 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoreographing a World of Dynamic Objects
Jan 07, 2026Dynamic objects in our physical 4D (3D + time) world are constantly evolving, deforming, and interacting with other objects, leading to diverse 4D scene dynamics. In this paper, we present a universal generative pipeline, CHORD, for CHOReographing Dynamic objects and scenes and synthesizing this type of phenomena. Traditional rule-based graphics pipelines to create these dynamics are based on category-specific heuristics, yet are labor-intensive and not scalable. Recent learning-based methods typically demand large-scale datasets, which may not cover all object categories in interest. Our approach instead inherits the universality from the video generative models by proposing a distillation-based pipeline to extract the rich Lagrangian motion information hidden in the Eulerian representations of 2D videos. Our method is universal, versatile, and category-agnostic. We demonstrate its effectiveness by conducting experiments to generate a diverse range of multi-body 4D dynamics, show its advantage compared to existing methods, and demonstrate its applicability in generating robotics manipulation policies. Project page: https://yanzhelyu.github.io/chord
Coupled Diffusion Sampling for Training-Free Multi-View Image Editing
Oct 16, 2025We present an inference-time diffusion sampling method to perform multi-view consistent image editing using pre-trained 2D image editing models. These models can independently produce high-quality edits for each image in a set of multi-view images of a 3D scene or object, but they do not maintain consistency across views. Existing approaches typically address this by optimizing over explicit 3D representations, but they suffer from a lengthy optimization process and instability under sparse view settings. We propose an implicit 3D regularization approach by constraining the generated 2D image sequences to adhere to a pre-trained multi-view image distribution. This is achieved through coupled diffusion sampling, a simple diffusion sampling technique that concurrently samples two trajectories from both a multi-view image distribution and a 2D edited image distribution, using a coupling term to enforce the multi-view consistency among the generated images. We validate the effectiveness and generality of this framework on three distinct multi-view image editing tasks, demonstrating its applicability across various model architectures and highlighting its potential as a general solution for multi-view consistent editing.
Controllable Video Synthesis via Variational Inference
Oct 09, 2025Many video workflows benefit from a mixture of user controls with varying granularity, from exact 4D object trajectories and camera paths to coarse text prompts, while existing video generative models are typically trained for fixed input formats. We develop a video synthesis method that addresses this need and generates samples with high controllability for specified elements while maintaining diversity for under-specified ones. We cast the task as variational inference to approximate a composed distribution, leveraging multiple video generation backbones to account for all task constraints collectively. To address the optimization challenge, we break down the problem into step-wise KL divergence minimization over an annealed sequence of distributions, and further propose a context-conditioned factorization technique that reduces modes in the solution space to circumvent local optima. Experiments suggest that our method produces samples with improved controllability, diversity, and 3D consistency compared to prior works.
Weakly-Supervised Learning of Dense Functional Correspondences
Sep 04, 2025Establishing dense correspondences across image pairs is essential for tasks such as shape reconstruction and robot manipulation. In the challenging setting of matching across different categories, the function of an object, i.e., the effect that an object can cause on other objects, can guide how correspondences should be established. This is because object parts that enable specific functions often share similarities in shape and appearance. We derive the definition of dense functional correspondence based on this observation and propose a weakly-supervised learning paradigm to tackle the prediction task. The main insight behind our approach is that we can leverage vision-language models to pseudo-label multi-view images to obtain functional parts. We then integrate this with dense contrastive learning from pixel correspondences to distill both functional and spatial knowledge into a new model that can establish dense functional correspondence. Further, we curate synthetic and real evaluation datasets as task benchmarks. Our results demonstrate the advantages of our approach over baseline solutions consisting of off-the-shelf self-supervised image representations and grounded vision language models.
Exploring Diffusion with Test-Time Training on Efficient Image Restoration
Jun 17, 2025Image restoration faces challenges including ineffective feature fusion, computational bottlenecks and inefficient diffusion processes. To address these, we propose DiffRWKVIR, a novel framework unifying Test-Time Training (TTT) with efficient diffusion. Our approach introduces three key innovations: (1) Omni-Scale 2D State Evolution extends RWKV's location-dependent parameterization to hierarchical multi-directional 2D scanning, enabling global contextual awareness with linear complexity O(L); (2) Chunk-Optimized Flash Processing accelerates intra-chunk parallelism by 3.2x via contiguous chunk processing (O(LCd) complexity), reducing sequential dependencies and computational overhead; (3) Prior-Guided Efficient Diffusion extracts a compact Image Prior Representation (IPR) in only 5-20 steps, proving 45% faster training/inference than DiffIR while solving computational inefficiency in denoising. Evaluated across super-resolution and inpainting benchmarks (Set5, Set14, BSD100, Urban100, Places365), DiffRWKVIR outperforms SwinIR, HAT, and MambaIR/v2 in PSNR, SSIM, LPIPS, and efficiency metrics. Our method establishes a new paradigm for adaptive, high-efficiency image restoration with optimized hardware utilization.
Product of Experts for Visual Generation
Jun 10, 2025Modern neural models capture rich priors and have complementary knowledge over shared data domains, e.g., images and videos. Integrating diverse knowledge from multiple sources -- including visual generative models, visual language models, and sources with human-crafted knowledge such as graphics engines and physics simulators -- remains under-explored. We propose a Product of Experts (PoE) framework that performs inference-time knowledge composition from heterogeneous models. This training-free approach samples from the product distribution across experts via Annealed Importance Sampling (AIS). Our framework shows practical benefits in image and video synthesis tasks, yielding better controllability than monolithic methods and additionally providing flexible user interfaces for specifying visual generation goals.
Digital Twin Catalog: A Large-Scale Photorealistic 3D Object Digital Twin Dataset
Apr 11, 2025



We introduce Digital Twin Catalog (DTC), a new large-scale photorealistic 3D object digital twin dataset. A digital twin of a 3D object is a highly detailed, virtually indistinguishable representation of a physical object, accurately capturing its shape, appearance, physical properties, and other attributes. Recent advances in neural-based 3D reconstruction and inverse rendering have significantly improved the quality of 3D object reconstruction. Despite these advancements, there remains a lack of a large-scale, digital twin quality real-world dataset and benchmark that can quantitatively assess and compare the performance of different reconstruction methods, as well as improve reconstruction quality through training or fine-tuning. Moreover, to democratize 3D digital twin creation, it is essential to integrate creation techniques with next-generation egocentric computing platforms, such as AR glasses. Currently, there is no dataset available to evaluate 3D object reconstruction using egocentric captured images. To address these gaps, the DTC dataset features 2,000 scanned digital twin-quality 3D objects, along with image sequences captured under different lighting conditions using DSLR cameras and egocentric AR glasses. This dataset establishes the first comprehensive real-world evaluation benchmark for 3D digital twin creation tasks, offering a robust foundation for comparing and improving existing reconstruction methods. The DTC dataset is already released at https://www.projectaria.com/datasets/dtc/ and we will also make the baseline evaluations open-source.
Birth and Death of a Rose
Dec 06, 2024



We study the problem of generating temporal object intrinsics -- temporally evolving sequences of object geometry, reflectance, and texture, such as a blooming rose -- from pre-trained 2D foundation models. Unlike conventional 3D modeling and animation techniques that require extensive manual effort and expertise, we introduce a method that generates such assets with signals distilled from pre-trained 2D diffusion models. To ensure the temporal consistency of object intrinsics, we propose Neural Templates for temporal-state-guided distillation, derived automatically from image features from self-supervised learning. Our method can generate high-quality temporal object intrinsics for several natural phenomena and enable the sampling and controllable rendering of these dynamic objects from any viewpoint, under any environmental lighting conditions, at any time of their lifespan. Project website: https://chen-geng.com/rose4d
Diffusion Self-Distillation for Zero-Shot Customized Image Generation
Nov 27, 2024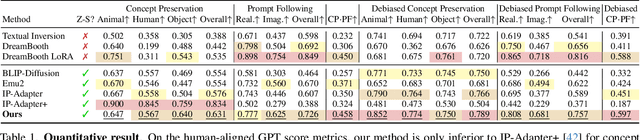
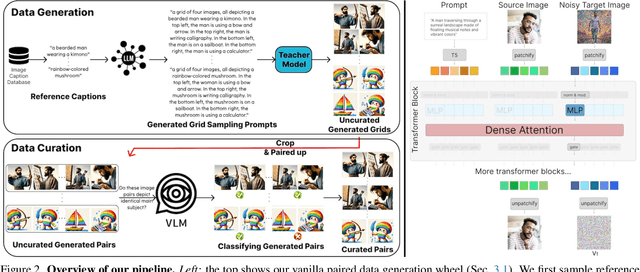
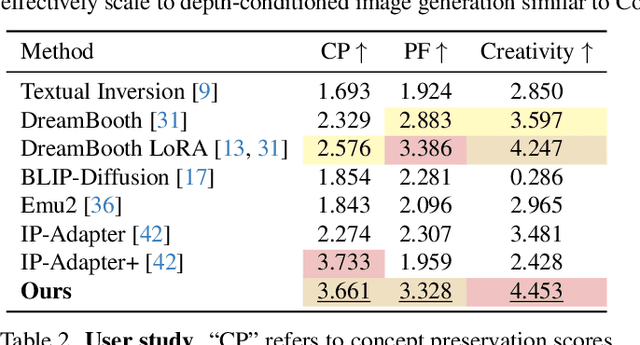

Text-to-image diffusion models produce impressive results but are frustrating tools for artists who desire fine-grained control. For example, a common use case is to create images of a specific instance in novel contexts, i.e., "identity-preserving generation". This setting, along with many other tasks (e.g., relighting), is a natural fit for image+text-conditional generative models. However, there is insufficient high-quality paired data to train such a model directly. We propose Diffusion Self-Distillation, a method for using a pre-trained text-to-image model to generate its own dataset for text-conditioned image-to-image tasks. We first leverage a text-to-image diffusion model's in-context generation ability to create grids of images and curate a large paired dataset with the help of a Visual-Language Model. We then fine-tune the text-to-image model into a text+image-to-image model using the curated paired dataset. We demonstrate that Diffusion Self-Distillation outperforms existing zero-shot methods and is competitive with per-instance tuning techniques on a wide range of identity-preservation generation tasks, without requiring test-time optimization.
The Scene Language: Representing Scenes with Programs, Words, and Embeddings
Oct 22, 2024We introduce the Scene Language, a visual scene representation that concisely and precisely describes the structure, semantics, and identity of visual scenes. It represents a scene with three key components: a program that specifies the hierarchical and relational structure of entities in the scene, words in natural language that summarize the semantic class of each entity, and embeddings that capture the visual identity of each entity. This representation can be inferred from pre-trained language models via a training-free inference technique, given text or image inputs. The resulting scene can be rendered into images using traditional, neural, or hybrid graphics renderers. Together, this forms a robust, automated system for high-quality 3D and 4D scene generation. Compared with existing representations like scene graphs, our proposed Scene Language generates complex scenes with higher fidelity, while explicitly modeling the scene structures to enable precise control and editing.