 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Classifier-Free Diffusion Guidance via Online Feedback
Sep 19, 2025



Classifier-free guidance (CFG) is a cornerstone of text-to-image diffusion models, yet its effectiveness is limited by the use of static guidance scales. This "one-size-fits-all" approach fails to adapt to the diverse requirements of different prompts; moreover, prior solutions like gradient-based correction or fixed heuristic schedules introduce additional complexities and fail to generalize. In this work, we challeng this static paradigm by introducing a framework for dynamic CFG scheduling. Our method leverages online feedback from a suite of general-purpose and specialized small-scale latent-space evaluations, such as CLIP for alignment, a discriminator for fidelity and a human preference reward model, to assess generation quality at each step of the reverse diffusion process. Based on this feedback, we perform a greedy search to select the optimal CFG scale for each timestep, creating a unique guidance schedule tailored to every prompt and sample. We demonstrate the effectiveness of our approach on both small-scale models and the state-of-the-art Imagen 3, showing significant improvements in text alignment, visual quality, text rendering and numerical reasoning. Notably, when compared against the default Imagen 3 baseline, our method achieves up to 53.8% human preference win-rate for overall preference, a figure that increases up to to 55.5% on prompts targeting specific capabilities like text rendering. Our work establishes that the optimal guidance schedule is inherently dynamic and prompt-dependent, and provides an efficient and generalizable framework to achieve it.
SynCity: Training-Free Generation of 3D Worlds
Mar 20, 2025We address the challenge of generating 3D worlds from textual descriptions. We propose SynCity, a training- and optimization-free approach, which leverages the geometric precision of pre-trained 3D generative models and the artistic versatility of 2D image generators to create large, high-quality 3D spaces. While most 3D generative models are object-centric and cannot generate large-scale worlds, we show how 3D and 2D generators can be combined to generate ever-expanding scenes. Through a tile-based approach, we allow fine-grained control over the layout and the appearance of scenes. The world is generated tile-by-tile, and each new tile is generated within its world-context and then fused with the scene. SynCity generates compelling and immersive scenes that are rich in detail and diversity.
SHIC: Shape-Image Correspondences with no Keypoint Supervision
Jul 26, 2024Canonical surface mapping generalizes keypoint detection by assigning each pixel of an object to a corresponding point in a 3D template. Popularised by DensePose for the analysis of humans, authors have since attempted to apply the concept to more categories, but with limited success due to the high cost of manual supervision. In this work, we introduce SHIC, a method to learn canonical maps without manual supervision which achieves better results than supervised methods for most categories. Our idea is to leverage foundation computer vision models such as DINO and Stable Diffusion that are open-ended and thus possess excellent priors over natural categories. SHIC reduces the problem of estimating image-to-template correspondences to predicting image-to-image correspondences using features from the foundation models. The reduction works by matching images of the object to non-photorealistic renders of the template, which emulates the process of collecting manual annotations for this task. These correspondences are then used to supervise high-quality canonical maps for any object of interest. We also show that image generators can further improve the realism of the template views, which provide an additional source of supervision for the model.
What an Elegant Bridge: Multilingual LLMs are Biased Similarly in Different Languages
Jul 12, 2024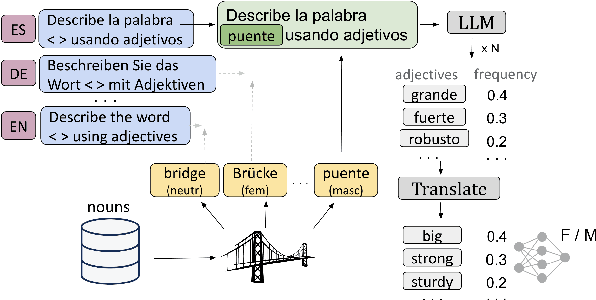

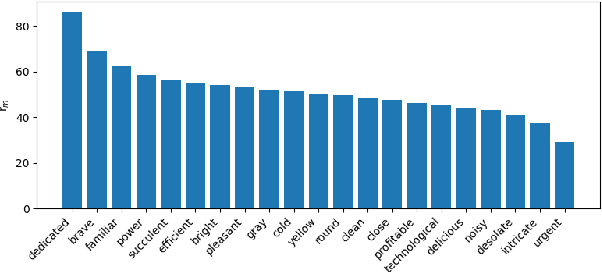

This paper investigates biases of Large Language Models (LLMs) through the lens of grammatical gender. Drawing inspiration from seminal works in psycholinguistics, particularly the study of gender's influence on language perception, we leverage multilingual LLMs to revisit and expand upon the foundational experiments of Boroditsky (2003). Employing LLMs as a novel method for examining psycholinguistic biases related to grammatical gender, we prompt a model to describe nouns with adjectives in various languages, focusing specifically on languages with grammatical gender. In particular, we look at adjective co-occurrences across gender and languages, and train a binary classifier to predict grammatical gender given adjectives an LLM uses to describe a noun. Surprisingly, we find that a simple classifier can not only predict noun gender above chance but also exhibit cross-language transferability. We show that while LLMs may describe words differently in different languages, they are biased similarly.
HelloFresh: LLM Evaluations on Streams of Real-World Human Editorial Actions across X Community Notes and Wikipedia edits
Jun 05, 2024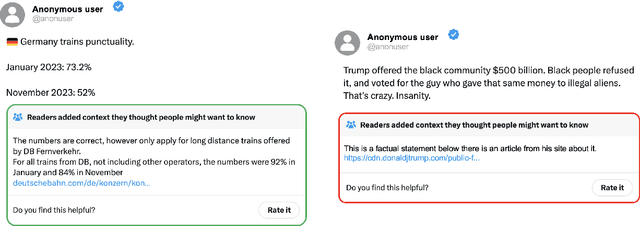


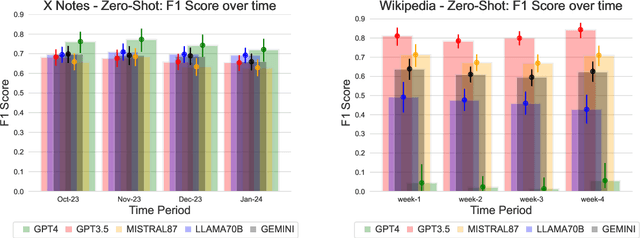
Benchmarks have been essential for driving progress in machine learning. A better understanding of LLM capabilities on real world tasks is vital for safe development. Designing adequate LLM benchmarks is challenging: Data from real-world tasks is hard to collect, public availability of static evaluation data results in test data contamination and benchmark overfitting, and periodically generating new evaluation data is tedious and may result in temporally inconsistent results. We introduce HelloFresh, based on continuous streams of real-world data generated by intrinsically motivated human labelers. It covers recent events from X (formerly Twitter) community notes and edits of Wikipedia pages, mitigating the risk of test data contamination and benchmark overfitting. Any X user can propose an X note to add additional context to a misleading post (formerly tweet); if the community classifies it as helpful, it is shown with the post. Similarly, Wikipedia relies on community-based consensus, allowing users to edit articles or revert edits made by other users. Verifying whether an X note is helpful or whether a Wikipedia edit should be accepted are hard tasks that require grounding by querying the web. We backtest state-of-the-art LLMs supplemented with simple web search access and find that HelloFresh yields a temporally consistent ranking. To enable continuous evaluation on HelloFresh, we host a public leaderboard and periodically updated evaluation data at https://tinyurl.com/hello-fresh-LLM.
PaperQA: Retrieval-Augmented Generative Agent for Scientific Research
Dec 14, 2023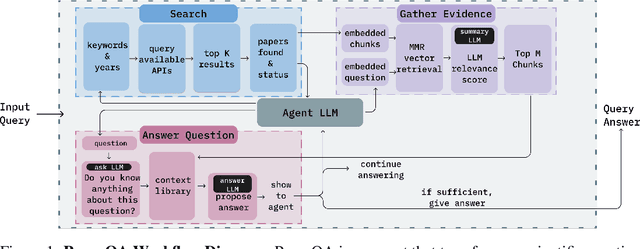



Large Language Models (LLMs) generalize well across language tasks, but suffer from hallucinations and uninterpretability, making it difficult to assess their accuracy without ground-truth. Retrieval-Augmented Generation (RAG) models have been proposed to reduce hallucinations and provide provenance for how an answer was generated. Applying such models to the scientific literature may enable large-scale, systematic processing of scientific knowledge. We present PaperQA, a RAG agent for answering questions over the scientific literature. PaperQA is an agent that performs information retrieval across full-text scientific articles, assesses the relevance of sources and passages, and uses RAG to provide answers. Viewing this agent as a question answering model, we find it exceeds performance of existing LLMs and LLM agents on current science QA benchmarks. To push the field closer to how humans perform research on scientific literature, we also introduce LitQA, a more complex benchmark that requires retrieval and synthesis of information from full-text scientific papers across the literature. Finally, we demonstrate PaperQA's matches expert human researchers on LitQA.
BioPlanner: Automatic Evaluation of LLMs on Protocol Planning in Biology
Oct 16, 2023



The ability to automatically generate accurate protocols for scientific experiments would represent a major step towards the automation of science. Large Language Models (LLMs) have impressive capabilities on a wide range of tasks, such as question answering and the generation of coherent text and code. However, LLMs can struggle with multi-step problems and long-term planning, which are crucial for designing scientific experiments. Moreover, evaluation of the accuracy of scientific protocols is challenging, because experiments can be described correctly in many different ways, require expert knowledge to evaluate, and cannot usually be executed automatically. Here we present an automatic evaluation framework for the task of planning experimental protocols, and we introduce BioProt: a dataset of biology protocols with corresponding pseudocode representations. To measure performance on generating scientific protocols, we use an LLM to convert a natural language protocol into pseudocode, and then evaluate an LLM's ability to reconstruct the pseudocode from a high-level description and a list of admissible pseudocode functions. We evaluate GPT-3 and GPT-4 on this task and explore their robustness. We externally validate the utility of pseudocode representations of text by generating accurate novel protocols using retrieved pseudocode, and we run a generated protocol successfully in our biological laboratory. Our framework is extensible to the evaluation and improvement of language model planning abilities in other areas of science or other areas that lack automatic evaluation.
VisoGender: A dataset for benchmarking gender bias in image-text pronoun resolution
Jun 21, 2023



We introduce VisoGender, a novel dataset for benchmarking gender bias in vision-language models. We focus on occupation-related gender biases, inspired by Winograd and Winogender schemas, where each image is associated with a caption containing a pronoun relationship of subjects and objects in the scene. VisoGender is balanced by gender representation in professional roles, supporting bias evaluation in two ways: i) resolution bias, where we evaluate the difference between gender resolution accuracies for men and women and ii) retrieval bias, where we compare ratios of male and female professionals retrieved for a gender-neutral search query. We benchmark several state-of-the-art vision-language models and find that they lack the reasoning abilities to correctly resolve gender in complex scenes. While the direction and magnitude of gender bias depends on the task and the model being evaluated, captioning models generally are more accurate and less biased than CLIP-like models. Dataset and code are available at https://github.com/oxai/visogender
Balancing the Picture: Debiasing Vision-Language Datasets with Synthetic Contrast Sets
May 24, 2023Vision-language models are growing in popularity and public visibility to generate, edit, and caption images at scale; but their outputs can perpetuate and amplify societal biases learned during pre-training on uncurated image-text pairs from the internet. Although debiasing methods have been proposed, we argue that these measurements of model bias lack validity due to dataset bias. We demonstrate there are spurious correlations in COCO Captions, the most commonly used dataset for evaluating bias, between background context and the gender of people in-situ. This is problematic because commonly-used bias metrics (such as Bias@K) rely on per-gender base rates. To address this issue, we propose a novel dataset debiasing pipeline to augment the COCO dataset with synthetic, gender-balanced contrast sets, where only the gender of the subject is edited and the background is fixed. However, existing image editing methods have limitations and sometimes produce low-quality images; so, we introduce a method to automatically filter the generated images based on their similarity to real images. Using our balanced synthetic contrast sets, we benchmark bias in multiple CLIP-based models, demonstrating how metrics are skewed by imbalance in the original COCO images. Our results indicate that the proposed approach improves the validity of the evaluation, ultimately contributing to more realistic understanding of bias in vision-language models.
What does CLIP know about a red circle? Visual prompt engineering for VLMs
Apr 13, 2023



Large-scale Vision-Language Models, such as CLIP, learn powerful image-text representations that have found numerous applications, from zero-shot classification to text-to-image generation. Despite that, their capabilities for solving novel discriminative tasks via prompting fall behind those of large language models, such as GPT-3. Here we explore the idea of visual prompt engineering for solving computer vision tasks beyond classification by editing in image space instead of text. In particular, we discover an emergent ability of CLIP, where, by simply drawing a red circle around an object, we can direct the model's attention to that region, while also maintaining global information. We show the power of this simple approach by achieving state-of-the-art in zero-shot referring expressions comprehension and strong performance in keypoint localization tasks. Finally, we draw attention to some potential ethical concerns of large language-vision models.