 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Feature Pyramids for Physics-Informed Neural Networks
May 22, 2026We present an improved neural field architecture for solving partial differential equations (PDEs). Current physics-informed neural networks (PINNs) provide a flexible framework for solving PDEs, but they struggle to achieve highly accurate solutions and require computation that scales poorly with parameter count. Our model, which we call beignet (Bandlimited Embedding with Interpolated Grid Network), replaces the random Fourier feature embedding used by existing PINN models with a trainable multi-resolution Fourier feature pyramid. To query beignet at a continuous coordinate, we use Fourier interpolation at each level of the pyramid to return features at the input coordinate, and then decode this vector with a fully-connected neural network trunk. Our model provides multiple benefits: 1) Spatial derivatives can be computed efficiently by using the chain rule to compose derivatives of the neural network computed with automatic differentiation with derivatives of the feature grid computed spectrally by the Fast Fourier transform (FFT). 2) beignet can achieve higher accuracy in a compute-efficient manner by scaling the parameter count of this Fourier feature pyramid, instead of the less-efficient strategy of scaling the neural network architecture. 3) beignet can directly control the representation bandlimit, resulting in more stable optimization for difficult PDEs. We demonstrate that beignet finds significantly more accurate solutions on PDE benchmarks using fewer parameters than state-of-the-art PINN methods. We further evaluate beignet on the self-similar inviscid Burgers blowup problem and show that it can minimize residuals to near machine precision using Adam, an accuracy regime previously attained only by using computationally expensive higher-order optimizers.
Image Generators are Generalist Vision Learners
Apr 22, 2026Recent works show that image and video generators exhibit zero-shot visual understanding behaviors, in a way reminiscent of how LLMs develop emergent capabilities of language understanding and reasoning from generative pretraining. While it has long been conjectured that the ability to create visual content implies an ability to understand it, there has been limited evidence that generative vision models have developed strong understanding capabilities. In this work, we demonstrate that image generation training serves a role similar to LLM pretraining, and lets models learn powerful and general visual representations that enable SOTA performance on various vision tasks. We introduce Vision Banana, a generalist model built by instruction-tuning Nano Banana Pro (NBP) on a mixture of its original training data alongside a small amount of vision task data. By parameterizing the output space of vision tasks as RGB images, we seamlessly reframe perception as image generation. Our generalist model, Vision Banana, achieves SOTA results on a variety of vision tasks involving both 2D and 3D understanding, beating or rivaling zero-shot domain-specialists, including Segment Anything Model 3 on segmentation tasks, and the Depth Anything series on metric depth estimation. We show that these results can be achieved with lightweight instruction-tuning without sacrificing the base model's image generation capabilities. The superior results suggest that image generation pretraining is a generalist vision learner. It also shows that image generation serves as a unified and universal interface for vision tasks, similar to text generation's role in language understanding and reasoning. We could be witnessing a major paradigm shift for computer vision, where generative vision pretraining takes a central role in building Foundational Vision Models for both generation and understanding.
ZipMap: Linear-Time Stateful 3D Reconstruction with Test-Time Training
Mar 04, 2026Feed-forward transformer models have driven rapid progress in 3D vision, but state-of-the-art methods such as VGGT and $π^3$ have a computational cost that scales quadratically with the number of input images, making them inefficient when applied to large image collections. Sequential-reconstruction approaches reduce this cost but sacrifice reconstruction quality. We introduce ZipMap, a stateful feed-forward model that achieves linear-time, bidirectional 3D reconstruction while matching or surpassing the accuracy of quadratic-time methods. ZipMap employs test-time training layers to zip an entire image collection into a compact hidden scene state in a single forward pass, enabling reconstruction of over 700 frames in under 10 seconds on a single H100 GPU, more than $20\times$ faster than state-of-the-art methods such as VGGT. Moreover, we demonstrate the benefits of having a stateful representation in real-time scene-state querying and its extension to sequential streaming reconstruction.
GR3EN: Generative Relighting for 3D Environments
Jan 22, 2026We present a method for relighting 3D reconstructions of large room-scale environments. Existing solutions for 3D scene relighting often require solving under-determined or ill-conditioned inverse rendering problems, and are as such unable to produce high-quality results on complex real-world scenes. Though recent progress in using generative image and video diffusion models for relighting has been promising, these techniques are either limited to 2D image and video relighting or 3D relighting of individual objects. Our approach enables controllable 3D relighting of room-scale scenes by distilling the outputs of a video-to-video relighting diffusion model into a 3D reconstruction. This side-steps the need to solve a difficult inverse rendering problem, and results in a flexible system that can relight 3D reconstructions of complex real-world scenes. We validate our approach on both synthetic and real-world datasets to show that it can faithfully render novel views of scenes under new lighting conditions.
Bolt3D: Generating 3D Scenes in Seconds
Mar 18, 2025We present a latent diffusion model for fast feed-forward 3D scene generation. Given one or more images, our model Bolt3D directly samples a 3D scene representation in less than seven seconds on a single GPU. We achieve this by leveraging powerful and scalable existing 2D diffusion network architectures to produce consistent high-fidelity 3D scene representations. To train this model, we create a large-scale multiview-consistent dataset of 3D geometry and appearance by applying state-of-the-art dense 3D reconstruction techniques to existing multiview image datasets. Compared to prior multiview generative models that require per-scene optimization for 3D reconstruction, Bolt3D reduces the inference cost by a factor of up to 300 times.
Generative Multiview Relighting for 3D Reconstruction under Extreme Illumination Variation
Dec 19, 2024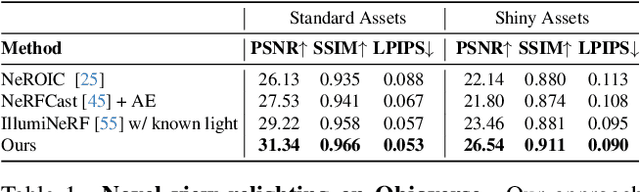
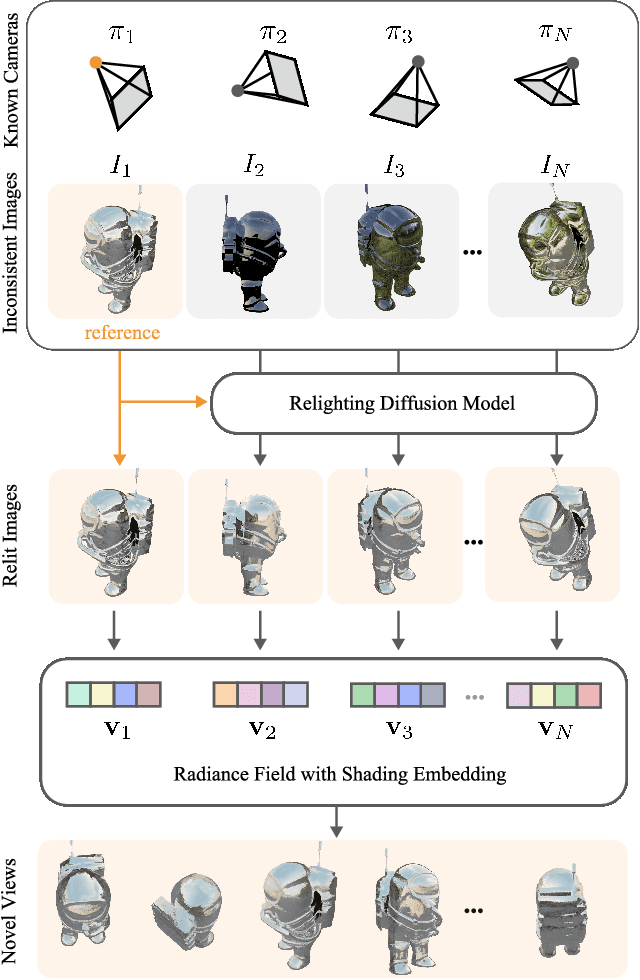
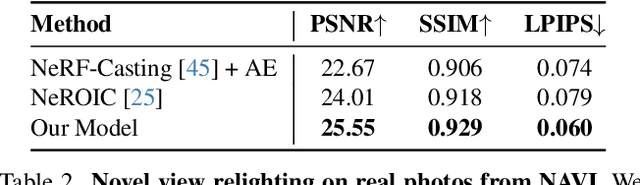

Reconstructing the geometry and appearance of objects from photographs taken in different environments is difficult as the illumination and therefore the object appearance vary across captured images. This is particularly challenging for more specular objects whose appearance strongly depends on the viewing direction. Some prior approaches model appearance variation across images using a per-image embedding vector, while others use physically-based rendering to recover the materials and per-image illumination. Such approaches fail at faithfully recovering view-dependent appearance given significant variation in input illumination and tend to produce mostly diffuse results. We present an approach that reconstructs objects from images taken under different illuminations by first relighting the images under a single reference illumination with a multiview relighting diffusion model and then reconstructing the object's geometry and appearance with a radiance field architecture that is robust to the small remaining inconsistencies among the relit images. We validate our proposed approach on both synthetic and real datasets and demonstrate that it greatly outperforms existing techniques at reconstructing high-fidelity appearance from images taken under extreme illumination variation. Moreover, our approach is particularly effective at recovering view-dependent "shiny" appearance which cannot be reconstructed by prior methods.
SimVS: Simulating World Inconsistencies for Robust View Synthesis
Dec 10, 2024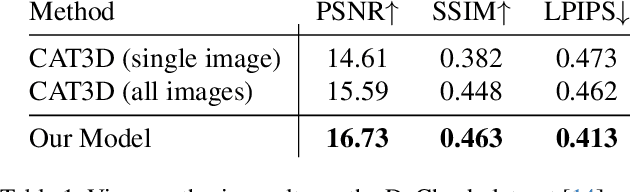



Novel-view synthesis techniques achieve impressive results for static scenes but struggle when faced with the inconsistencies inherent to casual capture settings: varying illumination, scene motion, and other unintended effects that are difficult to model explicitly. We present an approach for leveraging generative video models to simulate the inconsistencies in the world that can occur during capture. We use this process, along with existing multi-view datasets, to create synthetic data for training a multi-view harmonization network that is able to reconcile inconsistent observations into a consistent 3D scene. We demonstrate that our world-simulation strategy significantly outperforms traditional augmentation methods in handling real-world scene variations, thereby enabling highly accurate static 3D reconstructions in the presence of a variety of challenging inconsistencies. Project page: https://alextrevithick.github.io/simvs
CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models
Nov 27, 2024



We present CAT4D, a method for creating 4D (dynamic 3D) scenes from monocular video. CAT4D leverages a multi-view video diffusion model trained on a diverse combination of datasets to enable novel view synthesis at any specified camera poses and timestamps. Combined with a novel sampling approach, this model can transform a single monocular video into a multi-view video, enabling robust 4D reconstruction via optimization of a deformable 3D Gaussian representation. We demonstrate competitive performance on novel view synthesis and dynamic scene reconstruction benchmarks, and highlight the creative capabilities for 4D scene generation from real or generated videos. See our project page for results and interactive demos: \url{cat-4d.github.io}.
Flash Cache: Reducing Bias in Radiance Cache Based Inverse Rendering
Sep 09, 2024State-of-the-art techniques for 3D reconstruction are largely based on volumetric scene representations, which require sampling multiple points to compute the color arriving along a ray. Using these representations for more general inverse rendering -- reconstructing geometry, materials, and lighting from observed images -- is challenging because recursively path-tracing such volumetric representations is expensive. Recent works alleviate this issue through the use of radiance caches: data structures that store the steady-state, infinite-bounce radiance arriving at any point from any direction. However, these solutions rely on approximations that introduce bias into the renderings and, more importantly, into the gradients used for optimization. We present a method that avoids these approximations while remaining computationally efficient. In particular, we leverage two techniques to reduce variance for unbiased estimators of the rendering equation: (1) an occlusion-aware importance sampler for incoming illumination and (2) a fast cache architecture that can be used as a control variate for the radiance from a high-quality, but more expensive, volumetric cache. We show that by removing these biases our approach improves the generality of radiance cache based inverse rendering, as well as increasing quality in the presence of challenging light transport effects such as specular reflections.
InterNeRF: Scaling Radiance Fields via Parameter Interpolation
Jun 17, 2024Neural Radiance Fields (NeRFs) have unmatched fidelity on large, real-world scenes. A common approach for scaling NeRFs is to partition the scene into regions, each of which is assigned its own parameters. When implemented naively, such an approach is limited by poor test-time scaling and inconsistent appearance and geometry. We instead propose InterNeRF, a novel architecture for rendering a target view using a subset of the model's parameters. Our approach enables out-of-core training and rendering, increasing total model capacity with only a modest increase to training time. We demonstrate significant improvements in multi-room scenes while remaining competitive on standard benchmarks.