 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticulate: Feed-Forward 3D Object Articulation
Dec 12, 2025We present Particulate, a feed-forward approach that, given a single static 3D mesh of an everyday object, directly infers all attributes of the underlying articulated structure, including its 3D parts, kinematic structure, and motion constraints. At its core is a transformer network, Part Articulation Transformer, which processes a point cloud of the input mesh using a flexible and scalable architecture to predict all the aforementioned attributes with native multi-joint support. We train the network end-to-end on a diverse collection of articulated 3D assets from public datasets. During inference, Particulate lifts the network's feed-forward prediction to the input mesh, yielding a fully articulated 3D model in seconds, much faster than prior approaches that require per-object optimization. Particulate can also accurately infer the articulated structure of AI-generated 3D assets, enabling full-fledged extraction of articulated 3D objects from a single (real or synthetic) image when combined with an off-the-shelf image-to-3D generator. We further introduce a new challenging benchmark for 3D articulation estimation curated from high-quality public 3D assets, and redesign the evaluation protocol to be more consistent with human preferences. Quantitative and qualitative results show that Particulate significantly outperforms state-of-the-art approaches.
Active View Selector: Fast and Accurate Active View Selection with Cross Reference Image Quality Assessment
Jun 24, 2025We tackle active view selection in novel view synthesis and 3D reconstruction. Existing methods like FisheRF and ActiveNeRF select the next best view by minimizing uncertainty or maximizing information gain in 3D, but they require specialized designs for different 3D representations and involve complex modelling in 3D space. Instead, we reframe this as a 2D image quality assessment (IQA) task, selecting views where current renderings have the lowest quality. Since ground-truth images for candidate views are unavailable, full-reference metrics like PSNR and SSIM are inapplicable, while no-reference metrics, such as MUSIQ and MANIQA, lack the essential multi-view context. Inspired by a recent cross-referencing quality framework CrossScore, we train a model to predict SSIM within a multi-view setup and use it to guide view selection. Our cross-reference IQA framework achieves substantial quantitative and qualitative improvements across standard benchmarks, while being agnostic to 3D representations, and runs 14-33 times faster than previous methods.
On Vanishing Variance in Transformer Length Generalization
Apr 03, 2025It is a widely known issue that Transformers, when trained on shorter sequences, fail to generalize robustly to longer ones at test time. This raises the question of whether Transformer models are real reasoning engines, despite their impressive abilities in mathematical problem solving and code synthesis. In this paper, we offer a vanishing variance perspective on this issue. To the best of our knowledge, we are the first to demonstrate that even for today's frontier models, a longer sequence length results in a decrease in variance in the output of the multi-head attention modules. On the argmax retrieval and dictionary lookup tasks, our experiments show that applying layer normalization after the attention outputs leads to significantly better length generalization. Our analyses attribute this improvement to a reduction-though not a complete elimination-of the distribution shift caused by vanishing variance.
DSO: Aligning 3D Generators with Simulation Feedback for Physical Soundness
Mar 28, 2025Most 3D object generators focus on aesthetic quality, often neglecting physical constraints necessary in applications. One such constraint is that the 3D object should be self-supporting, i.e., remains balanced under gravity. Prior approaches to generating stable 3D objects used differentiable physics simulators to optimize geometry at test-time, which is slow, unstable, and prone to local optima. Inspired by the literature on aligning generative models to external feedback, we propose Direct Simulation Optimization (DSO), a framework to use the feedback from a (non-differentiable) simulator to increase the likelihood that the 3D generator outputs stable 3D objects directly. We construct a dataset of 3D objects labeled with a stability score obtained from the physics simulator. We can then fine-tune the 3D generator using the stability score as the alignment metric, via direct preference optimization (DPO) or direct reward optimization (DRO), a novel objective, which we introduce, to align diffusion models without requiring pairwise preferences. Our experiments show that the fine-tuned feed-forward generator, using either DPO or DRO objective, is much faster and more likely to produce stable objects than test-time optimization. Notably, the DSO framework works even without any ground-truth 3D objects for training, allowing the 3D generator to self-improve by automatically collecting simulation feedback on its own outputs.
DreamHOI: Subject-Driven Generation of 3D Human-Object Interactions with Diffusion Priors
Sep 12, 2024We present DreamHOI, a novel method for zero-shot synthesis of human-object interactions (HOIs), enabling a 3D human model to realistically interact with any given object based on a textual description. This task is complicated by the varying categories and geometries of real-world objects and the scarcity of datasets encompassing diverse HOIs. To circumvent the need for extensive data, we leverage text-to-image diffusion models trained on billions of image-caption pairs. We optimize the articulation of a skinned human mesh using Score Distillation Sampling (SDS) gradients obtained from these models, which predict image-space edits. However, directly backpropagating image-space gradients into complex articulation parameters is ineffective due to the local nature of such gradients. To overcome this, we introduce a dual implicit-explicit representation of a skinned mesh, combining (implicit) neural radiance fields (NeRFs) with (explicit) skeleton-driven mesh articulation. During optimization, we transition between implicit and explicit forms, grounding the NeRF generation while refining the mesh articulation. We validate our approach through extensive experiments, demonstrating its effectiveness in generating realistic HOIs.
Puppet-Master: Scaling Interactive Video Generation as a Motion Prior for Part-Level Dynamics
Aug 08, 2024



We present Puppet-Master, an interactive video generative model that can serve as a motion prior for part-level dynamics. At test time, given a single image and a sparse set of motion trajectories (i.e., drags), Puppet-Master can synthesize a video depicting realistic part-level motion faithful to the given drag interactions. This is achieved by fine-tuning a large-scale pre-trained video diffusion model, for which we propose a new conditioning architecture to inject the dragging control effectively. More importantly, we introduce the all-to-first attention mechanism, a drop-in replacement for the widely adopted spatial attention modules, which significantly improves generation quality by addressing the appearance and background issues in existing models. Unlike other motion-conditioned video generators that are trained on in-the-wild videos and mostly move an entire object, Puppet-Master is learned from Objaverse-Animation-HQ, a new dataset of curated part-level motion clips. We propose a strategy to automatically filter out sub-optimal animations and augment the synthetic renderings with meaningful motion trajectories. Puppet-Master generalizes well to real images across various categories and outperforms existing methods in a zero-shot manner on a real-world benchmark. See our project page for more results: vgg-puppetmaster.github.io.
DragAPart: Learning a Part-Level Motion Prior for Articulated Objects
Mar 22, 2024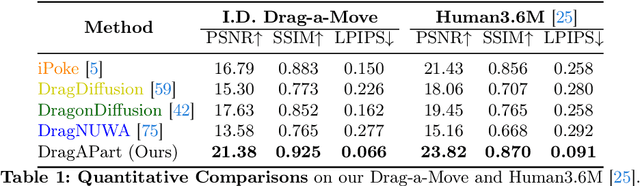
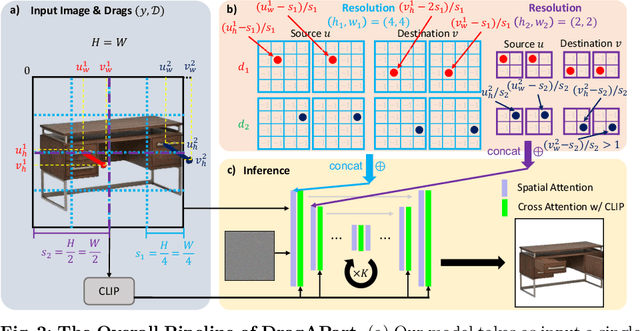
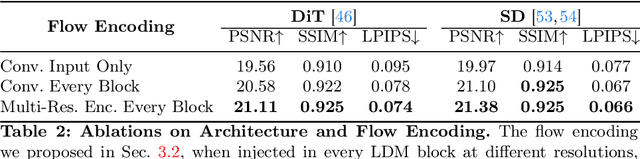

We introduce DragAPart, a method that, given an image and a set of drags as input, can generate a new image of the same object in a new state, compatible with the action of the drags. Differently from prior works that focused on repositioning objects, DragAPart predicts part-level interactions, such as opening and closing a drawer. We study this problem as a proxy for learning a generalist motion model, not restricted to a specific kinematic structure or object category. To this end, we start from a pre-trained image generator and fine-tune it on a new synthetic dataset, Drag-a-Move, which we introduce. Combined with a new encoding for the drags and dataset randomization, the new model generalizes well to real images and different categories. Compared to prior motion-controlled generators, we demonstrate much better part-level motion understanding.
Learning the 3D Fauna of the Web
Jan 04, 2024Learning 3D models of all animals on the Earth requires massively scaling up existing solutions. With this ultimate goal in mind, we develop 3D-Fauna, an approach that learns a pan-category deformable 3D animal model for more than 100 animal species jointly. One crucial bottleneck of modeling animals is the limited availability of training data, which we overcome by simply learning from 2D Internet images. We show that prior category-specific attempts fail to generalize to rare species with limited training images. We address this challenge by introducing the Semantic Bank of Skinned Models (SBSM), which automatically discovers a small set of base animal shapes by combining geometric inductive priors with semantic knowledge implicitly captured by an off-the-shelf self-supervised feature extractor. To train such a model, we also contribute a new large-scale dataset of diverse animal species. At inference time, given a single image of any quadruped animal, our model reconstructs an articulated 3D mesh in a feed-forward fashion within seconds.
Farm3D: Learning Articulated 3D Animals by Distilling 2D Diffusion
Apr 20, 2023We present Farm3D, a method to learn category-specific 3D reconstructors for articulated objects entirely from "free" virtual supervision from a pre-trained 2D diffusion-based image generator. Recent approaches can learn, given a collection of single-view images of an object category, a monocular network to predict the 3D shape, albedo, illumination and viewpoint of any object occurrence. We propose a framework using an image generator like Stable Diffusion to generate virtual training data for learning such a reconstruction network from scratch. Furthermore, we include the diffusion model as a score to further improve learning. The idea is to randomise some aspects of the reconstruction, such as viewpoint and illumination, generating synthetic views of the reconstructed 3D object, and have the 2D network assess the quality of the resulting image, providing feedback to the reconstructor. Different from work based on distillation which produces a single 3D asset for each textual prompt in hours, our approach produces a monocular reconstruction network that can output a controllable 3D asset from a given image, real or generated, in only seconds. Our network can be used for analysis, including monocular reconstruction, or for synthesis, generating articulated assets for real-time applications such as video games.
MagicPony: Learning Articulated 3D Animals in the Wild
Nov 22, 2022We consider the problem of learning a function that can estimate the 3D shape, articulation, viewpoint, texture, and lighting of an articulated animal like a horse, given a single test image. We present a new method, dubbed MagicPony, that learns this function purely from in-the-wild single-view images of the object category, with minimal assumptions about the topology of deformation. At its core is an implicit-explicit representation of articulated shape and appearance, combining the strengths of neural fields and meshes. In order to help the model understand an object's shape and pose, we distil the knowledge captured by an off-the-shelf self-supervised vision transformer and fuse it into the 3D model. To overcome common local optima in viewpoint estimation, we further introduce a new viewpoint sampling scheme that comes at no added training cost. Compared to prior works, we show significant quantitative and qualitative improvements on this challenging task. The model also demonstrates excellent generalisation in reconstructing abstract drawings and artefacts, despite the fact that it is only trained on real images.