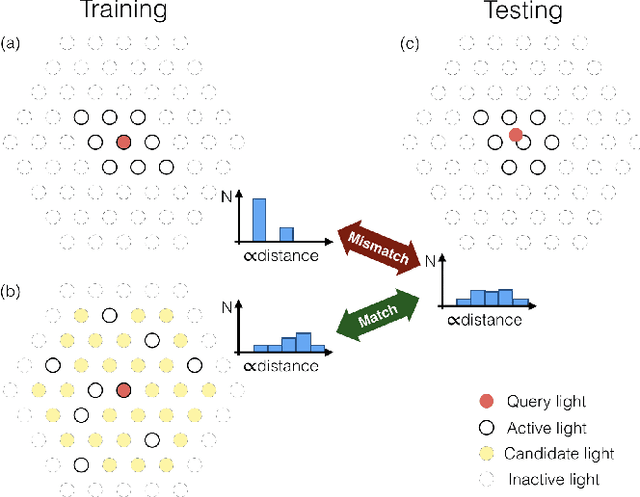
The light stage has been widely used in computer graphics for the past two decades, primarily to enable the relighting of human faces. By capturing the appearance of the human subject under different light sources, one obtains the light transport matrix of that subject, which enables image-based relighting in novel environments. However, due to the finite number of lights in the stage, the light transport matrix only represents a sparse sampling on the entire sphere. As a consequence, relighting the subject with a point light or a directional source that does not coincide exactly with one of the lights in the stage requires interpolation and resampling the images corresponding to nearby lights, and this leads to ghosting shadows, aliased specularities, and other artifacts. To ameliorate these artifacts and produce better results under arbitrary high-frequency lighting, this paper proposes a learning-based solution for the "super-resolution" of scans of human faces taken from a light stage. Given an arbitrary "query" light direction, our method aggregates the captured images corresponding to neighboring lights in the stage, and uses a neural network to synthesize a rendering of the face that appears to be illuminated by a "virtual" light source at the query location. This neural network must circumvent the inherent aliasing and regularity of the light stage data that was used for training, which we accomplish through the use of regularized traditional interpolation methods within our network. Our learned model is able to produce renderings for arbitrary light directions that exhibit realistic shadows and specular highlights, and is able to generalize across a wide variety of subjects.
Photon-Driven Neural Path Guiding
Oct 05, 2020
Although Monte Carlo path tracing is a simple and effective algorithm to synthesize photo-realistic images, it is often very slow to converge to noise-free results when involving complex global illumination. One of the most successful variance-reduction techniques is path guiding, which can learn better distributions for importance sampling to reduce pixel noise. However, previous methods require a large number of path samples to achieve reliable path guiding. We present a novel neural path guiding approach that can reconstruct high-quality sampling distributions for path guiding from a sparse set of samples, using an offline trained neural network. We leverage photons traced from light sources as the input for sampling density reconstruction, which is highly effective for challenging scenes with strong global illumination. To fully make use of our deep neural network, we partition the scene space into an adaptive hierarchical grid, in which we apply our network to reconstruct high-quality sampling distributions for any local region in the scene. This allows for highly efficient path guiding for any path bounce at any location in path tracing. We demonstrate that our photon-driven neural path guiding method can generalize well on diverse challenging testing scenes that are not seen in training. Our approach achieves significantly better rendering results of testing scenes than previous state-of-the-art path guiding methods.
Neural Light Transport for Relighting and View Synthesis
Aug 20, 2020
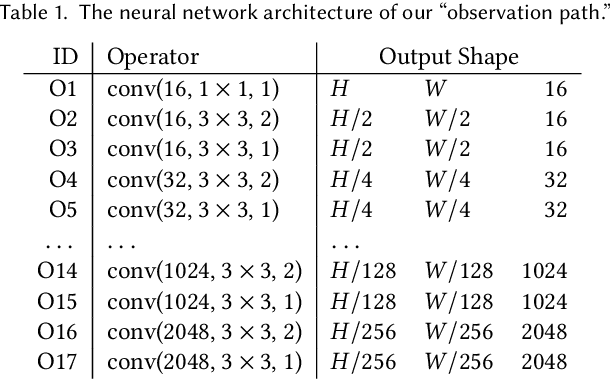

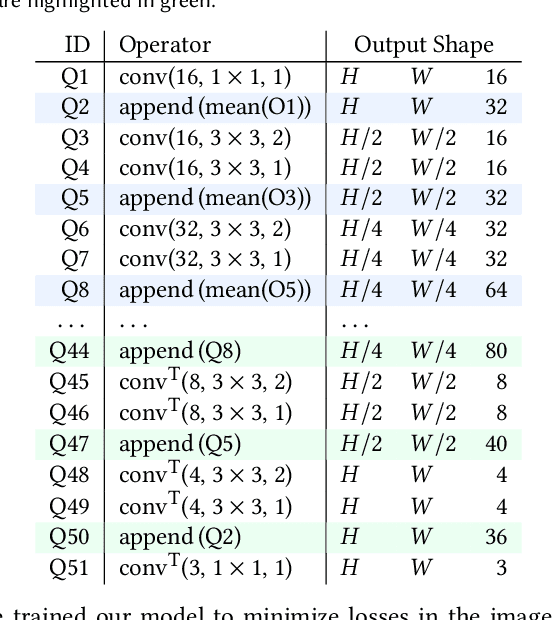
The light transport (LT) of a scene describes how it appears under different lighting and viewing directions, and complete knowledge of a scene's LT enables the synthesis of novel views under arbitrary lighting. In this paper, we focus on image-based LT acquisition, primarily for human bodies within a light stage setup. We propose a semi-parametric approach to learn a neural representation of LT that is embedded in the space of a texture atlas of known geometric properties, and model all non-diffuse and global LT as residuals added to a physically-accurate diffuse base rendering. In particular, we show how to fuse previously seen observations of illuminants and views to synthesize a new image of the same scene under a desired lighting condition from a chosen viewpoint. This strategy allows the network to learn complex material effects (such as subsurface scattering) and global illumination, while guaranteeing the physical correctness of the diffuse LT (such as hard shadows). With this learned LT, one can relight the scene photorealistically with a directional light or an HDRI map, synthesize novel views with view-dependent effects, or do both simultaneously, all in a unified framework using a set of sparse, previously seen observations. Qualitative and quantitative experiments demonstrate that our neural LT (NLT) outperforms state-of-the-art solutions for relighting and view synthesis, without separate treatment for both problems that prior work requires.
Single Image Portrait Relighting
May 02, 2019
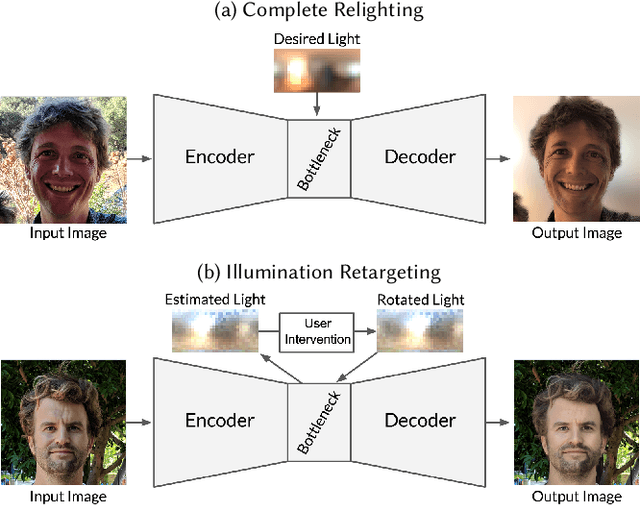
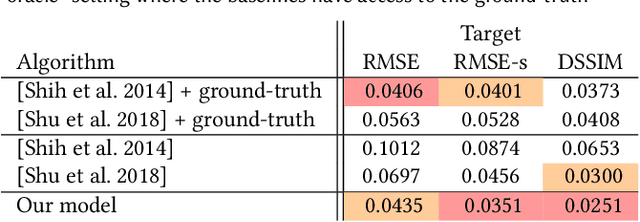

Lighting plays a central role in conveying the essence and depth of the subject in a portrait photograph. Professional photographers will carefully control the lighting in their studio to manipulate the appearance of their subject, while consumer photographers are usually constrained to the illumination of their environment. Though prior works have explored techniques for relighting an image, their utility is usually limited due to requirements of specialized hardware, multiple images of the subject under controlled or known illuminations, or accurate models of geometry and reflectance. To this end, we present a system for portrait relighting: a neural network that takes as input a single RGB image of a portrait taken with a standard cellphone camera in an unconstrained environment, and from that image produces a relit image of that subject as though it were illuminated according to any provided environment map. Our method is trained on a small database of 18 individuals captured under different directional light sources in a controlled light stage setup consisting of a densely sampled sphere of lights. Our proposed technique produces quantitatively superior results on our dataset's validation set compared to prior works, and produces convincing qualitative relighting results on a dataset of hundreds of real-world cellphone portraits. Because our technique can produce a 640 $\times$ 640 image in only 160 milliseconds, it may enable interactive user-facing photographic applications in the future.
* SIGGRAPH 2019 Technical Paper accepted