 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Agreement: Rethinking Ground Truth in Educational AI Annotation
Jul 31, 2025Humans can be notoriously imperfect evaluators. They are often biased, unreliable, and unfit to define "ground truth." Yet, given the surging need to produce large amounts of training data in educational applications using AI, traditional inter-rater reliability (IRR) metrics like Cohen's kappa remain central to validating labeled data. IRR remains a cornerstone of many machine learning pipelines for educational data. Take, for example, the classification of tutors' moves in dialogues or labeling open responses in machine-graded assessments. This position paper argues that overreliance on human IRR as a gatekeeper for annotation quality hampers progress in classifying data in ways that are valid and predictive in relation to improving learning. To address this issue, we highlight five examples of complementary evaluation methods, such as multi-label annotation schemes, expert-based approaches, and close-the-loop validity. We argue that these approaches are in a better position to produce training data and subsequent models that produce improved student learning and more actionable insights than IRR approaches alone. We also emphasize the importance of external validity, for example, by establishing a procedure of validating tutor moves and demonstrating that it works across many categories of tutor actions (e.g., providing hints). We call on the field to rethink annotation quality and ground truth--prioritizing validity and educational impact over consensus alone.
Augmenting Human-Annotated Training Data with Large Language Model Generation and Distillation in Open-Response Assessment
Jan 15, 2025


Large Language Models (LLMs) like GPT-4o can help automate text classification tasks at low cost and scale. However, there are major concerns about the validity and reliability of LLM outputs. By contrast, human coding is generally more reliable but expensive to procure at scale. In this study, we propose a hybrid solution to leverage the strengths of both. We combine human-coded data and synthetic LLM-produced data to fine-tune a classical machine learning classifier, distilling both into a smaller BERT model. We evaluate our method on a human-coded test set as a validity measure for LLM output quality. In three experiments, we systematically vary LLM-generated samples' size, variety, and consistency, informed by best practices in LLM tuning. Our findings indicate that augmenting datasets with synthetic samples improves classifier performance, with optimal results achieved at an 80% synthetic to 20% human-coded data ratio. Lower temperature settings of 0.3, corresponding to less variability in LLM generations, produced more stable improvements but also limited model learning from augmented samples. In contrast, higher temperature settings (0.7 and above) introduced greater variability in performance estimates and, at times, lower performance. Hence, LLMs may produce more uniform output that classifiers overfit to earlier or produce more diverse output that runs the risk of deteriorating model performance through information irrelevant to the prediction task. Filtering out inconsistent synthetic samples did not enhance performance. We conclude that integrating human and LLM-generated data to improve text classification models in assessment offers a scalable solution that leverages both the accuracy of human coding and the variety of LLM outputs.
Do Tutors Learn from Equity Training and Can Generative AI Assess It?
Dec 15, 2024



Equity is a core concern of learning analytics. However, applications that teach and assess equity skills, particularly at scale are lacking, often due to barriers in evaluating language. Advances in generative AI via large language models (LLMs) are being used in a wide range of applications, with this present work assessing its use in the equity domain. We evaluate tutor performance within an online lesson on enhancing tutors' skills when responding to students in potentially inequitable situations. We apply a mixed-method approach to analyze the performance of 81 undergraduate remote tutors. We find marginally significant learning gains with increases in tutors' self-reported confidence in their knowledge in responding to middle school students experiencing possible inequities from pretest to posttest. Both GPT-4o and GPT-4-turbo demonstrate proficiency in assessing tutors ability to predict and explain the best approach. Balancing performance, efficiency, and cost, we determine that few-shot learning using GPT-4o is the preferred model. This work makes available a dataset of lesson log data, tutor responses, rubrics for human annotation, and generative AI prompts. Future work involves leveling the difficulty among scenarios and enhancing LLM prompts for large-scale grading and assessment.
Does Multiple Choice Have a Future in the Age of Generative AI? A Posttest-only RCT
Dec 13, 2024



The role of multiple-choice questions (MCQs) as effective learning tools has been debated in past research. While MCQs are widely used due to their ease in grading, open response questions are increasingly used for instruction, given advances in large language models (LLMs) for automated grading. This study evaluates MCQs effectiveness relative to open-response questions, both individually and in combination, on learning. These activities are embedded within six tutor lessons on advocacy. Using a posttest-only randomized control design, we compare the performance of 234 tutors (790 lesson completions) across three conditions: MCQ only, open response only, and a combination of both. We find no significant learning differences across conditions at posttest, but tutors in the MCQ condition took significantly less time to complete instruction. These findings suggest that MCQs are as effective, and more efficient, than open response tasks for learning when practice time is limited. To further enhance efficiency, we autograded open responses using GPT-4o and GPT-4-turbo. GPT models demonstrate proficiency for purposes of low-stakes assessment, though further research is needed for broader use. This study contributes a dataset of lesson log data, human annotation rubrics, and LLM prompts to promote transparency and reproducibility.
How Can I Get It Right? Using GPT to Rephrase Incorrect Trainee Responses
May 02, 2024



One-on-one tutoring is widely acknowledged as an effective instructional method, conditioned on qualified tutors. However, the high demand for qualified tutors remains a challenge, often necessitating the training of novice tutors (i.e., trainees) to ensure effective tutoring. Research suggests that providing timely explanatory feedback can facilitate the training process for trainees. However, it presents challenges due to the time-consuming nature of assessing trainee performance by human experts. Inspired by the recent advancements of large language models (LLMs), our study employed the GPT-4 model to build an explanatory feedback system. This system identifies trainees' responses in binary form (i.e., correct/incorrect) and automatically provides template-based feedback with responses appropriately rephrased by the GPT-4 model. We conducted our study on 410 responses from trainees across three training lessons: Giving Effective Praise, Reacting to Errors, and Determining What Students Know. Our findings indicate that: 1) using a few-shot approach, the GPT-4 model effectively identifies correct/incorrect trainees' responses from three training lessons with an average F1 score of 0.84 and an AUC score of 0.85; and 2) using the few-shot approach, the GPT-4 model adeptly rephrases incorrect trainees' responses into desired responses, achieving performance comparable to that of human experts.
How Can I Improve? Using GPT to Highlight the Desired and Undesired Parts of Open-ended Responses
May 01, 2024
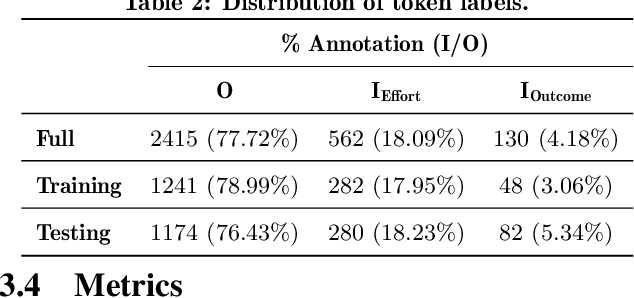
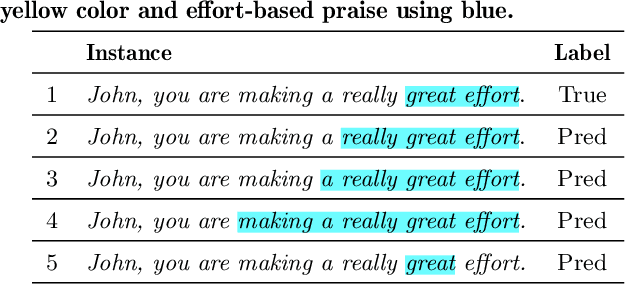
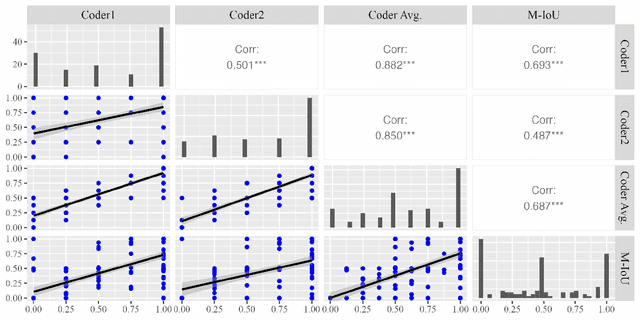
Automated explanatory feedback systems play a crucial role in facilitating learning for a large cohort of learners by offering feedback that incorporates explanations, significantly enhancing the learning process. However, delivering such explanatory feedback in real-time poses challenges, particularly when high classification accuracy for domain-specific, nuanced responses is essential. Our study leverages the capabilities of large language models, specifically Generative Pre-Trained Transformers (GPT), to explore a sequence labeling approach focused on identifying components of desired and less desired praise for providing explanatory feedback within a tutor training dataset. Our aim is to equip tutors with actionable, explanatory feedback during online training lessons. To investigate the potential of GPT models for providing the explanatory feedback, we employed two commonly-used approaches: prompting and fine-tuning. To quantify the quality of highlighted praise components identified by GPT models, we introduced a Modified Intersection over Union (M-IoU) score. Our findings demonstrate that: (1) the M-IoU score effectively correlates with human judgment in evaluating sequence quality; (2) using two-shot prompting on GPT-3.5 resulted in decent performance in recognizing effort-based (M-IoU of 0.46) and outcome-based praise (M-IoU of 0.68); and (3) our optimally fine-tuned GPT-3.5 model achieved M-IoU scores of 0.64 for effort-based praise and 0.84 for outcome-based praise, aligning with the satisfaction levels evaluated by human coders. Our results show promise for using GPT models to provide feedback that focuses on specific elements in their open-ended responses that are desirable or could use improvement.
Comparative Analysis of GPT-4 and Human Graders in Evaluating Praise Given to Students in Synthetic Dialogues
Jul 05, 2023


Research suggests that providing specific and timely feedback to human tutors enhances their performance. However, it presents challenges due to the time-consuming nature of assessing tutor performance by human evaluators. Large language models, such as the AI-chatbot ChatGPT, hold potential for offering constructive feedback to tutors in practical settings. Nevertheless, the accuracy of AI-generated feedback remains uncertain, with scant research investigating the ability of models like ChatGPT to deliver effective feedback. In this work-in-progress, we evaluate 30 dialogues generated by GPT-4 in a tutor-student setting. We use two different prompting approaches, the zero-shot chain of thought and the few-shot chain of thought, to identify specific components of effective praise based on five criteria. These approaches are then compared to the results of human graders for accuracy. Our goal is to assess the extent to which GPT-4 can accurately identify each praise criterion. We found that both zero-shot and few-shot chain of thought approaches yield comparable results. GPT-4 performs moderately well in identifying instances when the tutor offers specific and immediate praise. However, GPT-4 underperforms in identifying the tutor's ability to deliver sincere praise, particularly in the zero-shot prompting scenario where examples of sincere tutor praise statements were not provided. Future work will focus on enhancing prompt engineering, developing a more general tutoring rubric, and evaluating our method using real-life tutoring dialogues.
Using Large Language Models to Provide Explanatory Feedback to Human Tutors
Jun 27, 2023
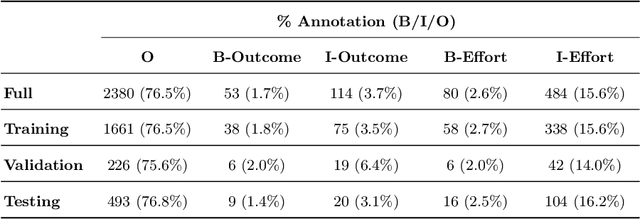

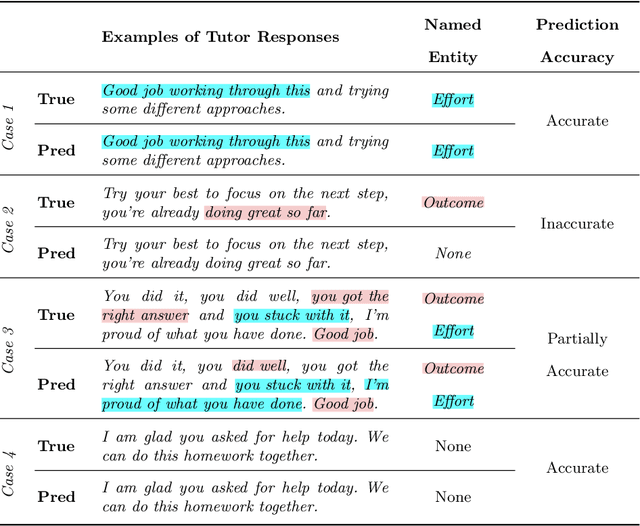
Research demonstrates learners engaging in the process of producing explanations to support their reasoning, can have a positive impact on learning. However, providing learners real-time explanatory feedback often presents challenges related to classification accuracy, particularly in domain-specific environments, containing situationally complex and nuanced responses. We present two approaches for supplying tutors real-time feedback within an online lesson on how to give students effective praise. This work-in-progress demonstrates considerable accuracy in binary classification for corrective feedback of effective, or effort-based (F1 score = 0.811), and ineffective, or outcome-based (F1 score = 0.350), praise responses. More notably, we introduce progress towards an enhanced approach of providing explanatory feedback using large language model-facilitated named entity recognition, which can provide tutors feedback, not only while engaging in lessons, but can potentially suggest real-time tutor moves. Future work involves leveraging large language models for data augmentation to improve accuracy, while also developing an explanatory feedback interface.