 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster, Cheaper, More Accurate: Specialised Knowledge Tracing Models Outperform LLMs
Mar 03, 2026Predicting future student responses to questions is particularly valuable for educational learning platforms where it enables effective interventions. One of the key approaches to do this has been through the use of knowledge tracing (KT) models. These are small, domain-specific, temporal models trained on student question-response data. KT models are optimised for high accuracy on specific educational domains and have fast inference and scalable deployments. The rise of Large Language Models (LLMs) motivates us to ask the following questions: (1) How well can LLMs perform at predicting students' future responses to questions? (2) Are LLMs scalable for this domain? (3) How do LLMs compare to KT models on this domain-specific task? In this paper, we compare multiple LLMs and KT models across predictive performance, deployment cost, and inference speed to answer the above questions. We show that KT models outperform LLMs with respect to accuracy and F1 scores on this domain-specific task. Further, we demonstrate that LLMs are orders of magnitude slower than KT models and cost orders of magnitude more to deploy. This highlights the importance of domain-specific models for education prediction tasks and the fact that current closed source LLMs should not be used as a universal solution for all tasks.
Misconception Diagnosis From Student-Tutor Dialogue: Generate, Retrieve, Rerank
Feb 02, 2026Timely and accurate identification of student misconceptions is key to improving learning outcomes and pre-empting the compounding of student errors. However, this task is highly dependent on the effort and intuition of the teacher. In this work, we present a novel approach for detecting misconceptions from student-tutor dialogues using large language models (LLMs). First, we use a fine-tuned LLM to generate plausible misconceptions, and then retrieve the most promising candidates among these using embedding similarity with the input dialogue. These candidates are then assessed and re-ranked by another fine-tuned LLM to improve misconception relevance. Empirically, we evaluate our system on real dialogues from an educational tutoring platform. We consider multiple base LLM models including LLaMA, Qwen and Claude on zero-shot and fine-tuned settings. We find that our approach improves predictive performance over baseline models and that fine-tuning improves both generated misconception quality and can outperform larger closed-source models. Finally, we conduct ablation studies to both validate the importance of our generation and reranking steps on misconception generation quality.
Augmenting Human-Annotated Training Data with Large Language Model Generation and Distillation in Open-Response Assessment
Jan 15, 2025


Large Language Models (LLMs) like GPT-4o can help automate text classification tasks at low cost and scale. However, there are major concerns about the validity and reliability of LLM outputs. By contrast, human coding is generally more reliable but expensive to procure at scale. In this study, we propose a hybrid solution to leverage the strengths of both. We combine human-coded data and synthetic LLM-produced data to fine-tune a classical machine learning classifier, distilling both into a smaller BERT model. We evaluate our method on a human-coded test set as a validity measure for LLM output quality. In three experiments, we systematically vary LLM-generated samples' size, variety, and consistency, informed by best practices in LLM tuning. Our findings indicate that augmenting datasets with synthetic samples improves classifier performance, with optimal results achieved at an 80% synthetic to 20% human-coded data ratio. Lower temperature settings of 0.3, corresponding to less variability in LLM generations, produced more stable improvements but also limited model learning from augmented samples. In contrast, higher temperature settings (0.7 and above) introduced greater variability in performance estimates and, at times, lower performance. Hence, LLMs may produce more uniform output that classifiers overfit to earlier or produce more diverse output that runs the risk of deteriorating model performance through information irrelevant to the prediction task. Filtering out inconsistent synthetic samples did not enhance performance. We conclude that integrating human and LLM-generated data to improve text classification models in assessment offers a scalable solution that leverages both the accuracy of human coding and the variety of LLM outputs.
BioPlanner: Automatic Evaluation of LLMs on Protocol Planning in Biology
Oct 16, 2023



The ability to automatically generate accurate protocols for scientific experiments would represent a major step towards the automation of science. Large Language Models (LLMs) have impressive capabilities on a wide range of tasks, such as question answering and the generation of coherent text and code. However, LLMs can struggle with multi-step problems and long-term planning, which are crucial for designing scientific experiments. Moreover, evaluation of the accuracy of scientific protocols is challenging, because experiments can be described correctly in many different ways, require expert knowledge to evaluate, and cannot usually be executed automatically. Here we present an automatic evaluation framework for the task of planning experimental protocols, and we introduce BioProt: a dataset of biology protocols with corresponding pseudocode representations. To measure performance on generating scientific protocols, we use an LLM to convert a natural language protocol into pseudocode, and then evaluate an LLM's ability to reconstruct the pseudocode from a high-level description and a list of admissible pseudocode functions. We evaluate GPT-3 and GPT-4 on this task and explore their robustness. We externally validate the utility of pseudocode representations of text by generating accurate novel protocols using retrieved pseudocode, and we run a generated protocol successfully in our biological laboratory. Our framework is extensible to the evaluation and improvement of language model planning abilities in other areas of science or other areas that lack automatic evaluation.
PlanE: Representation Learning over Planar Graphs
Jul 03, 2023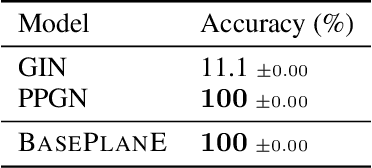
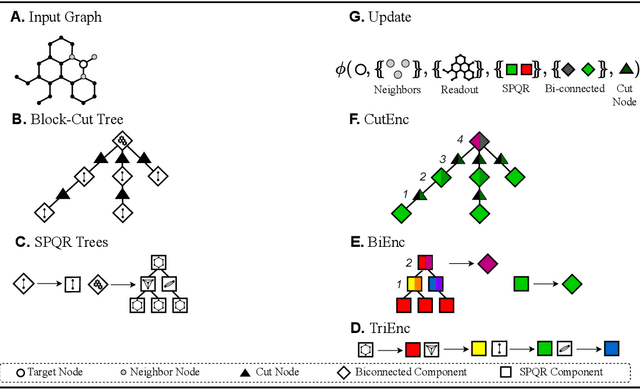
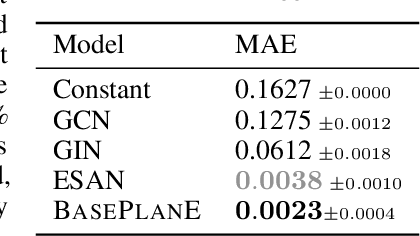
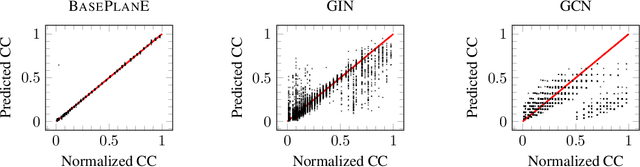
Graph neural networks are prominent models for representation learning over graphs, where the idea is to iteratively compute representations of nodes of an input graph through a series of transformations in such a way that the learned graph function is isomorphism invariant on graphs, which makes the learned representations graph invariants. On the other hand, it is well-known that graph invariants learned by these class of models are incomplete: there are pairs of non-isomorphic graphs which cannot be distinguished by standard graph neural networks. This is unsurprising given the computational difficulty of graph isomorphism testing on general graphs, but the situation begs to differ for special graph classes, for which efficient graph isomorphism testing algorithms are known, such as planar graphs. The goal of this work is to design architectures for efficiently learning complete invariants of planar graphs. Inspired by the classical planar graph isomorphism algorithm of Hopcroft and Tarjan, we propose PlanE as a framework for planar representation learning. PlanE includes architectures which can learn complete invariants over planar graphs while remaining practically scalable. We empirically validate the strong performance of the resulting model architectures on well-known planar graph benchmarks, achieving multiple state-of-the-art results.
Shortest Path Networks for Graph Property Prediction
Jun 02, 2022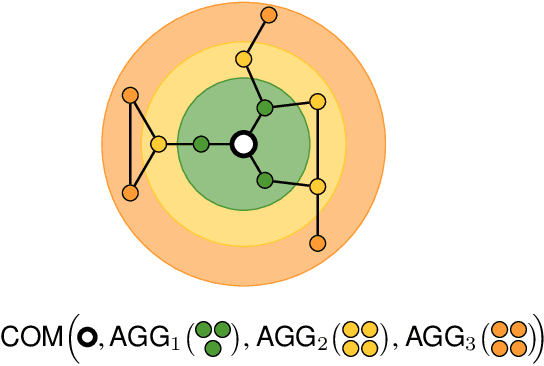
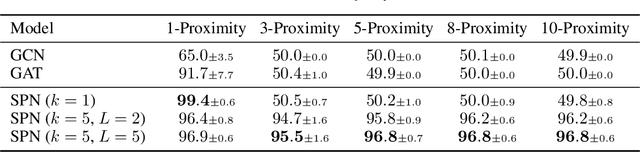
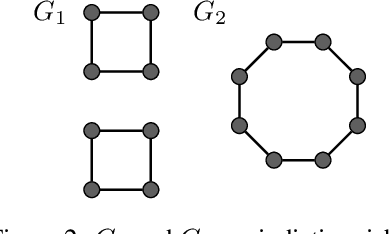
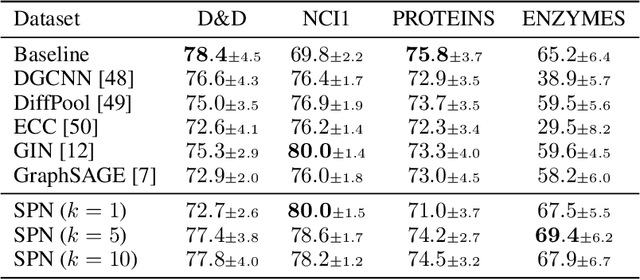
Most graph neural network models rely on a particular message passing paradigm, where the idea is to iteratively propagate node representations of a graph to each node in the direct neighborhood. While very prominent, this paradigm leads to information propagation bottlenecks, as information is repeatedly compressed at intermediary node representations, which causes loss of information, making it practically impossible to gather meaningful signals from distant nodes. To address this issue, we propose shortest path message passing neural networks, where the node representations of a graph are propagated to each node in the shortest path neighborhoods. In this setting, nodes can directly communicate between each other even if they are not neighbors, breaking the information bottleneck and hence leading to more adequately learned representations. Theoretically, our framework generalizes message passing neural networks, resulting in provably more expressive models. Empirically, we verify the capacity of a basic model of this framework on dedicated synthetic experiments, and on real-world graph classification and regression benchmarks, obtaining several state-of-the-art results.
Temporal Knowledge Graph Completion using Box Embeddings
Sep 18, 2021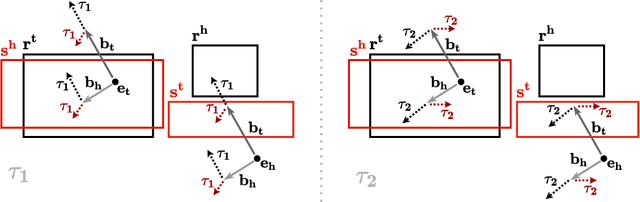

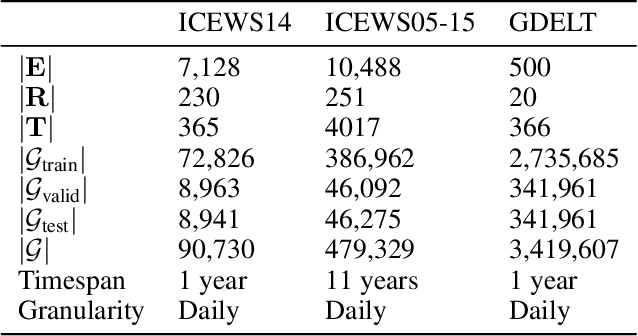
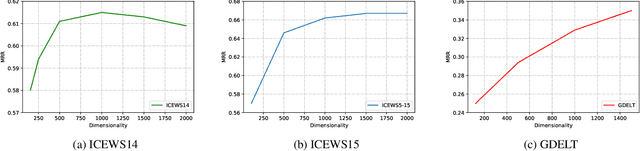
Knowledge graph completion is the task of inferring missing facts based on existing data in a knowledge graph. Temporal knowledge graph completion (TKGC) is an extension of this task to temporal knowledge graphs, where each fact is additionally associated with a time stamp. Current approaches for TKGC primarily build on existing embedding models which are developed for (static) knowledge graph completion, and extend these models to incorporate time, where the idea is to learn latent representations for entities, relations, and timestamps and then use the learned representations to predict missing facts at various time steps. In this paper, we propose BoxTE, a box embedding model for TKGC, building on the static knowledge graph embedding model BoxE. We show that BoxTE is fully expressive, and possesses strong inductive capacity in the temporal setting. We then empirically evaluate our model and show that it achieves state-of-the-art results on several TKGC benchmarks.
Node Classification Meets Link Prediction on Knowledge Graphs
Jun 14, 2021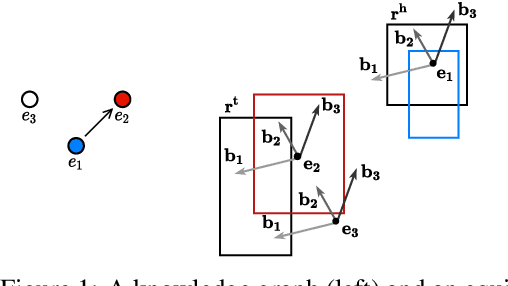

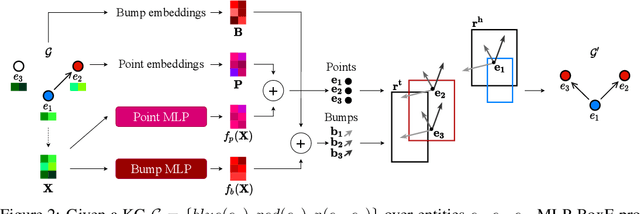

Node classification and link prediction are widely studied tasks in graph representation learning. While both transductive node classification and link prediction operate over a single input graph, they are studied in isolation so far, which leads to discrepancies. Node classification models take as input a graph with node features and incomplete node labels, and implicitly assume that the input graph is relationally complete, i.e., no edges are missing from the input graph. This is in sharp contrast with link prediction models that are solely motivated by the relational incompleteness of the input graph which does not have any node features. We propose a unifying perspective and study the problems of (i) transductive node classification over incomplete graphs and (ii) link prediction over graphs with node features. We propose an extension to an existing box embedding model, and show that this model is fully expressive, and can solve both of these tasks in an end-to-end fashion. To empirically evaluate our model, we construct a knowledge graph with node features, which is challenging both for node classification and link prediction. Our model performs very strongly when compared to the respective state-of-the-art models for node classification and link prediction on this dataset and shows the importance of a unified perspective for node classification and link prediction on knowledge graphs.
The Surprising Power of Graph Neural Networks with Random Node Initialization
Oct 02, 2020

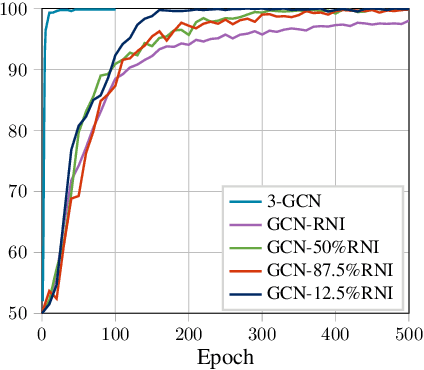

Graph neural networks (GNNs) are effective models for representation learning on graph-structured data. However, standard GNNs are limited in their expressive power, as they cannot distinguish graphs beyond the capability of the Weisfeiler-Leman (1-WL) graph isomorphism heuristic. This limitation motivated a large body of work, including higher-order GNNs, which are provably more powerful models. To date, higher-order invariant and equivariant networks are the only models with known universality results, but these results are practically hindered by prohibitive computational complexity. Thus, despite their limitations, standard GNNs are commonly used, due to their strong practical performance. In practice, GNNs have shown a promising performance when enhanced with random node initialization (RNI), where the idea is to train and run the models with randomized initial node features. In this paper, we analyze the expressive power of GNNs with RNI, and pose the following question: are GNNs with RNI more expressive than GNNs? We prove that this is indeed the case, by showing that GNNs with RNI are universal, a first such result for GNNs not relying on computationally demanding higher-order properties. We then empirically analyze the effect of RNI on GNNs, based on carefully constructed datasets. Our empirical findings support the superior performance of GNNs with RNI over standard GNNs. In fact, we demonstrate that the performance of GNNs with RNI is often comparable with or better than that of higher-order GNNs, while keeping the much lower memory requirements of standard GNNs. However, this improvement typically comes at the cost of slower model convergence. Somewhat surprisingly, we found that the convergence rate and the accuracy of the models can be improved by using only a partial random initialization regime.
BoxE: A Box Embedding Model for Knowledge Base Completion
Jul 13, 2020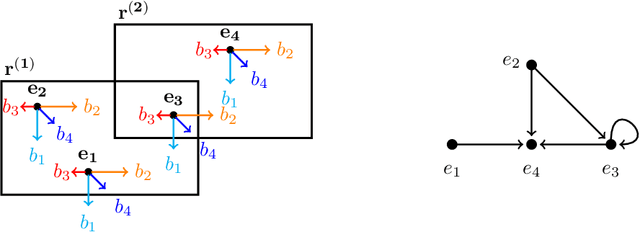

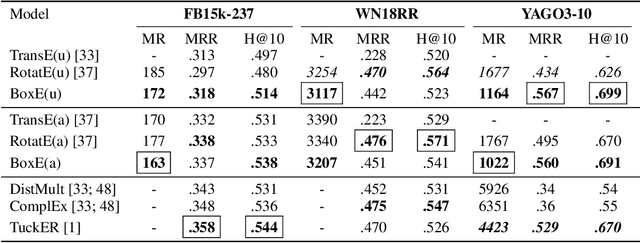

Knowledge base completion (KBC) aims to automatically infer missing facts by exploiting information already present in a knowledge base (KB). A promising approach for KBC is to embed knowledge into latent spaces and make predictions from learned embeddings. However, existing embedding models are subject to at least one of the following limitations: (1) theoretical inexpressivity, (2) lack of support for prominent inference patterns (e.g., hierarchies), (3) lack of support for KBC over higher-arity relations, and (4) lack of support for incorporating logical rules. Here, we propose a spatio-translational embedding model, called BoxE, that simultaneously addresses all these limitations. BoxE embeds entities as points, and relations as a set of hyper-rectangles (or boxes), which spatially characterize basic logical properties. This seemingly simple abstraction yields a fully expressive model offering a natural encoding for many desired logical properties. BoxE can both capture and inject rules from rich classes of rule languages, going well beyond individual inference patterns. By design, BoxE naturally applies to higher-arity KBs. We conduct a detailed experimental analysis, and show that BoxE achieves state-of-the-art performance, both on benchmark knowledge graphs and on more general KBs, and we empirically show the power of integrating logical rules.